什么是布隆过滤器
1970年,由布隆提出来的一个用于判断元素是否在集合中的高效的算法,集合中的元素可以增加,但是要删除一个元素比较困难,同时还有少量的误报率。
在数据量比较小的时候,我们可以使用 Hash 来判断元素是否命中,但是当元素增加起来后,Hash 算法需要的空间就会急速增长,查找时间也会增加。布隆过滤器主要用在样本集合量大但是很少有删除元素,不要求 100%100% 正确率的场景下。例如:网页黑名单、垃圾邮件过滤、爬虫URL去重 等。
布隆过滤器原理
爬虫URL去重
初始条件
-
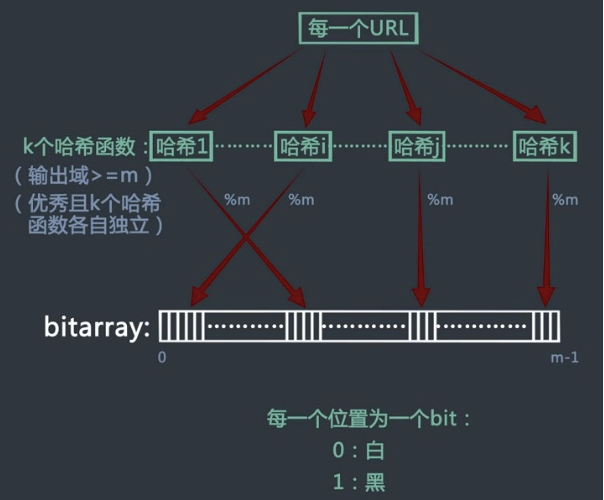
设数据集合 A=a1,a2,….,anA=a1,a2,….,an,含 nn 个 urlurl 记为 ai(i∈[1,n])ai(i∈[1,n]),作为待操作的集合。
-
Bloom Filter用一个长度为 mm 的位向量 bitarraybitarray 表示的集合中的元素,位向量初始值全为 00。 -
kk 个优秀且各自独立的哈希函数 H1,H2,….,HkH1,H2,….,Hk,且输出域应 ≥m≥m。
加入url的处理
- 首先经过 kk 个散列函数产生 kk 个随机数 h1,h2,……hk,接着对 mm 取模得到 h‘ihi‘,使向量 bitarraybitarray 的相应位置 h1‘,h2‘,……hk‘ 均置为 11。集合中其他 urlurl 也通过类似的操作,将向量 bitarraybitarray 的若干位置为 11。
检查是否重复
- 首先将该元素经过上步中类似操作,获得 kk 个随机数 h1‘,h2‘,……hk‘ ,然后查看向量 bitarraybitarray 的相应位置上的值,若全为 11,则该元素已经在之前的集合中;若至少有一个 00 存在,表明,此元素不在之前的集合中,为新元素。
执行示意图
算法特点
- 对于已经在集合中的元素,通过上述中的查找方法,一定可以判定该元素在集合中。
- 对于不在集合中的元素,可能会被误判在集合中。
布隆过滤器的选择与质量评估
确定布隆过滤器的长度 mm
设样本个数为 nn,允许的错误率为 pp,则,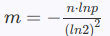
确定哈希函数的个数 kk
根据已求得的 mm,可得,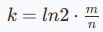
计算真实失误率
根据向上取整的 m、n、km、n、k,可求得,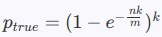
Python实现布隆过滤器
安装PyBloom
Python中有多个实现 BloomFilter 的包详情可以自己搜索Pypi,本文中主要介绍 PyBloom,可以通过 pip 进行安装。
pip install pybloom
也可以直接去作者的github上下载源码编译安装。
python setup.py install
PyBloom源码解析
pybloom主要包括两个类:BloomFilter和ScalableBloomFilter。
BloomFilter 是一个定容的过滤器,errorrateerrorrate 是指最大的误报率是 0.1%,而 ScalableBloomFilter是一个不定容量的布隆过滤器,它可以不断添加元素。add 方法是添加元素,如果元素已经在布隆过滤器中,就返回 True,如果不在返回 Fasle 并将该元素添加到过滤器中。判断一个元素是否在过滤器中,只需要使用 in运算符即可。
ScalableBloomFilter类
在ScalableBloomFilter的 add 方法中可以看到:

其本质依旧是创建了一个BloomFilter类。
BloomFilter类
在BloomFilter的 __init__ 函数中:

可以看到它引用了Python的bitarray库来实现布隆过滤器。
在BloomFilter的 add 方法中:
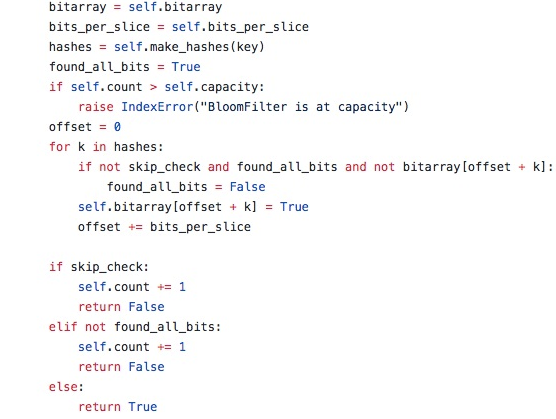
可以看到,我们可以通过设置 skipcheckskipcheck 的值来手动选择是否过滤当前元素,否则就根据算出的 kk 个 Hash 函数的值所对应的位是否都为 11 来确定元素是否存在,存在则返回 True,否则返回 False。
PyBloom的使用
使用BloomFilter
from pybloom import BloomFilter bf = BloomFilter(capacity=10000, error_rate=0.001) bf.add('test-bf') print 'test-bf' in bf
True
使用ScalableBloomFilter
from pybloom import ScalableBloomFilter sbf = ScalableBloomFilter(mode=ScalableBloomFilter.SMALL_SET_GROWTH) sbf.add('test-sbf') print 'sbf' in sbf False