在使用Python2时,我们习惯于在文件开头声明编码
# coding: utf-8
不然在文件中出现中文,运行时就会报错 SyntaxError: Non-ASCII character... 之类,这是因为python2的文件编码默认使用的ascii,ascii码是不支持中文的。
如果在开头声明了编码,文件编码就会变为utf-8。
python执行过程的编解码
python使用的unicode类型作为编码的基础类型,默认情况下,python在执行文件过程中的编解码为 str-->unicode-->str,当我们在python开头声明utf-8编码后,编解码就变为了 str-->ascii-->str
举个简单例子,就可以验证这个现象。
# coding:utf-8 s = "我要学Python" print(1, s)

从打印结果可以看出,我们没有做任何处理,中文在执行过程就被处理成了ascii码
encode&decode
在了解了Python执行过程的编码转换后,那我们自己如果转换编码该如何实现呢?这里就得使用两个内置方法 encode编码和decode解码。
例如:
# coding:utf-8 s = "我要学Python" s.encode("utf-8") # 编码 s.decode("utf-8") # 解码
上面是方法的简单运用,但是执行上面代码,第3行就会出现编解码过程中常见的一个报错
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)

简单分析下,明明执行的encode方法,为什么会抛decode错误呢?这就要从上面介绍的python执行过程来分析了。
在执行encode方法编码时,python先要解码,而Python解码默认用unicode格式,而文件开头指定的编码格式为ascii,这就导致编码格式与解码格式不一致,从而产生了报错 ascii 不能解码成 unicode。
要解决这个问题,只需要在编码前,用utf-8格式解码就可以了
s = "我要学Python" s.decode("utf-8").encode("utf-8") # 编码 s.decode("utf-8") # 解码

中文乱码解决方法
在了解编解码过程后,我们来解决实际遇到的问题:接口响应中文乱码!
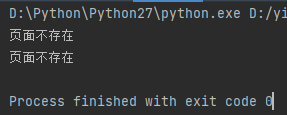
比如:在接口测试中,有些响应类似 "u9875u9762u4e0du5b58u5728" 的响应内容,看起来就像乱码

注意看乱码前面有个u ,这表示使用的unicode编码字符。可用以下方法进行解码:
# 直接在 unicode 字符串前加u ===> 使用Python机制自动解码 s = u"u9875u9762u4e0du5b58u5728" print(s) # 打印:页面不存在。因为字符串为unicode编码格式,python在执行过程中,默认就是使用的unicode解码,编解码类型一致,就看到了中文打印内容 # 使用 decode 方法解码成中文 ===> 主动解码 s = "u9875u9762u4e0du5b58u5728" print(s.decode("unicode_escape"))
常见问题
格式化带有中文的字符串报错
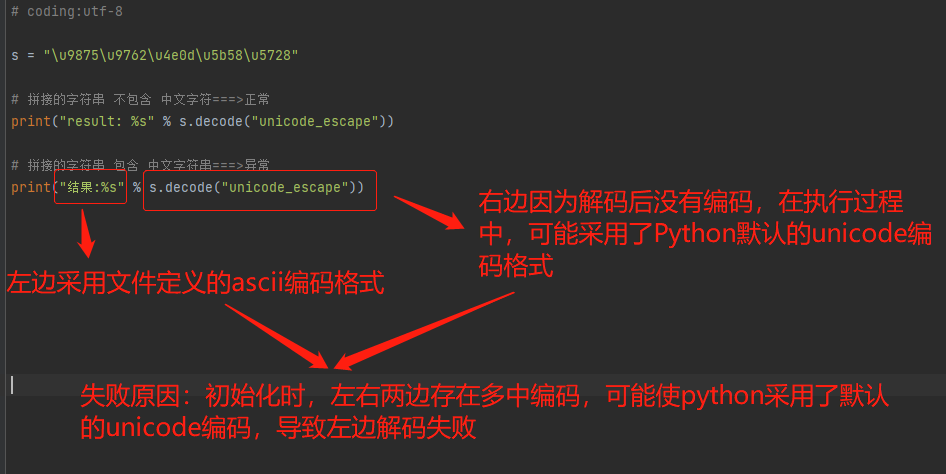
格式拼接的字符串包含中文,会抛错:UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)
# coding:utf-8 s = "u9875u9762u4e0du5b58u5728" # 拼接的字符串 不包含 中文字符===>正常 print("result: %s" % s.decode("unicode_escape")) # 拼接的字符串 包含 中文字符串===>异常 print("结果: %s" % s.decode("unicode_escape"))

问题分析:
解决方法:
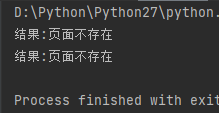
统一编码格式
# coding:utf-8 s = "u9875u9762u4e0du5b58u5728" # 方法1:将右边变为 ascii 编码 print("结果:%s" % s.decode("unicode_escape").encode("utf-8")) # 方法2:将左边变为 unicode 编码 print(u"结果:%s" % s.decode("unicode_escape"))
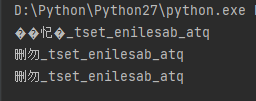
带有中文的字符串反转后乱码
带有中文的字符串使用列表反转方式后乱码,使用decode("utf-8") 解码,报错:UnicodeDecodeError: 'utf8' codec can't decode byte 0xa0 in position 0: invalid start byte
# coding:utf-8 s = "qta_baseline_test_勿删"[::-1] print(s) print(s.decode("utf-8"))
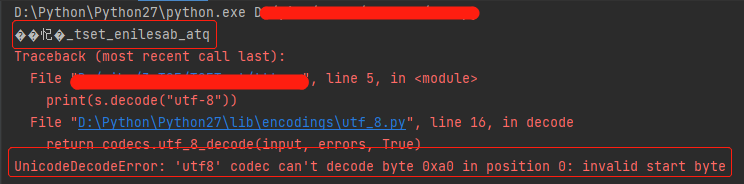
问题分析:
中文被Python解析后,先转换成ascii码

当使用列表反转方式后,实际把ascii反转
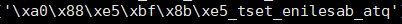
这就导致了反转后的乱码无法被decode("utf-8")正常解码
解决方法:
因为采用的utf-8编码,所以先使用utf-8解码,解码后再反转
# coding:utf-8 s = "qta_baseline_test_勿删"[::-1] print(s) s = "qta_baseline_test_勿删".decode("utf-8")[::-1] print(s) s = s.encode("utf-8") # 为了后续字符串能正常使用,建议在按原编码方式编码 print(s)