原文链接 http://tecdat.cn/?p=23255
原文出处:拓端数据部落公众号
本文将谈论Stan以及如何在R中使用rstan创建Stan模型。尽管Stan提供了使用其编程语言的文档和带有例子的用户指南,但对于初学者来说,这可能是很难理解的。
Stan
Stan是一种用于指定统计模型的编程语言。它最常被用作贝叶斯分析的MCMC采样器。马尔科夫链蒙特卡洛(MCMC)是一种抽样方法,允许你在不知道分布的所有数学属性的情况下估计一个概率分布。它在贝叶斯推断中特别有用,因为后验分布往往不能写成表达式。要使用Stan,用户要写一个Stan程序,代表他们的统计模型。这个程序指定了模型中的参数和目标后验密度。Stan代码被编译并与数据一起运行,输出一组参数的后验模拟。Stan与最流行的数据分析语言,如R、Python、shell、MATLAB、Julia和Stata的接口。我们将专注于在R中使用Stan。
rstan
rstan允许R用户实现贝叶斯模型。你可以使用熟悉的公式和data.frame语法(如lm())来拟合模型。通过为常用的模型类型提供预编译的stan代码来实现这种更简单的语法。它使用起来很方便,但只限于特定的 "常用 "模型类型。如果你需要拟合不同的模型类型,那么你需要自己用rstan编码。
模型拟合函数以前缀stan_开始,以模型类型结束。建模函数有两个必要的参数。
- 公式。一个指定因变量和自变量的公式(y ~ x1 + x2)。
- data。一个包含公式中变量的数据框。
此外,还有一个可选的先验参数,它允许你改变默认的先验分布。
stan()函数读取和编译你的stan代码,并在你的数据集上拟合模型。
stan()函数有两个必要参数。
- 文件。包含你的Stan程序的.stan文件的路径。
- data。一个命名的列表,提供模型的数据。
例子
作为一个简单的例子来演示如何在这些包中指定一个模型,我们将使用汽车数据来拟合一个线性回归模型。我们的因变量是mpg,所有其他变量是自变量。
-
-
mtcars %>%
-
head()

首先,我们将拟合模型。对于线性回归,我们使用stan函数。
summary(fit)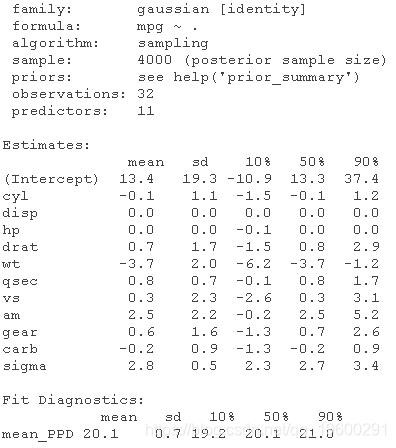
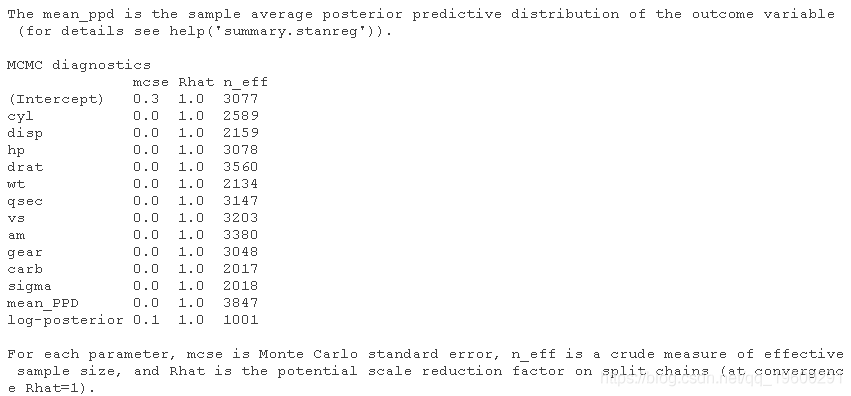
输出显示参数摘要,包括平均值、标准差和量值。此外,它还显示了MCMC的诊断统计Rhat和有效样本量。这些统计数据对于评估MCMC算法是否收敛非常重要。
接下来,我们将用rstan来拟合同一个模型。下面是我们模型的stan代码,保存在一个名为stan的文件中(你可以在RStudio中创建一个.stan文件,或者使用任何文本编辑器,并保存扩展名为.stan的文件)。
-
-
数据
-
int<lower=0> N; // 观测值的数量
-
int<lower=0> K; // 预测的数量
-
matrix[N, K] X; // 预测矩阵
-
...
-
参数
-
real alpha; // 截距
-
...
-
模型
-
y ~ normal(alpha + X * beta, sigma); // 目标密度
-
Stan代码在 "程序块 "中结构化。每个Stan模型都需要三个程序块,即数据、参数和模型。
数据块是用来声明作为数据读入的变量的。在我们的例子中,我们有结果向量(y)和预测矩阵(X)。当把矩阵或向量声明为一个变量时,你需要同时指定对象的维度。因此,我们还将读出观测值的数量(N)和预测器的数量(K)。
在参数块中声明的变量是将被Stan采样的变量。在线性回归的情况下,感兴趣的参数是截距项(alpha)和预测因子的系数(beta)。此外,还有误差项,sigma。
模型区块是定义变量概率声明的地方。在这里,我们指定目标变量具有正态分布,其平均值为α+X*β,标准差为sigma。在这个块中,你还可以指定参数的先验分布。默认情况下,参数被赋予平坦的(非信息性)先验。
此外,还有一些可选的程序块:函数、转换的数据、转换的参数和生成的数量。
接下来,我们需要以Stan程序所期望的方式来格式化我们的数据。stan()函数要求将数据作为一个命名的列表传入,其中的元素是你在数据块中定义的变量。对于这个程序,我们创建一个元素为N、K、X和Y的列表。
-
list(
-
N = 32,
-
K = 10,
-
X = predictors,
-
y = mpg
-
)
现在我们已经准备好了我们的代码和数据,我们把它们传给函数来拟合模型。
fit_rstan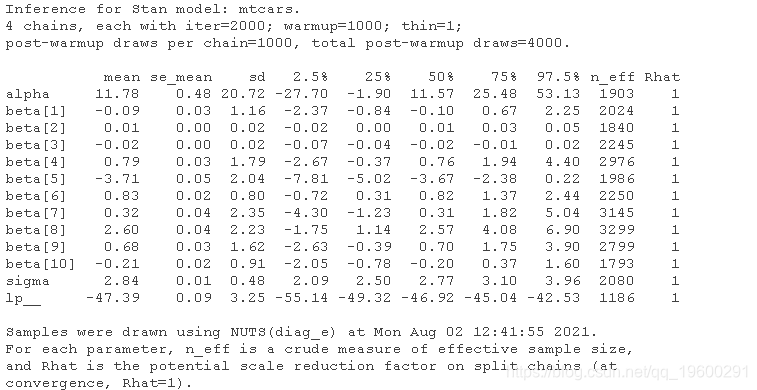
输出类似的汇总统计数据,包括每个参数的平均值、标准偏差和量值。这些结果可能相似但不完全相同。它们之所以不同,是因为统计数据是根据后验的随机抽样来计算的。
评估收敛性
当使用MCMC拟合一个模型时,检查链是否收敛是很重要的。我们推荐可视化来直观地检查MCMC的诊断结果。我们将创建轨迹图,Rhat值图。
首先,让我们创建轨迹图。轨迹图显示了MCMC迭代过程中参数的采样值。如果模型已经收敛,那么轨迹图应该看起来像一个围绕平均值的随机散点。如果链在参数空间中蜿蜒,或者链收敛到不同的值,那就证明有问题了。我们来演示。
-
-
mcmctrace()
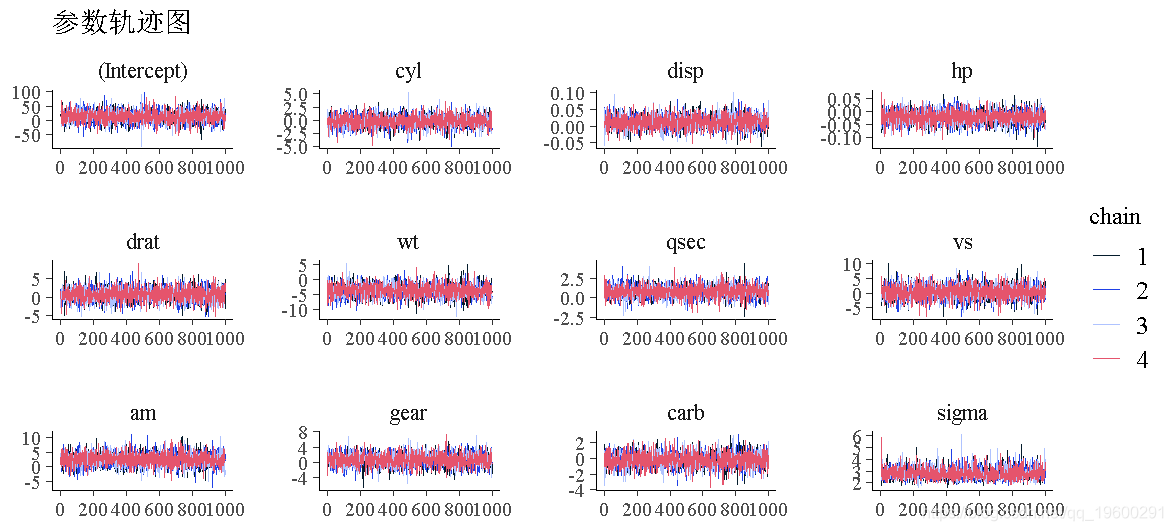

这些轨迹图表明,两个模型都已经收敛了。对于所有的参数,四条链都是混合的,没有明显的趋势。
接下来,我们将检查Rhat值。Rhat是一种收敛诊断方法,它比较了各条链的参数估计值。如果链已经收敛并且混合良好,那么Rhat值应该接近1。如果链没有收敛到相同的值,那么Rhat值将大于1。Rhat值为1.05或更高,表明存在收敛问题。rhat()函数需要一个Rhat值的向量作为输入,所以我们首先提取Rhat值。
-
rhat() +
-
yaxis_text()
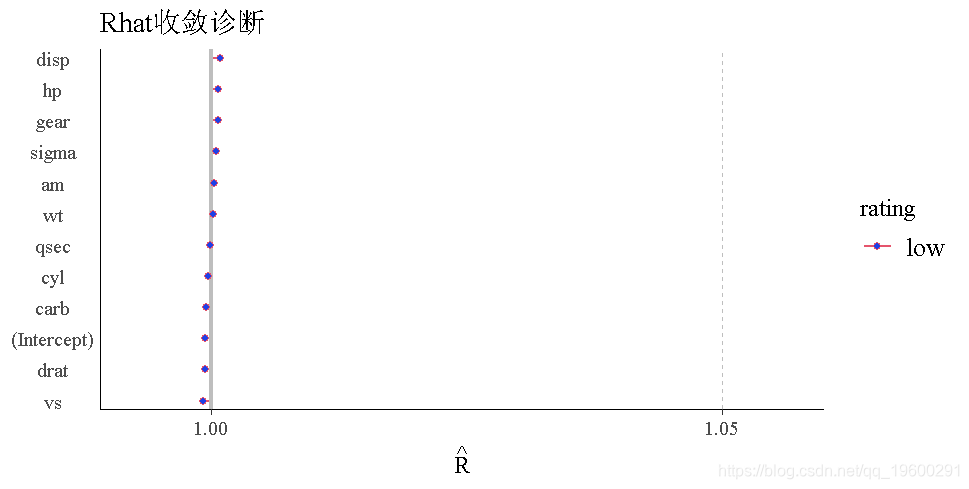
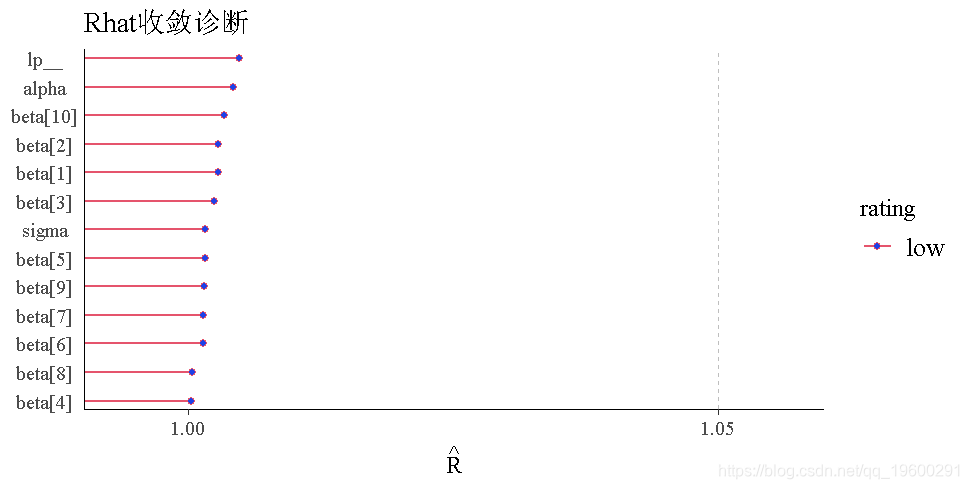
所有的Rhat值都低于1.05,说明没有收敛问题。
Stan是一个建立贝叶斯模型的强大工具,这些包使R用户可以很容易地使用Stan。

最受欢迎的见解
1.使用R语言进行METROPLIS-IN-GIBBS采样和MCMC运行
3.R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
4.R语言BUGS JAGS贝叶斯分析 马尔科夫链蒙特卡洛方法(MCMC)采样
5.R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
7.R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数