1.1 准备工作
首先要搭建K8S集群,请参考另一篇文档: https://www.cnblogs.com/taoweizhong/p/10467795.html
在此基础上,本文安装K8s dashboard、prometheus、grafana进行监控(注意上篇文档中一个虚拟机的IP地址和这里有不同,原因没有配置静态IP)。
本文中涉及容器的部署方式说明:
- K8s dashboard采用K8S集群管理的部署方式
- prometheus和grafana仅仅采用容器化部署,没有采用K8S集群管理的部署。
本文需要下载对应的镜像如下:
prom/prometheus latest
grafana/grafana latest
docker.io/siriuszg/kubernetes-dashboard-amd64 latest
docker.io/google/cadvisor v0.24.1(不知道为啥latest无法连接上prometheus)
quay.io/prometheus/node-exporter latest
本文组网如下图:

1.2 K8S Dashboard
K8S Dashboard是官方的一个基于WEB的用户界面(个人觉得比较简陋),专门用来管理K8S集群,并可展示集群的状态。K8S集群安装好后默认没有包含Dashboard,我们需要额外创建它,下面我们具体实现如何安装它。
第一步:查找镜像
[root@slave1 taoweizhong]# docker search dashboard
docker.io docker.io/siriuszg/kubernetes-dashboard-amd64
docker.io/siriuszg/kubernetes-dashboard-amd64 v1.5.1 be6763d992e0 2 years ago 104 MB
这里省略了其他类似镜像。
第二步:拉取镜像:
[root@slave1 taoweizhong]# docker pull docker.io/siriuszg/kubernetes-dashboard-amd64
第三步:编写脚本(这里dashboard采用K8S集群管理)
dashboard-service.yaml
[root@master democonfig]# cat dashboard-service.yaml
kind: Service
apiVersion: v1
metadata:
labels:
app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 80
targetPort: 9090
selector:
app: kubernetes-dashboard
[root@master democonfig]# cat kubernetes-dashboard.yaml
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
labels:
app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: kubernetes-dashboard
template:
metadata:
labels:
app: kubernetes-dashboard
annotations:
scheduler.alpha.kubernetes.io/tolerations: |
[
{
"key": "dedicated",
"operator": "Equal",
"value": "master",
"effect": "NoSchedule"
}
]
spec:
containers:
- name: kubernetes-dashboard
image: docker.io/siriuszg/kubernetes-dashboard-amd64:v1.5.1
imagePullPolicy: Always
ports:
- containerPort: 9090
protocol: TCP
args:
- --apiserver-host=http://192.168.135.128:8080
livenessProbe:
httpGet:
path: /
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
第四步:执行并部署
[root@master democonfig]# kubectl create -f kubernetes-dashboard.yaml
[root@master democonfig]# kubectl create -f dashboard-service.yaml
这里对应的删除脚本为:
[root@master democonfig]# kubectl delete -f kubernetes-dashboard.yaml
[root@master democonfig]# kubectl delete -f dashboard-service.yaml
第五步:访问Dashboard
先查询下容器是否启动:
[root@master democonfig]# kubectl get pods --all-namespaces -o wide

(注意这里是namespace为 kube-system,查询时需要增加命名空间)
打开浏览器并输入:
http://192.168.135.128:8080/ui 或者
http://192.168.135.128:8080/api/v1/proxy/namespaces/kube-system/services/kubernetes-dashboard/

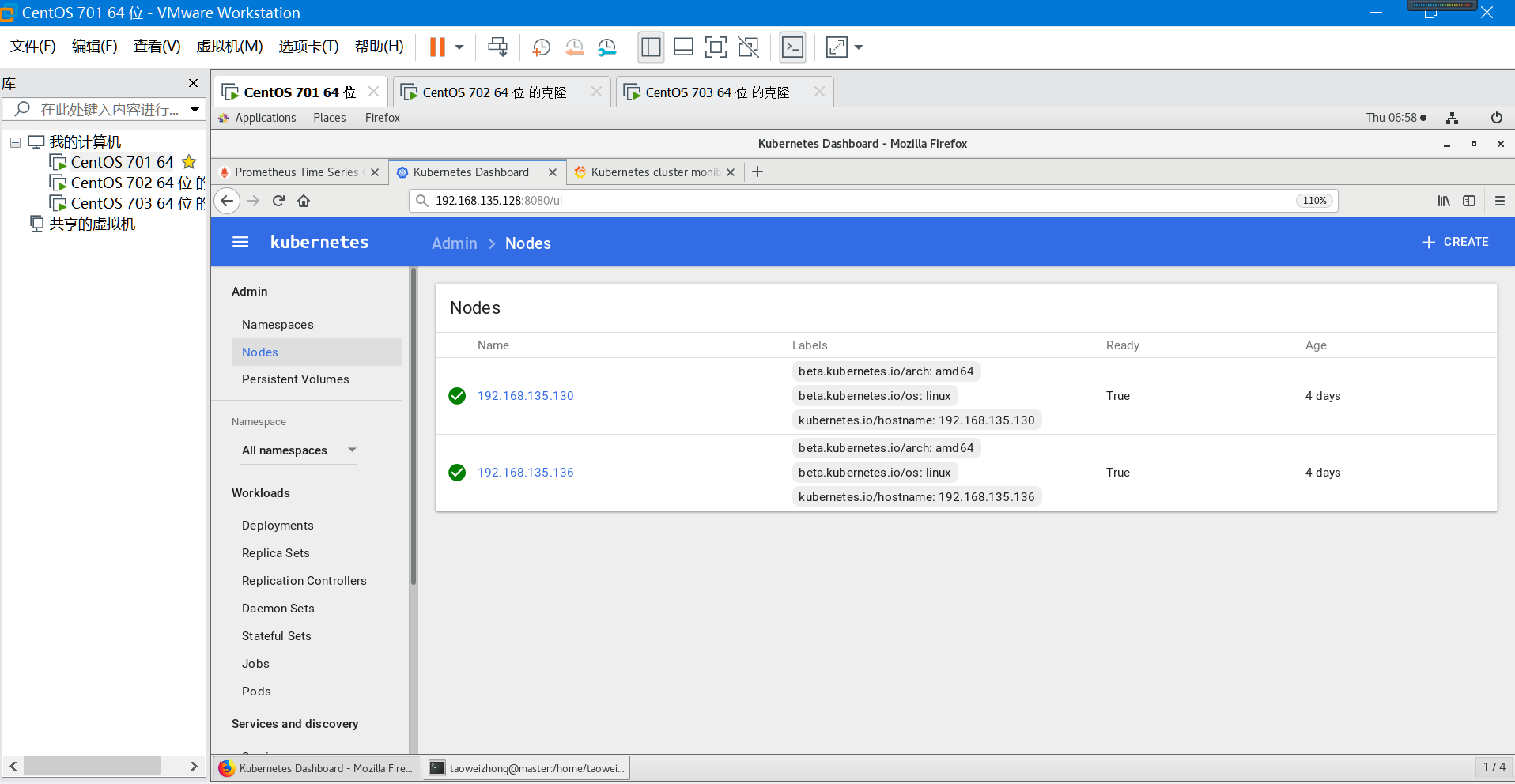
遇到的问题说明:
1.关闭iptables防火墙 (如果是防火墙原因导致的master节点无法ping通node之上的Pod节点)
systemctl stop iptables
systemctl disable iptables
即使关闭了防火墙跨主机间容器、pod始终无法ping通
这是由于linux还有底层的iptables,所以在node上分别执行:
iptables -P INPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -F
iptables -L -n
2.由于关闭或者重启docker而导致的网络未更新问题引起。
Master节点启动 注意先启动kubernetes,再启动docker(如果是关闭docker或者重启docker导致的网络问题,重启master和node节点,注意重启顺序)
主Master节点重启顺序
systemctl enable docker
systemctl enable etcd kube-apiserver kube-scheduler kube-controller-manager
systemctl restart etcd kube-apiserver kube-scheduler kube-controller-manager
systemctl restart flanneld docker
Node从节点重启顺序
systemctl restart kubelet kube-proxy
systemctl restart flanneld docker
systemctl enable flanneld kubelet kube-proxy docker
1.3 Prometheus安装
Prometheus 是由 SoundCloud 开发的开源监控报警系统和时序列数据库(TSDB),自2012年起,许多公司及组织已经采用 Prometheus,该项目有着非常活跃的开发者和用户社区,现在已成为一个独立的开源项目核。
其工作流程是:Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。在图形界面中,可视化采集数据。
Prometheus 中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。
metric 名字:该名字应该具有语义,一般用于表示 metric 的功能,例如:http_requests_total, 表示 http 请求的总数。
标签:使同一个时间序列有了不同维度的识别。例如 http_requests_total{method="Get"} 表示所有 http 请求中的 Get 请求。当 method="post" 时,则为新的一个 metric。
样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
格式:<metric name>{<label name>=<label value>, …},例如:http_requests_total{method="POST",endpoint="/api/tracks"}。
下面介绍其安装步骤(这里直接采用容器化安装,非基于K8S集群管理安装,因此在K8S的pods中看不到):
【步骤1到4在master节点安装】
第一步:查找镜像
[root@master prometheus]# docker search prometheus
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
prom/prometheus 692 [OK]
第二步:拉取镜像
[root@master prometheus]# docker pull prom/prometheus
第三步编写:prometheus.yml文件
root@master prometheus-1.7.1.linux-amd64]# cat prometheus.yml
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['192.168.135.128:9090']
- job_name: 'kubernetes-nodes-cadvisor'
kubernetes_sd_configs:
- api_server: 'http://192.168.135.128:8080'
role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_role]
action: replace
target_label: kubernetes_role
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:8080'
target_label: __address__
- job_name: 'kubernetes_node'
kubernetes_sd_configs:
- role: node
api_server: 'http://192.168.135.128:8080'
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
说明:一个典型的配置格式
global:
# 抓取间隔,默认为 1m
[ scrape_interval: <duration> | default = 1m ]
# 抓取超时时间,默认为 10s
[ scrape_timeout: <duration> | default = 10s ]
# 规则评估间隔,默认为 1m
[ evaluation_interval: <duration> | default = 1m ]
# 抓取配置
scrape_configs:
[ - <scrape_config> ... ]
# 规则配置
rule_files:
[ - <filepath_glob> ... ]
# 告警配置
alerting:
alert_relabel_configs:
[ - <relabel_config> ... ]
alertmanagers:
[ - <alertmanager_config> ... ]
第四步:启动镜像
[root@master prometheus]# docker run -d -p 9090:9090 --name=prometheus -v /home/taoweizhong/data/prometheus/prometheus-1.7.1.linux-amd64/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
由于是容器化安装, 这里需要注意虚拟机上编写的prometheus.yml 文件位置,否则会启动错误。
【步骤5到7需要每个slave节点上都需要安装】
在下面的步骤开始之前先了解下:
Prometheus提供的NodeExporter项目可以提取主机节点的关键度量指标,通过Kubernetes的DeamonSet模式可以在各主机节点上部署一个NodeExporter实例,实现对主机性能指标数据的监控。
Cadvisor Google用来监测单节点的资源信息的监控工具,提供了一目了然的单节点多容器的资源监控功能。Google的Kubernetes中也缺省地将其作为单节点的资源监控工具,各个节点缺省会被安装上Cadvisor。总结起来主要两点:展示 Host 和容器两个层次的监控数据;展示历史变化数据。
由于 cAdvisor 提供的操作界面简陋,且需要在不同页面之间跳转,只能监控一个 host。但 cAdvisor 的一个亮点是它可以将监控到的数据导出给第三方工具,由这些工具进一步加工处理。我们可以把 cAdvisor 定位为一个监控数据收集器,收集和导出数据是它的强项,而非展示数据。
第五步:拉取cadvisor和node-exporter镜像
[root@slave1 taoweizhong]# docker pull docker.io/google/cadvisor
[root@slave1 taoweizhong]# docker pull quay.io/prometheus/node-exporter:v0.24.1
注意这里拉取node-exporter的是:v0.24.1版本,latest不知为啥无法和Prometheus集成起来。
第六步:启动cadvisor和node-exporter镜像
[root@slave1 taoweizhong]#docker run -d -p 9100:9100 -v "/proc:/host/proc" -v "/sys:/host/sys" -v "/:/rootfs" --net=host quay.io/prometheus/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
[root@slave1 taoweizhong]#docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --privileged=true --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --name=cadvisor --restart=always google/cadvisor:v0.24.1
这里参数不做具体说明了,这两个容器的目的是在slave节点采集数据给Prometheus
第七步:检查镜像启动状态
![]()
第八步:先查看下cadvisor 和node-exporter在http端口提供的指标项
在浏览器中输入:http://192.168.135.136:9100/metrics
(注意:IP地址为部署容器的宿主机,端口是容器映射到虚拟机上的端口) node-exporter返回的指标如下,有很多指标:

在浏览器中输入:http://192.168.135.136:8080/metrics
(注意:IP地址为部署容器的宿主机,端口是容器映射到虚拟机上的端口)cadvisor返回的指标如下,有很多指标:

第九步:查看cadvisor 的简陋图形界面:
cAdvisor 会显示当前 host 的资源使用情况,包括 CPU、内存、网络、文件系统等。


第十步:访问prometheus图形界面:
在运行后,访问 http://192.168.135.128:9090/graph (IP地址是prometheus容器所在宿主机,端口是启动时候指定的映射到虚拟机端口)
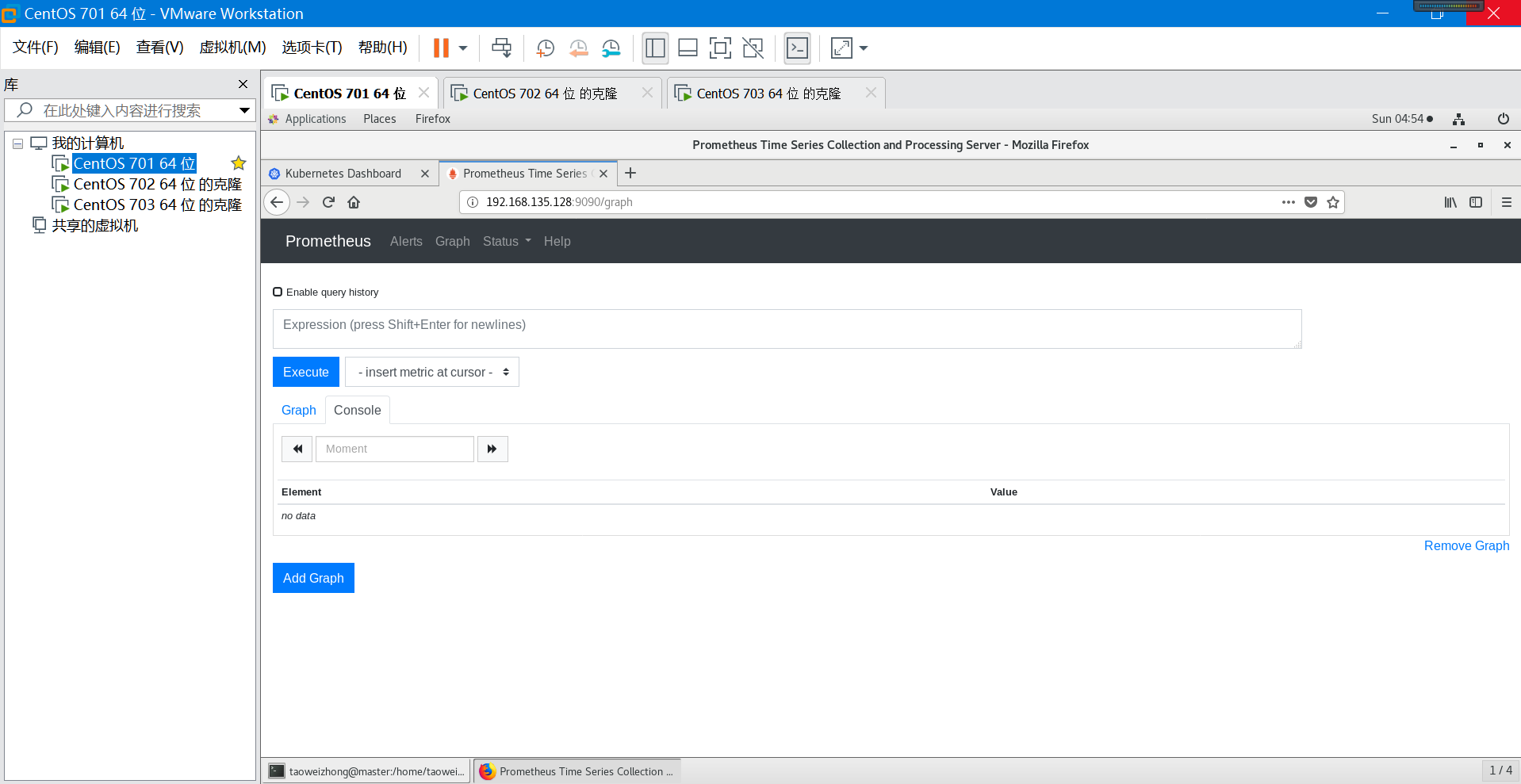
第十一步:切换到target(从菜单status->Targets),这样Prometheus的安装就成功了,我们可以看到EndPoint已经连接正常UP,如果这里状态为down,表示连接不正常,需要查看原因,可能是防火墙之类的。

由于Grafana提供了很漂亮的图形界面,下面我们将Prometheus和Grafana集成起来。
1.4 Grafana安装
Grafana是一个开源的度量分析与可视化套件。经常被用作基础设施的时间序列数据和应用程序分析的可视化。Grafana支持许多不同的数据源。每个数据源都有一个特定的查询编辑器,该编辑器定制的特性和功能是公开的特定数据来源。 官方支持以下数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB。
基本概念说明:
Data Source:grafana确切的说是一个前端展示工具,将数据以非常美观直接的图形展示出来。那么这些数据必须有一个来源吧,grafana获取数据的地方就称为Data Source。
DashBoard:仪表盘,就像汽车仪表盘一样可以展示很多信息,包括车速,水箱温度等。Grafana的DashBoard就是以各种图形的方式来展示从Datasource拿到的数据。
Row:DashBoard的基本组成单元,一个DashBoard可以包含很多个row。一个row可以展示一种信息或者多种信息的组合,比如系统内存使用率,CPU五分钟及十分钟平均负载等。所以在一个DashBoard上可以集中展示很多内容。
Panel:面板,实际上就是row展示信息的方式,支持表格(table),列表(alert list),热图(Heatmap)等多种方式,具体可以去官网上查阅。
Query Editor:用来指定获取哪一部分数据。类似于sql查询语句,比如你要在某个row里面展示test这张表的数据,那么Query Editor里面就可以写成select *from test。
Organization:org是一个很大的概念,每个用户可以拥有多个org,grafana有一个默认的main org。用户登录后可以在不同的org之间切换,前提是该用户拥有多个org。不同的org之间完全不一样,包括datasource,dashboard等都不一样。
User:这个概念应该很简单,不用多说。Grafana里面用户有三种角色admin,editor,viewer。admin权限最高,可以执行任何操作,包括创建用户,新增Datasource,创建DashBoard。editor角色不可以创建用户,不可以新增Datasource,可以创建DashBoard。viewer角色仅可以查看DashBoard。在2.1版本及之后新增了一种角色read only editor(只读编辑模式),这种模式允许用户修改DashBoard,但是不允许保存。每个user可以拥有多个organization。
这里我采用容器化部署,但是grafana容器并没有纳入K8S管理范围,因此安装后使用kubectl get pod命令是查找不到的,具体操作如下:
第一步:查找镜像
[root@master prometheus-1.7.1.linux-amd64]# docker search grafana
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
grafana/grafana The official Grafana docker container 1084
【这里省略了一部分镜像列表】
第二步:下载镜像
[root@master prometheus-1.7.1.linux-amd64]# docker pull grafana/Grafana
第三步:启动镜像
[root@master prometheus-1.7.1.linux-amd64]# docker run -d --name grafana -p 3000:3000 grafana/grafana Grafana
d68d28806b435bee1cce00745820be92dc3f39353e3aabf6c72eb5ab15a0b652
注意端口映射到3000,后续访问需要
第四步:浏览界面
在浏览器打开 http://192.168.135.128:3000 (这里是虚拟机的IP地址),输入默认用户名密码 (admin/admin) 可以进入 Grafana 。

第五步:数据源配置
Configuration - Data Resource - Add Data Resource
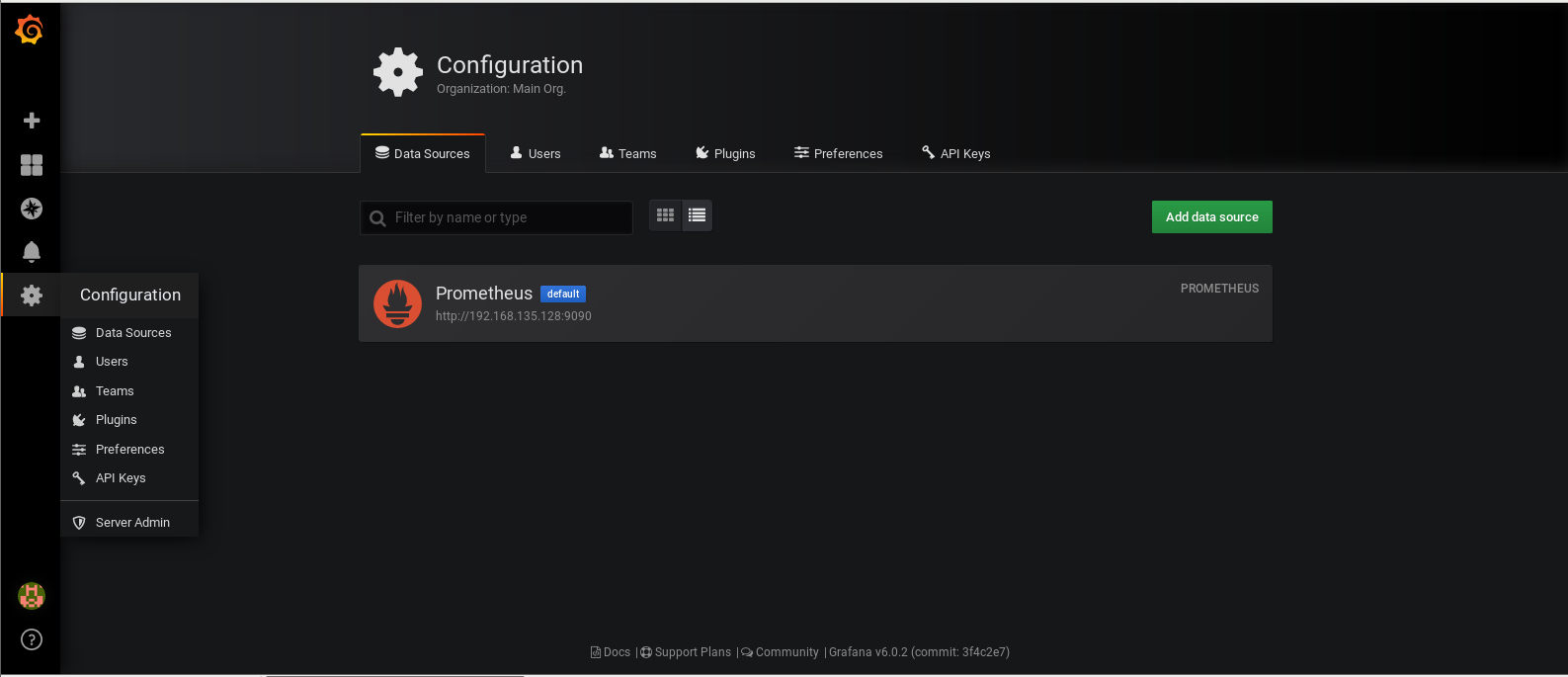
编辑数据源,输入正确的URL:

第六步:选择Prometheus2.0的dashboard(默认已经安装),这样我们就可以看到漂亮的监控界面了。

下面我们演示如何更换换一个dashboard:
grafana可以支持根据自己的需求手动新建一个 Dashboard, grafana 的官方网站上有很多公共的 Dashboard 可以供使用,我们这里可以使用(dashboard id 为315)这个 Dashboard 来展示 Kubernetes 集群的监控信息:
第一步:先下载下来,地址如下
https://grafana.com/dashboards/315/revisions

第二步:在左侧侧边栏 Create 中点击import导入,将上面第一个输入框输入315,下面文本框直接将下载的文件内容复制到里面,点击load

第三步:选择prometheus这个名字的数据源,执行import操作,就可以进入到 dashboard 页面:

第四步:这样就可以看到结果了(下面截图供参考学习)

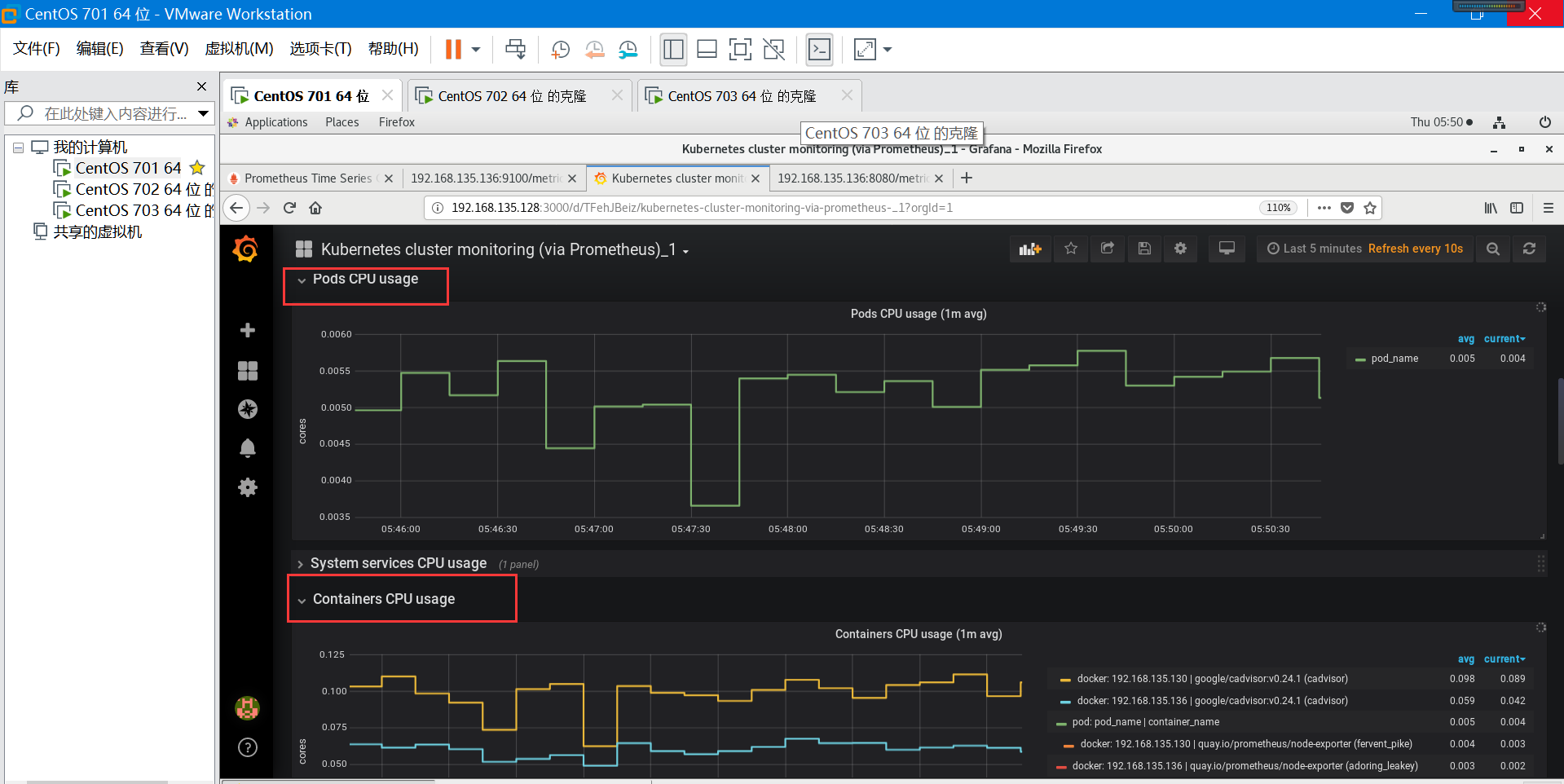

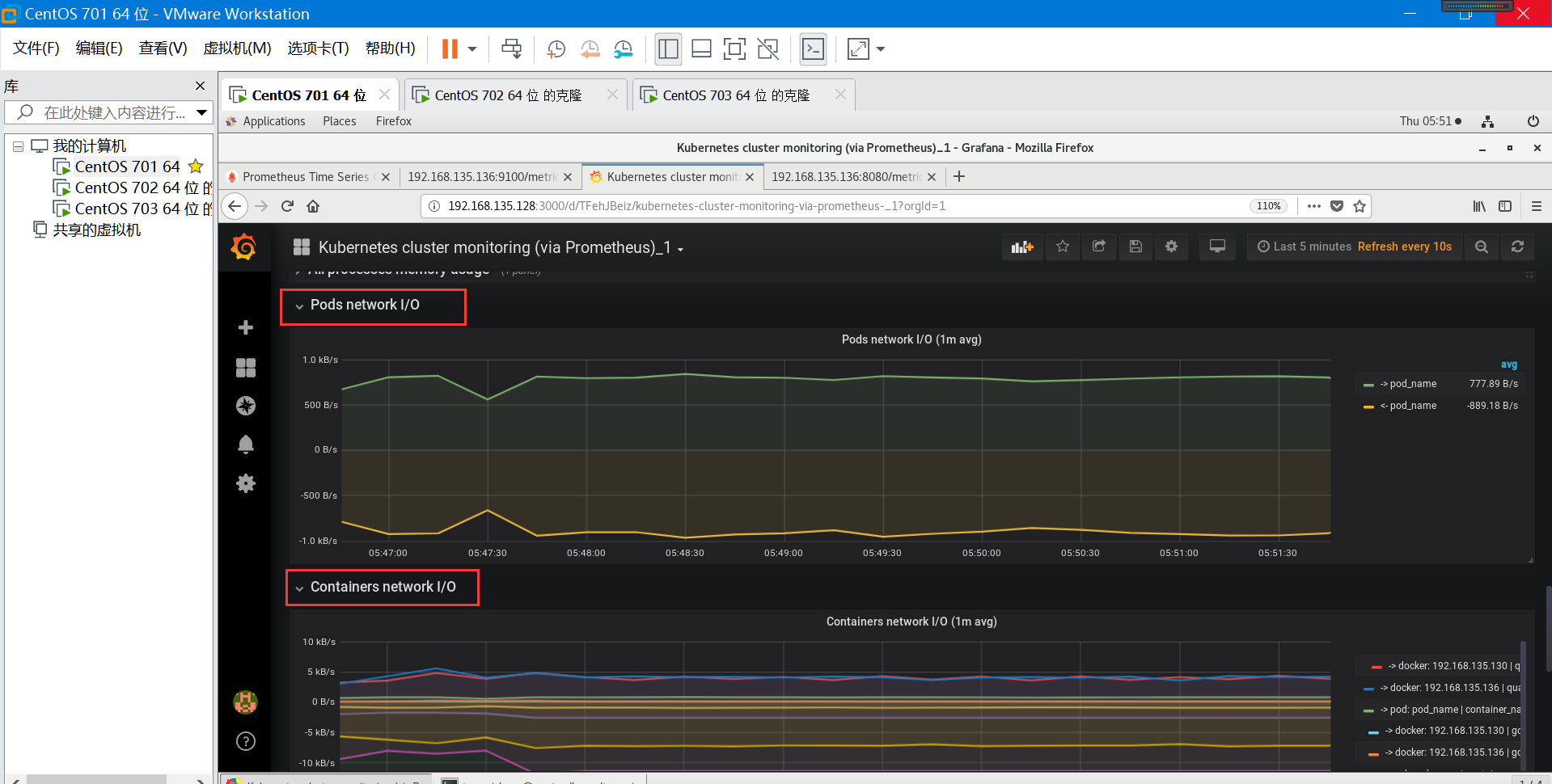
--结束---