public class Main{
public static void main(String[] args){
/* 1 */
String string = "a" + "b" + "c";
/* 2 */
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("a");
stringBuffer.append("b");
stringBuffer.append("c");
string = stringBuffer.toString();
}
}

当时大部分的新手猿友都表示,stringbuffer快于string+。唯有群里一位有工作经验的猿友说,是string+的速度快。这让LZ意识到,工作经验确实不是白积累的,一个小问题就看出来了。
这里确实string+的写法要比stringbuffer快,是因为在编译这段程序的时候,编译器会进行常量优化,它会将a、b、c直接合成一个常量abc保存在对应的class文件当中。LZ当时在群里贴出了编译后的class文件的反编译代码,如下。
public class Main
{
public static void main(String[] args)
{
String string = "abc";
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("a");
stringBuffer.append("b");
stringBuffer.append("c");
string = stringBuffer.toString();
}
}
可以看出,在编译这个java文件时,编译器已经直接进行了+运算,这是因为a、b、c这三个字符串都是常量,是可以在编译期由编译器完成这个运算的。假设我们换一种写法。
public class Main{
public static void main(String[] args){
/* 1 */
String a = "a";
String b = "b";
String c = "c";
String string = a + b + c;
/* 2 */
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(a);
stringBuffer.append(b);
stringBuffer.append(c);
string = stringBuffer.toString();
}
}
此处的答案貌似应该是stringbuffer更快,因为此时a、b、c都是对象,编译器已经无法在编译期进行提前的运算优化了。
但是,事实真的是这样的吗?
其实答案依然是第一种写法更快,也就是string+的写法更快,这一点可能会有猿友比较疑惑。这个原因是因为string+其实是由stringbuilder完成的,而一般情况下stringbuilder要快于stringbuffer,这是因为stringbuilder线程不安全,少了很多线程锁的时间开销,因此这里依然是string+的写法速度更快。
尽管LZ已经解释了原因,不过可能还是有猿友依然不太相信,那么下面我们来写一个测试程序。
public class Main
{
public static void main(String[] args)
{
String a = "a";
String b = "b";
String c = "c";
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
String string = a + b + c;
if (string.equals("abc")) {}
}
System.out.println("string+ cost time:" + (System.currentTimeMillis() - start) + "ms");
start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(a);
stringBuffer.append(b);
stringBuffer.append(c);
String string = stringBuffer.toString();
if (string.equals("abc")) {}
}
System.out.println("stringbuffer cost time:" + (System.currentTimeMillis() - start) + "ms");
}
}
我们每个进行了1亿次,我们会看到string+竟然真的快于stringbuffer,是不是瞬间被毁了三观,我们来看下结果。

答案已经很显然,string+竟然真的比stringbuffer要快。这里其实还是编译器捣的鬼,string+事实上是由stringbuilder完成的。我们来看一下这个程序的class文件内容就可以看出来了。

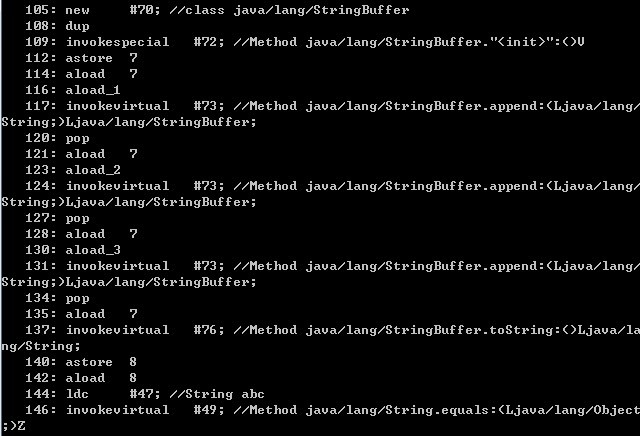
由于文件太长,所以LZ是分开截的图。可以看到,里面有两次stringbuilder的append方法调用,三次stringbuffer的append方法调用。stringbuilder只有两次append方法的调用,是因为在创建stringbuilder对象的时候,第一个字符串也就是a对象已经被当做构造函数的参数传入了进去,因此就少了一次append方法。
不过请各位猿友不要误会,这里stringbuilder之所以比stringbuffer快,是因为少了锁同步的开销,而不是因为少了一次append方法,原因看下面这段stringbuilder类的源码就知道了。
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
}
可以看到,实际上带有string参数的构造方法,依然是使用的append方法,因此stringbuilder其实也进行了三次append方法的调用。
看到这里,估计有的猿友就该奇怪了,这么看的话,似乎string+的速度比stringbuffer更快,难道以前的认识都错误了?
答案当然是否定的,我们来看下面这个小程序,你就看出来差别有多大了。
public class Main
{
public static void main(String[] args)
{
String a = "a";
long start = System.currentTimeMillis();
String string = a;
for (int i = 0; i < 100000; i++) {
string += a;
}
if (string.equals("abc")) {}
System.out.println("string+ cost time:" + (System.currentTimeMillis() - start) + "ms");
start = System.currentTimeMillis();
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < 100000; i++) {
stringBuffer.append(a);
}
if (stringBuffer.toString().equals("abc")) {}
System.out.println("stringbuffer cost time:" + (System.currentTimeMillis() - start) + "ms");
}
}
这个程序与刚才的程序有着细微的差别,但是结果却会让你大跌眼镜。我们来看结果输出。
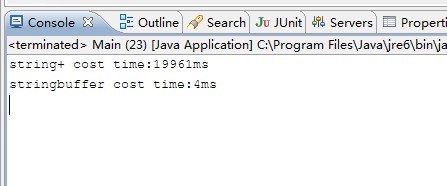
看到这个结果是不是直接给跪了,效率差了这么多?这还是LZ将循环次数降到了10万,而不是1亿,因为1亿次LZ跑了很久也没跑完,LZ等不急了,0.0。
造成这种情况的原因,我们看两个程序的区别就看出来了。第一个循环1亿次的程序,不管是string+还是stringbuffer都是在循环体里构造的字符串,最重要的是string+是由一个语句构造而成的,因此此时string+其实和stringbuffer实际运行的方式是一样的,只不过string+是使用的stringbuilder而已。
而对于上面这个10万次循环的程序,stringbuffer就不用说了,实际运行的方式很明显。而对于string+,它将会创造10万个stringbuilder对象,每一次循环体的发生,都相当于我们新建了一个stringbuilder对象,将string对象作为构造函数的参数,并进行一次append方法和一次toString方法。
由上面几个小程序我们可以看出,在string+写成一个表达式的时候(更准确的说,是写成一个赋值语句的时候),效率其实比stringbuffer更快,但如果不是这样的话,则效率会明显低于stringbuffer。我们来再写一个程序证实这一点。
为了不会导致编译失败,我们将循环次数减为1万次,否则会超出文件的最大长度,我们先来看看刚才的程序改为1万次循环的结果。
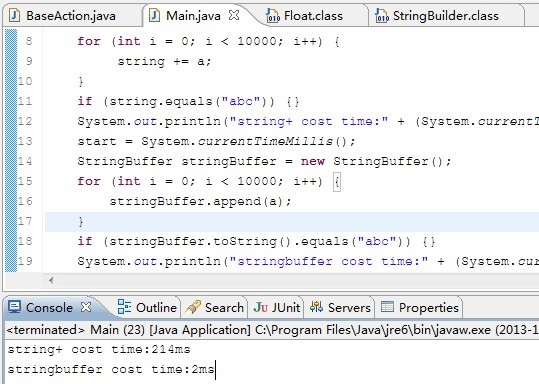
可以看到,在1万次的循环下,依然可以看到效率上的明显差异,这个差距已经足够我们观察了。现在我们就改一种写法,它会让string+的效率提高到stringbuffer的速度,甚至更快。
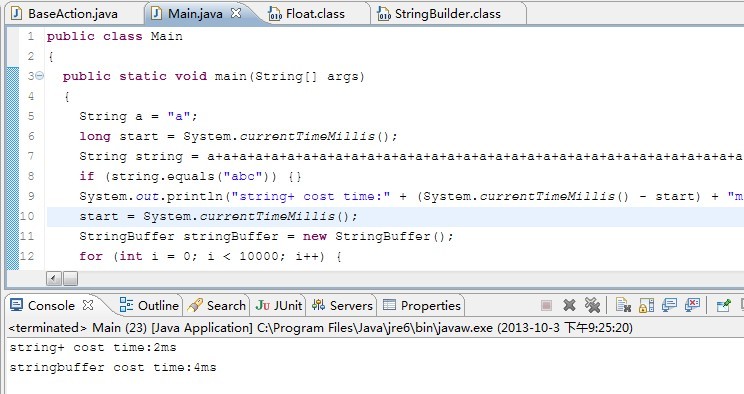
这里我们是将1万次字符串的拼接直接写成了一个表达式,那个a+a+...表达式一共是1万个(是LZ使用循环打印出来贴到代码处的),可以看到,此时string+的速度已经超过了stringbuffer。
因此LZ给各位猿友一个建议,如果是有限个string+的操作,可以直接写成一个表达式的情况下,那么速度其实与stringbuffer是一样的,甚至更快,因此有时候没必要就几个字符串操作也要建个stringbuffer(如果中途拼接操作的字符串是线程间共享的,那么也建议使用stringbuffer,因为它是线程安全的)。但是如果把string+的操作拆分成语句去进行的话,那么速度将会指数倍下降。
总之,我们大部分时候的宗旨是,如果是string+操作,我们应该尽量在一个语句中完成。如果是无法做到,并且拼接动作很多,比如数百上千成万次,则必须使用stringbuffer,不能用string+,否则速度会很慢。
原文地址:http://www.cnblogs.com/aipan/p/7443832.html