
原文链接: http://tecdat.cn/?p=14121
本文将分析了几种用于制定保险费率的平滑技术。
该价格应与纯溢价相关,而纯溢价与频率成正比,因为
没有协变量,预期频率应为
-
-
-
Deviance Residuals:
-
Min 1Q Median 3Q Max
-
-0.5033 -0.3719 -0.2588 -0.1376 13.2700
-
-
Coefficients:
-
Estimate Std. Error z value Pr(>|z|)
-
(Intercept) -2.6201 0.0228 -114.9 <2e-16 ***
-
---
-
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
-
-
(Dispersion parameter for poisson family taken to be 1)
-
-
Null deviance: 12680 on 49999 degrees of freedom
-
Residual deviance: 12680 on 49999 degrees of freedom
-
AIC: 16353
-
-
Number of Fisher Scoring iterations: 6
-
> exp(coefficients(regglm0))
-
(Intercept)
-
0.07279295
因此,如果我们不想考虑到潜在的异质性,通常将其视为百分比,即概率,因为
![]()
即可以解释为没有索赔的可能性。让我们将其可视化为驾驶员年龄的函数,
-
-
-
-
-
-
> plot(a,yp0,type="l",ylim=c(.03,.12))
-
-
-
-
-
-
> segments(a[k],yp1[k],a[k],yp2[k],col="red",lwd=3)
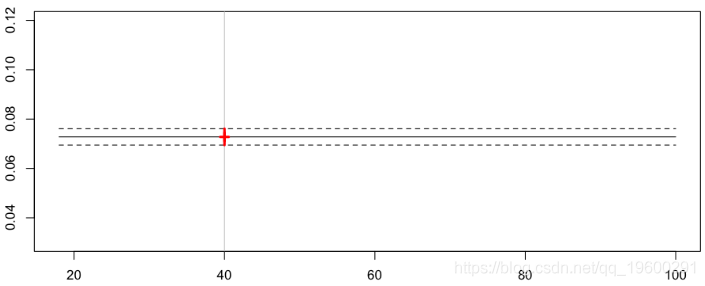
我们确实会为所有驾驶员预测相同的频率,例如对于40岁的驾驶员,
-
> cat("Frequency =",yp0[k]," confidence interval",yp1[k],yp2[k])
-
Frequency = 0.07279295 confidence interval 0.07611196 0.06947393
现在我们考虑一种情况,其中我们尝试考虑异质性,例如按年龄,
- (标准)泊松回归
在(对数)泊松回归的想法是假设而不是的,我们应该有
,其中
在这里,让我们只考虑一个解释变量,即
我们有
-
-
-
-
-
-
> plot(a,yp0,type="l",ylim=c(.03,.12))
-
> abline(v=40,col="grey")
-
> lines(a,yp1,lty=2)
-
> lines(a,yp2,lty=2)
-
> points(a[k],yp0[k],pch=3,lwd=3,col="red")
-
> segments(a[k],yp1[k],a[k],yp2[k],col="red",lwd=3)
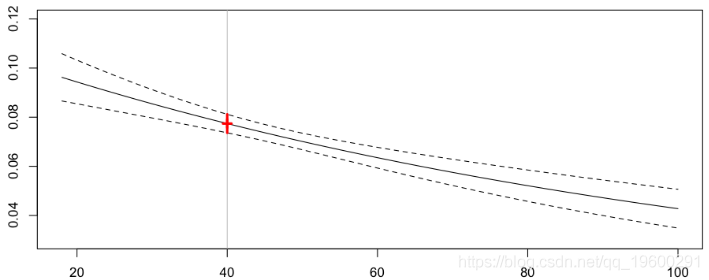
对于我们40岁的驾驶员的年化索赔频率的预测现在为7.74%(比我们之前的7.28%略高)
-
> cat("Frequency =",yp0[k]," confidence interval",yp1[k],yp2[k])
-
Frequency = 0.07740574 confidence interval 0.08117512 0.07363636
不计算预期频率,而是计算比率。
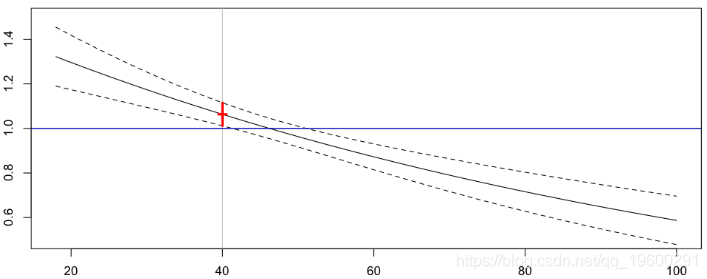
在水平蓝线上方,溢价将高于未分段的溢价,而低于此水平。在这里,年龄小于44岁的驾驶员将支付更多的费用,而年龄大于44岁的驾驶员将支付较少的费用。在引言中,我们讨论了分段的必要性。如果我们考虑两家公司,一个细分市场,而另一个细分市场持平,那么年长的司机将去第一家公司(因为保险更便宜),而年轻的司机将去第二家公司(同样,它更便宜)。问题在于,第二家公司暗中希望老司机能弥补这一风险。但是由于它们已经不存在了,所以保险价格会太便宜了,公司也会放宽资金(如果没有破产的话)。因此,公司必须使用细分技术才能生存。现在,问题在于,我们不能确定溢价的这种指数衰减是溢价随年龄变化的正确方法。一种替代方法是使用非参数技术来可视化年龄对索赔频率的真实影响。
- 纯非参数模型
第一个模型可以是考虑每个年龄的保费。可以考虑将驾驶员的年龄作为回归因素,
-
-
-
-
-
-
-
> plot(a0,yp0,type="l",ylim=c(.03,.12))
-
> abline(v=40,col="grey")
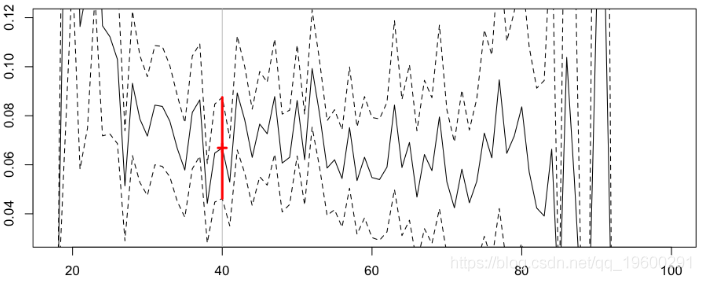
在这里,我们40岁司机的预测略低于前一个,但置信区间要大得多(因为我们关注的是投资组合中很小的一类:年龄恰好在 40 岁的司机)
Frequency = 0.06686658 confidence interval 0.08750205 0.0462311在这里,我们认为类别太小,溢价也太不稳定了:溢价将从40岁到41岁下降20%,然后从41岁到42岁上升50%。
-
> diff(log(yp0[23:25]))
-
24 25
-
-0.2330241 0.5223478
公司没有机会采用这种策略来确保被保险人。保费的这种不连续性是这里的重要问题。
- 使用年龄段
另一种选择是考虑年龄段,从非常年轻的驾驶员到高级驾驶员。
-
-
-
-
-
> summary(regglmc1)
-
-
Coefficients:
-
Estimate Std. Error z value Pr(>|z|)
-
(Intercept) -1.6036 0.1741 -9.212 < 2e-16 ***
-
cut(ageconducteur, level1)(20,25] -0.4200 0.1948 -2.157 0.0310 *
-
cut(ageconducteur, level1)(25,30] -0.9378 0.1903 -4.927 8.33e-07 ***
-
cut(ageconducteur, level1)(30,35] -1.0030 0.1869 -5.367 8.02e-08 ***
-
cut(ageconducteur, level1)(35,40] -1.0779 0.1866 -5.776 7.65e-09 ***
-
cut(ageconducteur, level1)(40,45] -1.0264 0.1858 -5.526 3.28e-08 ***
-
cut(ageconducteur, level1)(45,50] -0.9978 0.1856 -5.377 7.58e-08 ***
-
cut(ageconducteur, level1)(50,55] -1.0137 0.1855 -5.464 4.65e-08 ***
-
cut(ageconducteur, level1)(55,60] -1.2036 0.1939 -6.207 5.40e-10 ***
-
cut(ageconducteur, level1)(60,65] -1.1411 0.2008 -5.684 1.31e-08 ***
-
cut(ageconducteur, level1)(65,70] -1.2114 0.2085 -5.811 6.22e-09 ***
-
cut(ageconducteur, level1)(70,75] -1.3285 0.2210 -6.012 1.83e-09 ***
-
cut(ageconducteur, level1)(75,80] -0.9814 0.2271 -4.321 1.55e-05 ***
-
cut(ageconducteur, level1)(80,85] -1.4782 0.3371 -4.385 1.16e-05 ***
-
cut(ageconducteur, level1)(85,90] -1.2120 0.5294 -2.289 0.0221 *
-
cut(ageconducteur, level1)(90,95] -0.9728 1.0150 -0.958 0.3379
-
cut(ageconducteur, level1)(95,100] -11.4694 144.2817 -0.079 0.9366
-
---
-
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
-
-
-
-
-
-
-
-
-
> lines(a,yp1,lty=2,type="s")
-
> lines(a,yp2,lty=2,type="s")
在这里,我们获得以下预测,
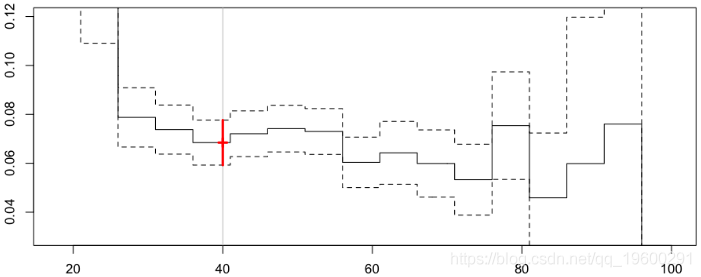
对于我们40岁的驾驶员来说,现在的频率为6.84%。
Frequency = 0.0684573 confidence interval 0.07766717 0.05924742我们应该考虑其他类别,以查看预测是否对值敏感,
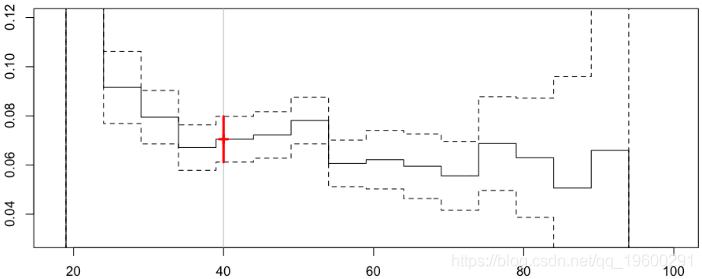
对于我们40岁的司机来说,得出以下值:
Frequency = 0.07050614 confidence interval 0.07980422 0.06120807所以在这里,我们没有消除不连续性问题。这里的一个想法是考虑移动区域:如果目标是预测40岁驾驶员的频率,则应该以40为中心。而对于35岁的驾驶员,间隔应该以35为中心。
- 移动平均
因此,考虑一些局部回归是很自然的,只应考虑年龄接近 40 岁的驾驶员。这几乎与带宽有关。例如,介于35和45之间的驱动程序可以被认为接近40。在实践中,我们可以考虑子集函数,也可以在回归中使用权重
-
> value=40
-
> h=5
-
-
-
要查看发生了什么,让我们考虑一个动画,感兴趣的年龄在不断变化,
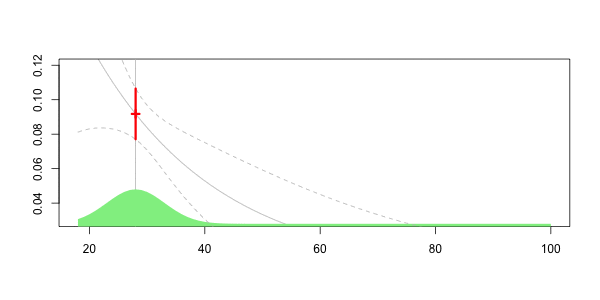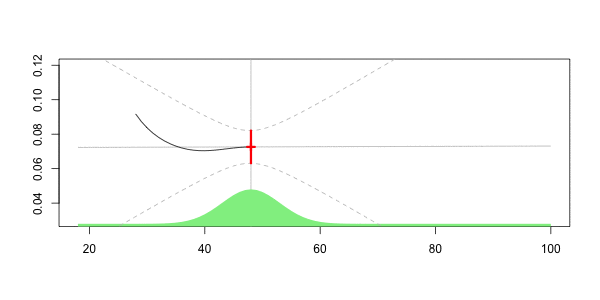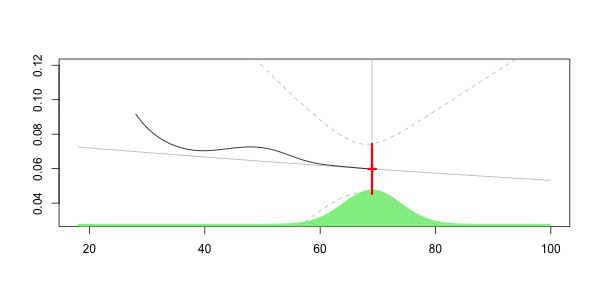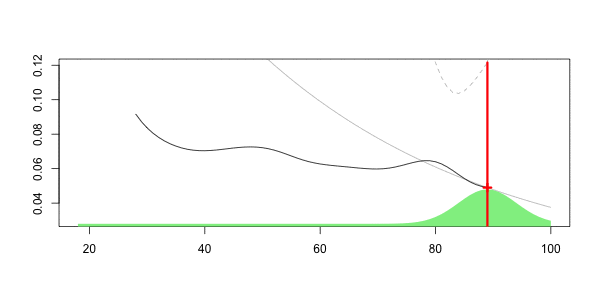
在这里,对于我们40岁的人来说,
Frequency = 0.06913391 confidence interval 0.07535564 0.06291218我们获得了可以解释为局部回归的曲线。但是在这里,我们没有考虑到35没有像39那样接近40。这里的34假设与40距离很远。显然,我们可以改进该技术:可以考虑内核函数,即,越接近40,权重就越大。
-
> value=40
-
> h=5
-
-
-
在下面绘制
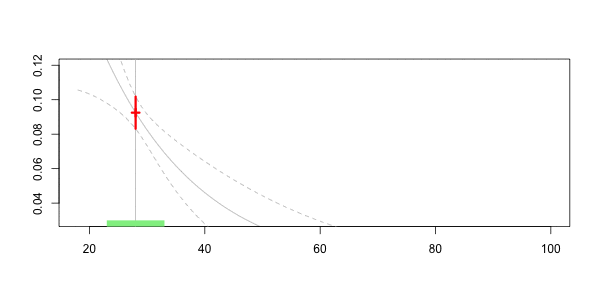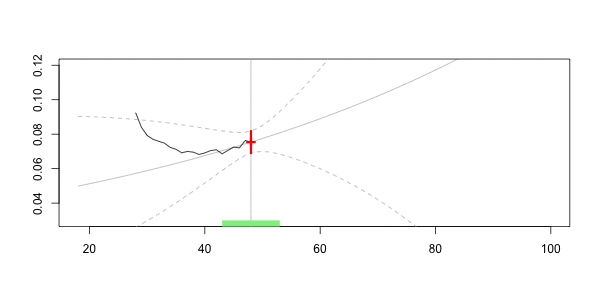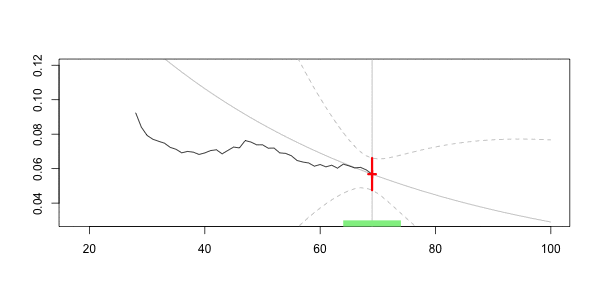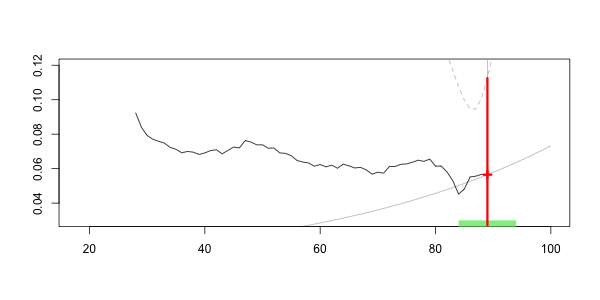
在这里,我们对40的预测是
Frequency = 0.07040464 confidence interval 0.07981521 0.06099408这就是核回归技术的思想。但是,如幻灯片中所述,可以考虑其他非参数技术,例如样条函数。
- 用样条平滑
在R中,使用样条函数很简单(某种程度上比内核平滑器简单得多)
-
> library(splines)
-
-
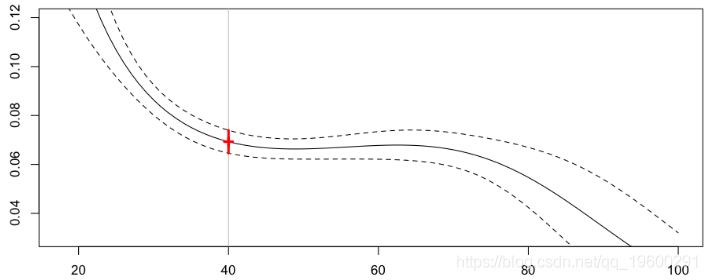
现在对我们40岁司机的预测是
Frequency = 0.06928169 confidence interval 0.07397124 0.06459215
请注意,此技术与另一类模型有关,即所谓的广义相加模型,即GAM。
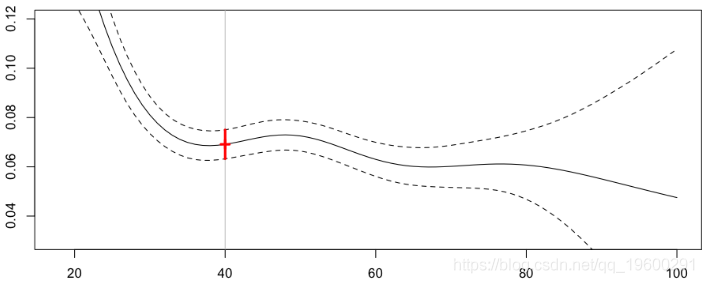
该预测与我们上面获得的预测非常接近(主要区别在于非常老的驾驶员)
Frequency = 0.06912683 confidence interval 0.07501663 0.06323702
- 不同模型的比较
无论哪种方式,所有这些模型都是有效的。所以也许我们应该比较它们,
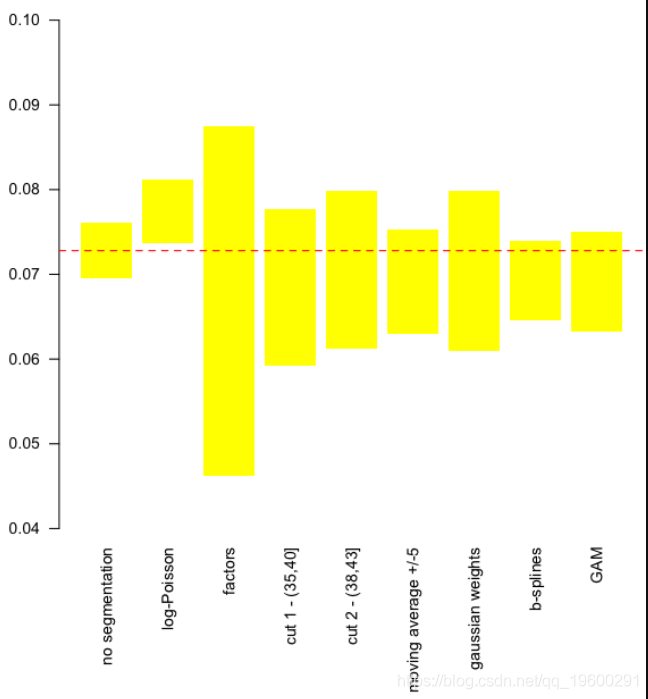
在上图中,我们可以可视化这9个模型的预测上限和下限。水平线是不考虑异质性的预测值。
参考文献
2.R语言线性判别分析(LDA),二次判别分析(QDA)和正则判别分析(RDA)
5.在r语言中使用GAM(广义相加模型)进行电力负荷时间序列分析
6.使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM