- CPU全称:Central Processing Unit, 即中央处理器
- GPU全称:Graphics Processing Unit, 即图像处理器
- TPU全称:Tensor Processing Unit, 即张量处理器
- DPU全称:Deep learning Processing Unit, 即深度学习处理器
- NPU全称:Neural network Processing Unit, 即神经网络处理器
- BPU全称:Brain Processing Unit, 即大脑处理器
-
DSP(Digital Signal Processing)即数字信号处理技术,DSP芯片即指能够实现数字信号处理技术的芯片。DSP芯片的内部采用程序和数据分开的哈佛结构,具有专门的硬件乘法器,广泛采用流水线操作,提供特殊的DSP指令,可以用来快速的实现各种数字信号处理算法。
CPU
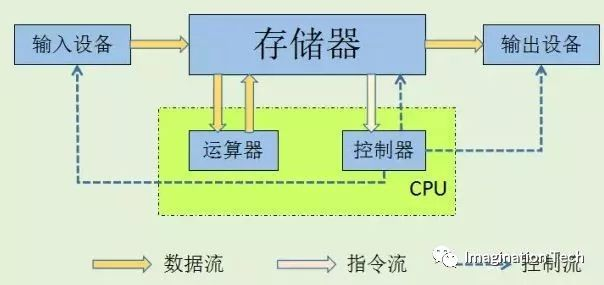
CPU主要包括运算器(ALU, Arithmetic and Logic Unit)和控制单元(CU, Control Unit),除此之外还包括若干寄存器、高速缓存器和它们之间通讯的数据、控制及状态的总线。CPU遵循的是冯诺依曼架构,即存储程序、顺序执行。一条指令在CPU中执行的过程是:读取到指令后,通过指令总线送到控制器中进行译码,并发出相应的操作控制信号。然后运算器按照操作指令对数据进行计算,并通过数据总线将得到的数据存入数据缓存器。因此,CPU需要大量的空间去放置存储单元和控制逻辑,相比之下计算能力只占据了很小的一部分,在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
GPU
为了解决CPU在大规模并行运算中遇到的困难, GPU应运而生,采用数量众多的计算单元和超长的流水线,如名字一样,图形处理器,GPU善于处理图像领域的运算加速。但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。近年来,人工智能的兴起主要依赖于大数据的发展、理论算法的完善和硬件计算能力的提升。其中硬件的发展则归功于GPU的出现。见下图:CPU、GPU微架构对比图

TPU
人工智能旨在为机器赋予人的智能,机器学习是实现人工智能的强有力方法。所谓机器学习,即研究如何让计算机自动学习的学科。TPU就是这样一款专用于机器学习的芯片,它是Google于2016年5月提出的一个针对Tensorflow平台的可编程AI加速器,其内部的指令集在Tensorflow程序变化或者更新算法时也可以运行。TPU可以提供高吞吐量的低精度计算,用于模型的前向运算而不是模型训练,且能效(TOPS/w)更高。在Google内部,CPU,GPU,TPU均获得了一定的应用,相比GPU,TPU更加类似于DSP,尽管计算能力略有逊色,其功耗大大降低。然而,TPU,GPU的应用都要受到CPU的控制。

DPU
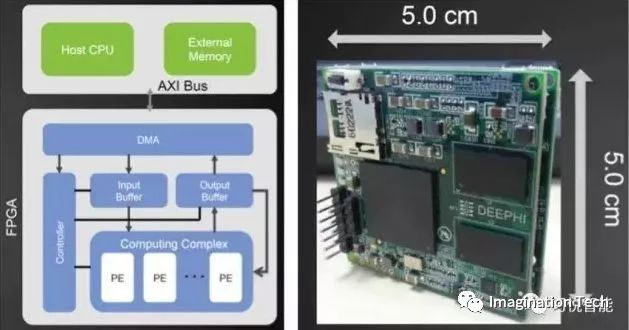
DPU深度学习处理器最早由国内深鉴科技提出,基于Xilinx可重构特性的FPGA芯片,设计专用的深度学习处理单元(可基于已有的逻辑单元,设计并行高效的乘法器及逻辑电路,属于IP范畴),且抽象出定制化的指令集和编译器(而非使用OpenCL),从而实现快速的开发与产品迭代。事实上,深鉴提出的DPU属于半定制化的FPGA。
NPU
NPU,神经网络处理器,在电路层模拟人类神经元和突触,并且用深度学习指令集直接处理大规模的神经元和突触,一条指令完成一组神经元的处理。相比于CPU中采取的存储与计算相分离的冯诺伊曼结构,NPU通过突触权重实现存储和计算一体化,从而大大提高了运行效率。NPU的典型代表有国内的寒武纪芯片和IBM的TrueNorth,中星微电子的“星光智能一号”虽说对外号称是NPU,但其实只是DSP,仅支持网络正向运算,无法支持神经网络训练。而且从存储结构上看,该款芯片是基于传统的片上存储,而非神经网络芯片的便携式存储。
BPU
BPU, 大脑处理器,是由地平线科技提出的嵌入式人工智能处理器架构。第一代是高斯架构,第二代是伯努利架构,第三代是贝叶斯架构。目前地平线已经设计出了第一代高斯架构,并与英特尔在2017年CES展会上联合推出了ADAS系统。传统CPU芯片是做所有事情,所以一般采用串行结构。BPU主要是用来支撑深度神经网络,比如图像、语音、文字、控制等方面的任务,而不是去做所有的事情。此外,深度神经网络的计算结构比较特殊,比如高度的并行化、时间域上的递归、中间节点的稀疏等,用BPU来实现会比在CPU上用软件实现要高效,一般来说会提高2-3个数量级。然而,BPU一旦生产,不可再编程,且必须在CPU控制下使用。
参考: