原文链接:http://tecdat.cn/?p=5725
神经网络是一种基于现有数据创建预测的计算系统。
如何构建神经网络?
神经网络包括:
- 输入图层:根据现有数据获取输入的图层
- 隐藏图层:使用反向传播优化输入变量权重的图层,以提高模型的预测能力
- 输出图层:基于输入和隐藏图层的数据输出预测


用神经网络解决分类问题
在这个特定的例子中,我们的目标是开发一个神经网络来确定股票是否支付股息。
因此,我们使用神经网络来解决分类问题。通过分类,我们指的是按类别对数据进行分类的分类。例如,水果可分为苹果,香蕉,橙等。
我们的自变量如下:
- fcfps:每股自由现金流量(以美元计)
- income_growth:过去一年的盈利增长(%)
- de:债务与权益比率
- mcap:股票的市值
- current_ratio:流动比率(或流动资产/流动负债)
我们首先设置目录并将数据加载到R环境中:
setwd(
setwd("your directory")
attach(mydata)“你的目录”)
数据规范化形成神经网络时最重要的过程之一是数据标准化。这涉及将数据调整到共同的比例,以便准确地比较预测值和实际值。无法对数据进行标准化通常会导致所有观察结果中的预测值保持不变,而与输入值无关。
我们在下面实现了这两种技术,但选择使用max-min规范化技术。
缩放标准化
scaleddata <-scale(mydata)
最大最小标准化
对于此方法,我们调用以下函数来规范化我们的数据:
normalize < - function(x){
return((x - min(x))/(max(x) - min(x)))
} 然后,我们使用lapply在我们现有的数据上运行该函数(我们将数据集称为加载到R中的数据集为mydata):
我们现在已经缩放了我们的新数据集并将其保存到名为maxmindf的数据框中: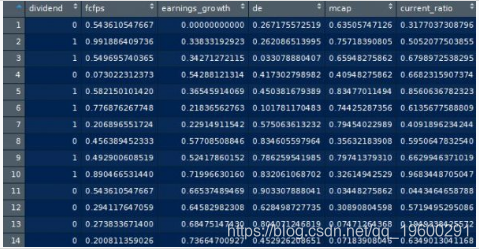
![]()
我们的训练数据(训练集)基于80%的观测值。测试数据(测试集)基于剩余的20%的观察结果。
#训练和测试数据训练集
trainset <- maxmindf[1:160, ]
testset <- maxmindf[161:200, ]用神经网络训练神经网络模型
我们现在将神经网络库加载到R.
使用神经网络将依赖的“红利”变量“回归” 到其他自变量
- 根据hidden =(2,1)公式将隐藏层数设置为(2,1)
- 给定自变量对因变量(被除数)的影响假设是非线性的,linear.output变量设置为FALSE
- 阈值设置为0.01,这意味着如果迭代期间的误差变化小于1%,则模型不会进行进一步的优化
确定神经网络中隐藏层的数量并不是一门精确的科学。事实上,有些情况下,没有任何隐藏层,准确度可能会更高。因此,反复试验在这一过程中起着重要作用。
一种可能性是比较预测的准确性如何随着我们修改隐藏层的数量而改变。例如,对于该示例,使用(2,1)配置最终产生92.5%的分类准确度。
nn $ result .matrix
plot(nn)我们的神经网络看起来像这样: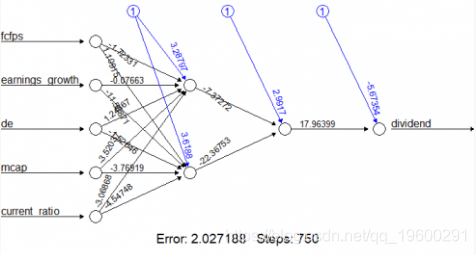
![]()
我们现在生成神经网络模型的误差,以及输入,隐藏层和输出之间的权重:
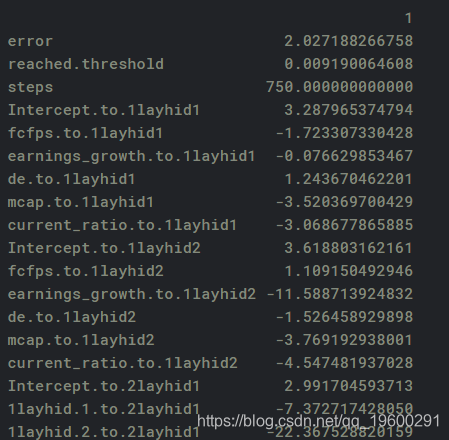
![]()
测试模型的准确性
如前所述,我们的神经网络是使用训练数据创建的。然后,我们将其与测试数据进行比较,以评估神经网络预测的准确性。
temp_test < - subset(testset,select = c(“fcfps”,“earnings_growth”,“de”,“mcap”,“current_ratio”)) head(temp_test) nn.results < - compute(nn, temp_test)
结果< - data.frame(actual = testset $ dividend,prediction = nn.results $ net.result)将预测结果与实际结果进行比较:
0.999985252611
混乱矩阵
然后,我们使用sapply对结果进行舍入,并创建一个混淆矩阵来比较真/假阳性和阴性的数量:
table(actual,prediction) prediction
actual 0 1
0 17 0
1 3 20
混淆矩阵用于确定由我们的预测生成的真实和误报的数量。该模型生成17个真阴性(0),20个真阳性(1),而有3个假阴性。
最终,我们在确定股票是否支付股息时产生92.5%(37/40)的准确率。
使用神经网络解决回归问题
在这个例子中,我们希望分析解释变量容量,汽油和小时数对因变量消耗的影响。
数据规范化
同样,我们将数据标准化并分为训练和测试数据:
#MAX-MIN NORMALIZATION
normalize < - function(x){
}
#TRAINING AND TEST DATA
trainset < - maxmindf [1:32,]
testset < - maxmindf [33:40,] 神经网络输出
然后我们运行我们的神经网络并生成我们的参数:
Intercept.to.1layhid1 1.401987575173
capacity.to.1layhid1 1.307794013481
gasoline.to.1layhid1 -3.102267882386
hours.to.1layhid1 -3.246720660493
Intercept.to.1layhid2 -0.897276576566
capacity.to.1layhid2 -1.934594889387
gasoline.to。 1layhid2 3.739470402932
hours.to.1layhid2 1.973830465259
Intercept.to.2layhid1 -1.125920206855
1layhid.1.to.2layhid1 3.175227041522
1layhid.2.to.2layhid1 -2.419360506652
Intercept.to.consumption 0.683726702522
2layhid.1.to.consumption -0.545431580477 生成神经网络
以下是我们的神经网络在视觉格式中的样子:
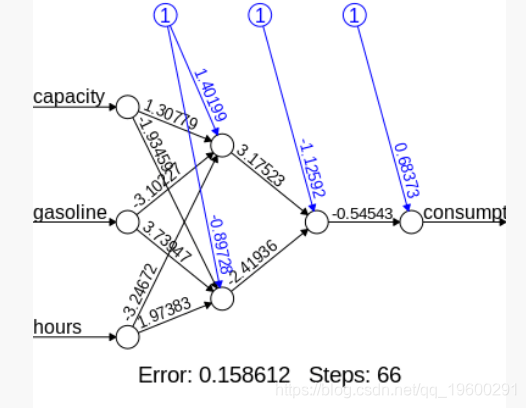
![]()
模型验证
然后,我们通过比较从神经网络产生的估计汽油消耗与测试输出中报告的实际支出来验证(或测试我们模型的准确性):
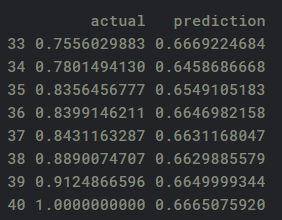
![]()
准确性
在下面的代码中,我们然后将数据转换回其原始格式,并且在平均绝对偏差的基础上产生90%的准确度(即估计和实际汽油消耗之间的平均偏差平均为10%)。请注意,我们还将数据转换回标准值,因为它们之前使用max-min标准化技术进行了缩放:
predicted=results$prediction * abs(diff(range(consumption))) + min(consumption)
accuracy![]()
![]()
可以看到我们使用(2,1)隐藏配置获得90%的准确率。这非常好,特别是考虑到我们的因变量是区间格式。但是,让我们看看我们是否可以让它更高!
如果我们现在在神经网络中使用(5,2)隐藏配置会发生什么?这是生成的输出:
我们看到我们的准确率现已增加到近96%,表明修改隐藏节点的数量已经增强了我们的模型!