4. SQL SERVER存储引擎之数据篇
(4.1)文件
(0)主数据文件.mdf初始文件大小至少为3MB,次要数据文件.ndf初始大小,同日志文件一样至少为512KB;
(1)SQL SERVER在逻辑上用文件组将文件分批管理(类似ORACLE的TABLESPACE),一个文件组可以包含多个文件,插入数据时,同一个文件组内的所有文件等比例增长。例如:文件组中有两个文件,初始大小分别为100M和200M,此时插入3M的数据,file1新增(100/300)*3M=1M,file2新增(200/300)*3M=2M。
(2)页(page),SQL SERVER中的数据文件由8K大小的数据页组成,每个数据文件中的页从0开始编号,页大小不可以自定义,且每个页只属于一个数据对象。
(3)区(extent),或者叫扩展,8个物理上连续的页为一个扩展,即64k;扩展的存在是为了避免不停的分配8k的页面,提高页面分配的效率。SQL SERVER有两种类型的区,如下图:
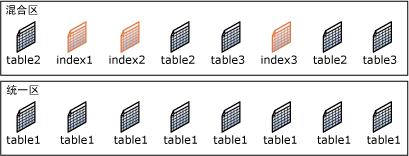
混合区:为了节约空间,将少量数据的表或索引存放在混合区,当表或索引的数据增长到8页时,再使用统一区来存放,一个混合区有8个页,每个页可以属于不同的数据对象,即每个混合区最多为8个数据对象共享。
统一区:由单个数据对象所有,如果对表中现有数据创建索引,且索引的大小超过8页,则索引将全部使用统一区,没有混合区的分配过程。
(4.2)页
(4.2.1)非数据页
(0)文件头,每个数据文件的第一页,页号为0,该页主要包括当前文件的属性描述,比如:文件组ID、文件ID、文件当前大小、文件最大/最小值、文件增量、一系列的LSN等;
(1)页面空闲空间(PFS),每个数据文件的第二页,页号为1,该页记录当前数据文件每个数据页的空间状态:该页是为空、已满1%到50%、已满51%到80%、已满81%到95%,还是已满96%到100%。PFS页内用1个字节来描述1个数据页的分配及空间状态,每个PFS页约有可用空间8088个字节,即数据文件内约每64M的空间会出现一个PFS页。
(2)全局分配映射(GAM),每个数据文件的第3页,页号为2,该页记录当前数据文件每个区的分配状态,0为已使用(作为混合区或统一区),1为未使用(自由区,未分配)。
(3)共享分配映射(SGAM),每个数据文件的第4页,页号为3,该页记录当前数据文件哪些区被用作混合区,1为含有自由页面的混合区,0为自由区或已满的混合区。
(4)索引分配映射(IAM),该页跟踪数据文件中的页属于哪个数据对象,IAM页头有8个页面指针,指向数据对象在混合区中的数据页(如果混合区中的数据被删除可能少于8个指针),IAM页内比特位为1表示该区属于自己所属的数据对象,比特位为0表示该区不属于自己所属的数据对象。
(4.1)每个数据对象的每个分配单元拥有一个IAM页,IAM同GAM、SGAM一样可以管理约4G的空间,如果分配单元包含多个文件,或者文件大小超过4G,则需要另外的IAM页来管理,IAM页间通过双向链表连接;
(4.2)可以通过sysindexes或sys.system_internals_allocation_units系统目录得到first_IAM页面的位置,IAM页在数据文件中的位置是随机的,可能IAM页所在文件并不是所管理的那个文件;

(5)差异更改映射(DCM),每个数据文件的第7页,页号为6(页号4,5为保留页),该页跟踪当前数据文件中,自上次全备份后被修改的区,以提高差异备份的效率,1为被修改过,0为未被修改;
(6)大批量更改映射(BCM),每个数据文件的第8页,页号为7,该页跟踪当前数据文件中,自上次日志备份后被大批量操作修改的区,1为被修改过,0为未被修改;
(4.2.2)数据页
(0)数据页包含页头、数据行、行偏移矩阵三部分,如下图:

(1)行内数据(IN_ROW_DATA),单行未超过8060B的数据行,或者单行超过8060B但仍存储在当前页的数据,称为行内数据;
(2)行溢出数据(ROW_OVERFLOW_DATA),在SQL SERVER2005及以后的版本中,如果表中定义了变成的数据类型,允许单行数据长度突破8060B,超过的部分即为行溢出数据,如果变长列被更新后缩短,可能会被移回行内数据页(通常减少1000字节以上时,SQL SERVER才会有检查是否可移回)。
(3)大对象数据(LOB_DATA),存放如text/image/xml/varchar(max)等最大长度可超过8000B的数据类型的数据;
大对象数据也是通过8k的数据页来存放数据,在行内数据页中包含一个16字节的指针指向大对象数据的根页,大对象数据通过B-树结构来组织多个数据页;
可以通过打开text in row选项将大对象数据存储在行内数据页,当大对象数据被更新超过500B时,则会从行内数据页将大对象数据移出,这是个日志操作,因此移动操作比较耗时,所以不建议开启该选项;
(4)数据行
每个数据行,除了每个列的数据之外,还包括状态位、定长列偏移量、总列数、NULL位图、变长列数、列偏移矩阵,这些即为行开销。
创建全定长列的表,数据行如下图:
if object_id ('test_col') is not null
drop table test_col;
GO
create table test_col
(
col1 char(1),
col2 char(2)
)
GO
insert into test_col values('A','B')
