词法分析程序(Lexical Analyzer)要求:
- 从左至右扫描构成源程序的字符流
- 识别出有词法意义的单词(Lexemes)
- 返回单词记录(单词类别,单词本身)
- 滤掉空格
- 跳过注释
- 发现词法错误
程序结构:
输入:字符流(什么输入方式,什么数据结构保存)
处理:
–遍历(什么遍历方式)
–词法规则
输出:单词流(什么输出形式)
–二元组
单词类别:
1.标识符(10)
2.无符号数(11)
3.保留字(一词一码)
4.运算符(一词一码)
5.界符(一词一码)
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
: |
17 |
|
if |
2 |
:= |
18 |
|
then |
3 |
< |
20 |
|
while |
4 |
<= |
21 |
|
do |
5 |
<> |
22 |
|
end |
6 |
> |
23 |
|
l(l|d)* |
10 |
>= |
24 |
|
dd* |
11 |
= |
25 |
|
+ |
13 |
; |
26 |
|
- |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct{
int key;
char *value;
}CIZU;
CIZU cizu[1024];
int main(){
FILE *fp;
char buf[1024];
char a[1024];
char b[1024];
char seps[]="
";
char *token=NULL;
char *next_token=NULL;
int h=0,q=0;
if((fp=fopen("代码.txt","ab+"))==NULL){
printf("File open error!
");
exit(0);
}
while(fgets(buf,2, fp) != NULL){
a[h]=buf[0];
h++;
}
token = strtok_r(a,seps,&next_token);
while(token!=NULL){
if(token!=NULL){
if(strcmp(token,"int")==0){
cizu[q].key=7;
cizu[q].value="标识符 int";
}else if(strcmp(token,"beigin")==0){
cizu[q].key=1;
cizu[q].value="标识符 begin";
}else if(strcmp(token,"main")==0){
cizu[q].key=39;
cizu[q].value="标识符 main";
}else if(strcmp(token,"if")==0){
cizu[q].key=2;
cizu[q].value="标识符 if";
}else if(strcmp(token,"then")==0){
cizu[q].key=3;
cizu[q].value="标识符 then";
}else if(strcmp(token,"while")==0){
cizu[q].key=4;
cizu[q].value="标识符 while";
}else if(strcmp(token,"do")==0){
cizu[q].key=5;
cizu[q].value="标识符 do";
}else if(strcmp(token,"end")==0){
cizu[q].key=6;
cizu[q].value="标识符 end";
}else if(strcmp(token,"#")==0){
cizu[q].key=0;
cizu[q].value="#";
}else if(strcmp(token,"h")==0){
cizu[q].key=104;
cizu[q].value="h";
}else if(strcmp(token,"(")==0){
cizu[q].key=40;
cizu[q].value="(";
}else if(strcmp(token,")")==0){
cizu[q].key=41;
cizu[q].value=")";
}else if(strcmp(token,":")==0){
cizu[q].key=58;
cizu[q].value=":";
}else if(strcmp(token,"printf")==0){
cizu[q].key=30;
cizu[q].value="printf";
}else if(strcmp(token,";")==0){
cizu[q].key=59;
cizu[q].value=";";
}else if(strcmp(token,"scanf")==0){
cizu[q].key=31;
cizu[q].value="scanf";
}else if(strcmp(token,"[")==0){
cizu[q].key=32;
cizu[q].value="[";
}else if(strcmp(token,"]")==0){
cizu[q].key=33;
cizu[q].value="]";
}else if(strcmp(token,"{")==0){
cizu[q].key=34;
cizu[q].value="{";
}else if(strcmp(token,"}")==0){
cizu[q].key=35;
cizu[q].value="}";
}else if(strcmp(token,"h")==0){
cizu[q].key=104;
cizu[q].value="h";
}else if(strcmp(token,"20")==0){
cizu[q].key=14;
cizu[q].value="20";
}else if(strcmp(token,"return")==0){
cizu[q].key=36;
cizu[q].value="return";
}else if(strcmp(token,"s")==0){
cizu[q].key=115;
cizu[q].value="s";
}else if(strcmp(token,"%")==0){
cizu[q].key=37;
cizu[q].value="%";
}else{
cizu[q].key=0;
cizu[q].value=token;
}
q++;
printf("%s
",token);
token=strtok_r(NULL,seps,&next_token);
}
}
printf("%d
",q);
for(int i=0;i<q;i++)
printf("<%d,%s>
",cizu[i].key,cizu[i].value);
if(fclose(fp)){
printf("Can not close the file!
");
exit(0);
}
}
文件txt:

运行结果:
先输出将文本分隔成一个个的单词:

再输出识别后的分类
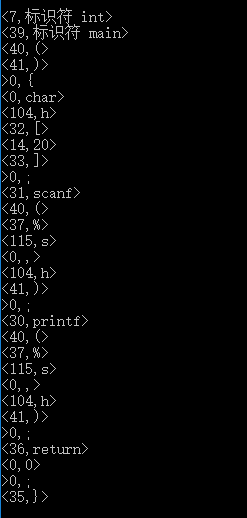
本次实验的效果没有预想的那么好,有时间的关系,也有对于c语言的不熟练的原因,希望继续努力,下次更好。