原文链接 :http://tecdat.cn/?p=19542
时间序列预测问题是预测建模问题中的一种困难类型。
与回归预测建模不同,时间序列还增加了输入变量之间序列依赖的复杂性。
用于处理序列依赖性的强大神经网络称为 递归神经网络。长短期记忆网络或LSTM网络是深度学习中使用的一种递归神经网络,可以成功地训练非常大的体系结构。
在本文中,您将发现如何使用Keras深度学习库在Python中开发LSTM网络,以解决时间序列预测问题。
完成本教程后,您将知道如何针对自己的时间序列预测问题实现和开发LSTM网络。
- 关于国际航空公司的旅客时间序列预测问题。
- 如何基于时间序列预测问题框架开发LSTM网络。
- 如何使用LSTM网络进行开发并做出预测,这些网络可以在很长的序列中保持状态(内存)。
在本教程中,我们将为时间序列预测问题开发LSTM。
这些示例将准确地向您展示如何开发结构不同的LSTM网络,以解决时间序列预测建模问题。
问题描述
讨论的问题是国际航空公司的乘客预测问题。
任务是预测国际航空旅客的数量。数据范围为1949年1月至1960年12月,即12年,共进行了144次观测。
下面是文件前几行的示例。
-
"Month","Passengers"
-
-
-
"1949-03",132
-
-
"1949-04",129
-
-
"1949-05",121
我们可以使用Pandas库加载此数据集。下面列出了加载和绘制数据集的代码。
-
-
-
-
dataset = pandas.read_csv('airpas.csv', usecols=[1], engine='python')
-
-
plt.plot(dataset)
-
-
plt.show()
-
-
您可以看到数据集中随时间的上升趋势。
您还可以看到数据集中的一些周期性,该周期性可能对应于休假期。
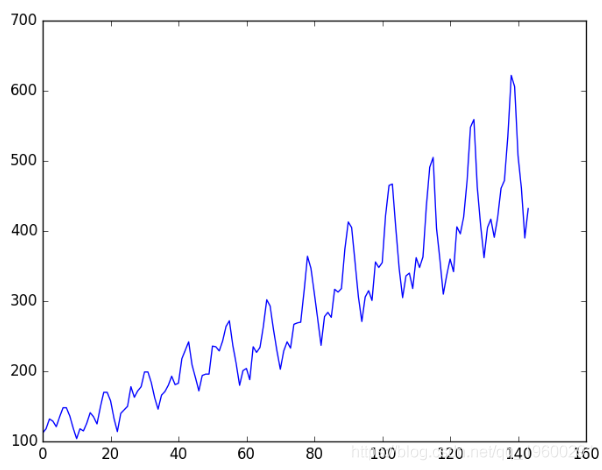
通常,最好标准化数据并使它们平稳。
长短期记忆网络
长短期记忆网络(LSTM)是一种递归神经网络,使用时间反向传播进行训练,可以解决梯度消失的问题。
它可用于创建大型循环网络,进而可用于解决机器学习中的序列问题并获得最新结果。
LSTM网络不是神经元,而是具有通过层连接的存储块。
LSTM 的关键就是细胞状态,LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法,他们包含一个sigmoid神经网络层和一个按位的乘法操作。Sigmoid 层输出0到1之间的数值,描述每个部分有多少量可以通过。0代表“不许任何量通过”,1就指“允许任意量通过”!LSTM 拥有三个门,来保护和控制细胞状态。
一个单元内有三种类型的门:
- 忘记门:有条件地决定从该块中丢弃哪些信息。
- 输入门:有条件地决定输入中的哪些值来更新内存状态。
- 输出门:根据输入的内存,决定输出什么。
每个单元就像一个微型状态机,其中单元的门具有在训练过程中学习到的权重。
LSTM回归网络
我们可以将该问题表述为回归问题。
也就是说,考虑到本月的旅客人数(以千为单位),下个月的旅客人数是多少?
我们可以编写一个简单的函数将单列数据转换为两列数据集:第一列包含本月的(t)乘客数,第二列包含下个月的(t + 1)乘客数。
在开始之前,让我们首先导入要使用的所有函数和类。假设安装了Keras深度学习库。
在进行任何操作之前,最好先设置随机数种子,以确保我们的结果可重复。
-
# 随机种子以提高可重复性
-
-
numpy.random.seed(7)
我们还可以使用上一部分中的代码将数据集作为Pandas数据框加载。然后,我们可以从数据帧中提取NumPy数组,并将整数值转换为浮点值,这更适合使用神经网络进行建模。
-
# 加载数据集
-
-
-
dataset = dataset.astype('float32')
LSTM对输入数据的大小敏感,特别是在使用S型(默认)或tanh激活函数时。将数据重新标准化到0到1的范围(也称为归一化)。我们可以使用 scikit-learn库中的MinMaxScaler预处理类轻松地对数据集进行规范化 。
-
# 标准化数据集
-
-
scaler = MinMaxScaler(feature_range=(0, 1))
-
-
dataset = scaler.fit_transform(dataset)
在对数据进行建模并在训练数据集上估计模型之后,我们需要对新的数据测试了解模型的技能。对于正常的分类或回归问题,我们将使用交叉验证来完成。
对于时间序列数据,值的顺序很重要。我们可以使用的一种简单方法是将有序数据集拆分为训练数据集和测试数据集。下面的代码计算分割点,并使用67%的观测值将数据分离到训练数据集中,这些观测值可用于训练模型,其余的33%用于测试模型。
-
# 分为训练集和测试集
-
-
train_size = int(len(dataset) * 0.67)
-
-
test_size = len(dataset) - train_size
-
现在,我们可以定义一个函数来创建新的数据集,如上所述。
该函数有两个参数: 数据集(我们要转换为数据集的NumPy数组)和 look_back,这是用作输入变量以预测下一个时间段的先前时间步数,默认为1。
此默认值将创建一个数据集,其中X是给定时间(t)的乘客人数,Y是下一次时间(t +1)的乘客人数。
我们将在下一部分中构造一个形状不同的数据集。
-
# 将值数组转换为数据集矩阵
-
-
-
-
for i in range(len(dataset)-look_back-1):
-
-
a = dataset[i:(i+look_back), 0]
-
-
return numpy.array(dataX), numpy.array(dataY)
让我们看一下此函数对数据集第一行的影响。
-
X Y
-
-
112 118
-
-
118 132
-
-
132 129
-
-
129 121
-
-
121 135
如果将前5行与上一节中列出的原始数据集样本进行比较,则可以在数字中看到X = t和Y = t + 1模式。
让我们准备训练和测试数据集以进行建模。
-
#整理为X = t和Y = t + 1
-
-
look_back = 1
-
create_dataset(train, look_back)
LSTM网络输入数据(X)具有以下形式的特定数组结构: [样本,时间步长,特征]。
目前,我们的数据采用以下形式:[样本,特征],我们将问题定为每个样本的一步。我们可以使用numpy.reshape()将准备好的训练和测试输入数据转换为预期的结构 ,如下所示:
-
# 将输入修改为[样本,时间步长,特征]
-
-
numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
-
现在,我们准备设计并拟合我们的LSTM网络以解决此问题。
该网络具有一个具有1个输入的可见层,一个具有4个LSTM块或神经元的隐藏层以及一个进行单个值预测的输出层。默认的Sigmoid激活功能用于LSTM模块。该网络训练了100个时期。
-
# 创建并拟合LSTM网络
-
-
-
model.add(LSTM(4, input_shape=(1, look_back)))
-
-
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
一旦模型适合,我们就可以估计模型在训练和测试数据集上的性能。这将为我们提供新模型的比较点。
请注意,在计算误差之前,我们先对预测进行了反标准化,以确保以与原始数据相同的单位。
-
# 作出预测
-
-
trainPredict = model.predict(trainX)
-
-
-
# 反向预测
-
-
trainPredict = scaler.inverse_transform(trainPredict)
-
-
-
# 计算均方误差
-
-
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
最后,我们可以使用模型为训练和测试数据集生成预测,以直观地了解模型的技能。
由于数据集的准备方式,我们必须移动预测,以使它们在x轴上与原始数据集对齐。准备好之后,将数据绘制成图表,以蓝色显示原始数据集,以绿色显示训练数据集的预测,以红色显示看不见的测试数据集的预测。
-
# 预测
-
-
-
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
-
-
# 绘制测试预测
-
-
testPredictPlot = numpy.empty_like(dataset)
-
-
-
-
# 绘制基准和预测
-
-
-
-
plt.plot(testPredictPlot)
-
-
plt.show()
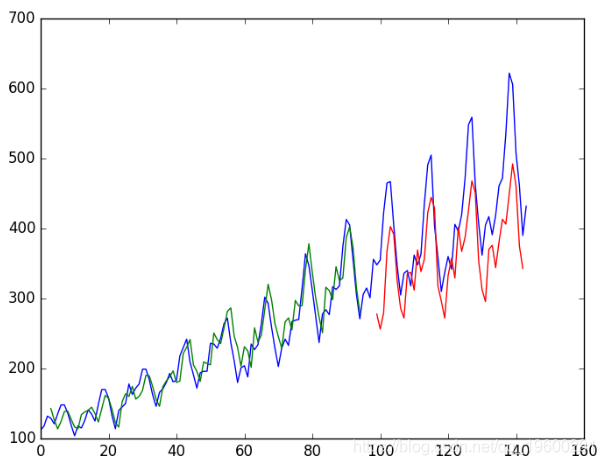
我们可以看到,该模型在拟合训练和测试数据集方面做得非常出色。
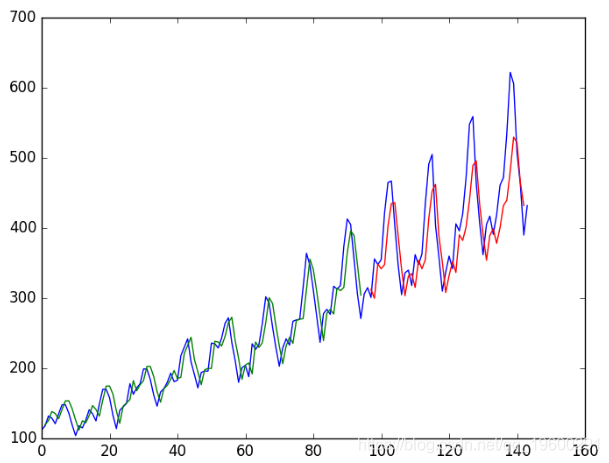
LSTM训练了旅客预测问题的回归公式
运行示例将产生以下输出。
-
..
-
-
-
-
-
Epoch 100/100
-
-
0s - loss: 0.0020
-
-
Train Score: 22.93 RMSE
-
-
Test Score: 47.53 RMSE
我们可以看到,该模型在训练数据集上的平均误差约为23乘客(以千计),在测试数据集上的平均误差为52乘客(以千计)。
使用窗口方法进行回归的LSTM
我们还可以使用多个最近的时间步长来预测下一个时间步长。
这称为窗口,窗口的大小是可以针对每个问题进行调整的参数。
例如,给定当前时间(t),我们要预测序列(t + 1)中下一个时间的值,我们可以使用当前时间(t)以及前两个时间(t-1)和t-2)作为输入变量。
当表述为回归问题时,输入变量为t-2,t-1,t,输出变量为t + 1。
在上一节中创建的 create_dataset()函数使我们可以通过将look_back 参数从1增加到3来创建时间序列问题。
具有此公式的数据集示例如下所示:
-
X1 X2 X3 Y
-
-
112 118 132 129
-
-
118 132 129 121
-
-
132 129 121 135
-
-
129 121 135 148
-
-
121 135 148 148
我们可以使用较大的窗口大小重新运行上一部分中的示例。
运行示例将提供以下输出:
-
...
-
-
-
Epoch 100/100
-
-
0s - loss: 0.0020
-
-
Train Score: 24.19 RMSE
-
-
Test Score: 58.03 RMSE
我们可以看到误差与上一节相比有所增加。
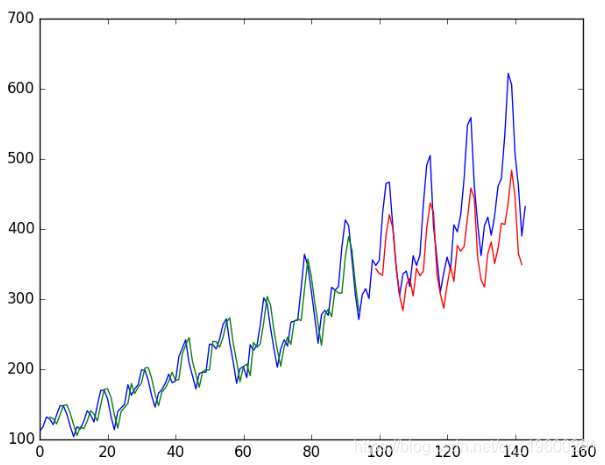
LSTM随时间步长回归
你可以看到LSTM网络的数据准备包括时间步长。
某些序列问题每个样本的时间步长可能不同。
时间步长为表达我们的时间序列问题提供了另一种方法。像上面的窗口示例一样,我们可以将时间序列中的先前时间作为输入,以预测下一时间的输出。
我们可以将它们用作一个输入函数的时间步长,而不是将过去的观察结果作为单独的输入函数,这确实是问题的更准确框架。
我们可以使用与上一个示例相同的数据表示方式来执行此操作,我们将列设置为时间步长维度,例如:
-
# 将输入修改为[样本,时间步长,特征]
-
-
numpy.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
-
运行示例将提供以下输出:
-
...
-
-
Epoch 95/100
-
-
1s - loss: 0.0021
-
-
Epoch 96/100
-
-
1s - loss: 0.0021
-
我们可以看到,结果比之前的示例略好。
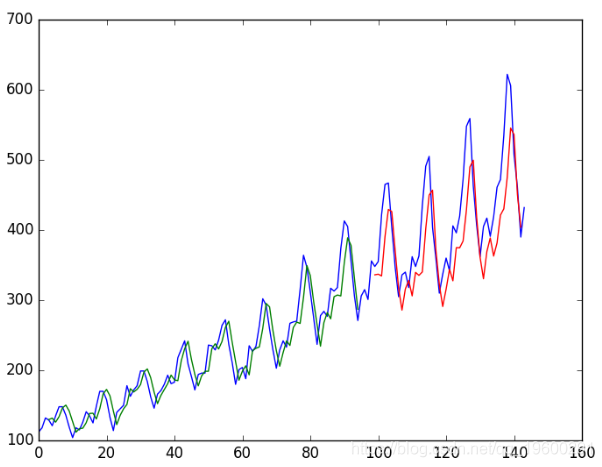
训练批次之间具有记忆的LSTM
LSTM网络具有内存,能够记忆长序列。
通常,在拟合模型以及每次对model.predict() 或 model.evaluate()的调用后,每次训练批次后都会重置网络中的状态 。
我们可以更好地控制何时在Keras中清除LSTM网络的内部状态。这意味着它可以在整个训练序列中建立状态,甚至在需要进行预测时也可以保持该状态。
要求在安装网络时,在每次训练数据之后,还需要通过调用model.reset_states()来重置网络状态 。这意味着我们必须创建自己的时期外循环,并在每个时期内调用 model.fit() 和 model.reset_states()。
最后,在构造LSTM层时, 必须将有状态参数设置为 True ,我们对批处理中的样本数量,样本中的时间步长以及一次中的特征数量进行编码。通过设置 batch_input_shape 参数。
随后,在评估模型和进行预测时,必须使用相同的批次大小。
-
model.predict(trainX, batch_size=batch_size)
-
我们可以改编先前的时间步骤示例来使用有状态LSTM。
运行将提供以下输出:
-
...
-
-
-
Epoch 1/1
-
-
1s - loss: 0.0016
-
-
Train Score: 20.74 RMSE
-
-
Test Score: 52.23 RMSE
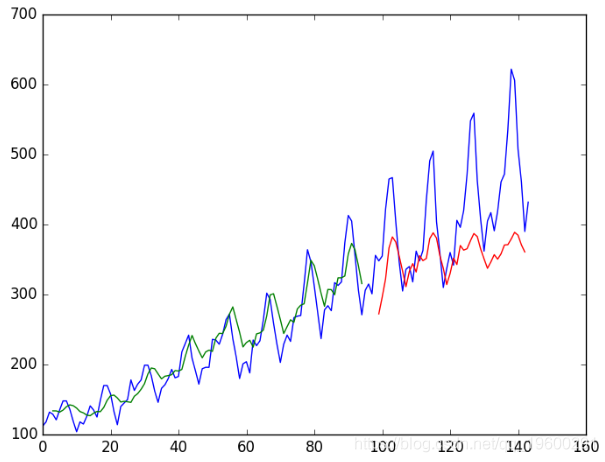
我们看到结果误差更大。该模型可能需要更多模块,并且可能需要针对更多时期进行训练。
批次之间具有内存的堆叠式LSTM
最后,我们将看看LSTM的一大优势:事实上,将LSTM堆叠到深度网络体系结构中就可以对其进行成功的训练。
LSTM网络可以以与其他层类型堆叠相同的方式堆叠在Keras中。所需配置的一个附加函数是,每个后续层之前的LSTM层必须返回序列。这可以通过将return_sequences参数设置 为 True来完成。
我们可以在上一节中将有状态LSTM扩展为两层
运行示例将产生以下输出。
-
...
-
-
Epoch 1/1
-
-
1s - loss: 0.0016
-
-
Train Score: 20.49 RMSE
-
-
Test Score: 56.35 RMSE
从对测试数据集的预测误差来看,模型需要更多的训练时间。
概要
在本文中,您发现了如何使用Keras深度学习网络开发LSTM递归神经网络,在Python中进行时间序列预测。

最受欢迎的见解
1.用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
2.Python中利用长短期记忆模型LSTM进行时间序列预测分析 – 预测电力消耗数据
4.Python中用PyTorch机器学习分类预测银行客户流失模型
6.在r语言中使用GAM(广义相加模型)进行电力负荷时间序列分析