import urllib2
response = urllib2.urlopen("https://www.baidu.com")
print response.read()
构造Requset
其实上面的urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data等等的内容。
比如上面的两行代码,我们可以这么改写:
import urllib2
request = urllib2.Request("https://www.baidu.com")
response = urllib2.urlopen(request)
print response.read()
运行结果是完全一样的,只不过中间多了一个request对象,推荐大家这么写,因为在构建请求时还需要加入好多内容,通过构建一个request,服务器响应请求得到应答,这样显得逻辑上清晰明确。
GET方法
import urllib
import urllib2
values={}
values['username'] = "993484988@qq.com"
values['password']="XXXX"
data = urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request = urllib2.Request(geturl)
response = urllib2.urlopen(request)
print response.read()
print geturl
可以通过print geturl,打印输出一下url,发现其实就是原来的url加?然后加编码后的参数 http://passport.csdn.net/account/login?username=993484988%40qq.com&password=XXXX
POST方法
import urllib
import urllib2
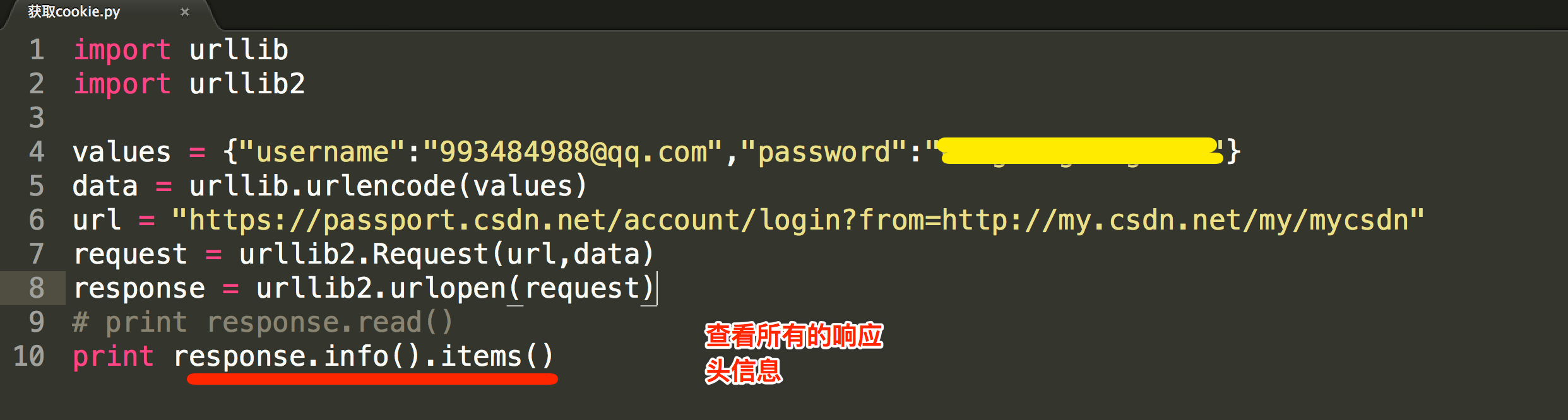
values = {"username":"993484988@qq.com","password":"XXXX"}
data = urllib.urlencode(values)
url = "https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"
request = urllib2.Request(url,data)
response = urllib2.urlopen(request)
print response.read()
说明:
我们引入了urllib库,现在我们模拟登陆CSDN,当然上述代码可能登陆不进去,因为还要做一些设置头部header的工作,或者还有一些参数 没有设置全,还没有提及到在此就不写上去了,
在此只是说明登录的原理。我们需要定义一个字典,名字为values,参数我设置了username和 password,下面利用urllib的urlencode方法将字典编码,命名为data,构建request时传入两个参数,
url和data,运行程序,即可实现登陆,返回的便是登陆后呈现的页面内容
伪造请求头信息
#coding=utf-8
import urllib2
import sys
#抓取网页内容-发送报头-1
url= "http://www.phpno.com"
send_headers = {
'Host':'www.phpno.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Connection':'keep-alive'
}
req = urllib2.Request(url,headers=send_headers)
r = urllib2.urlopen(req)
# ...省略后面的代码...
通过 help(urllib2)可以查看这个模块中的很多类以及方法
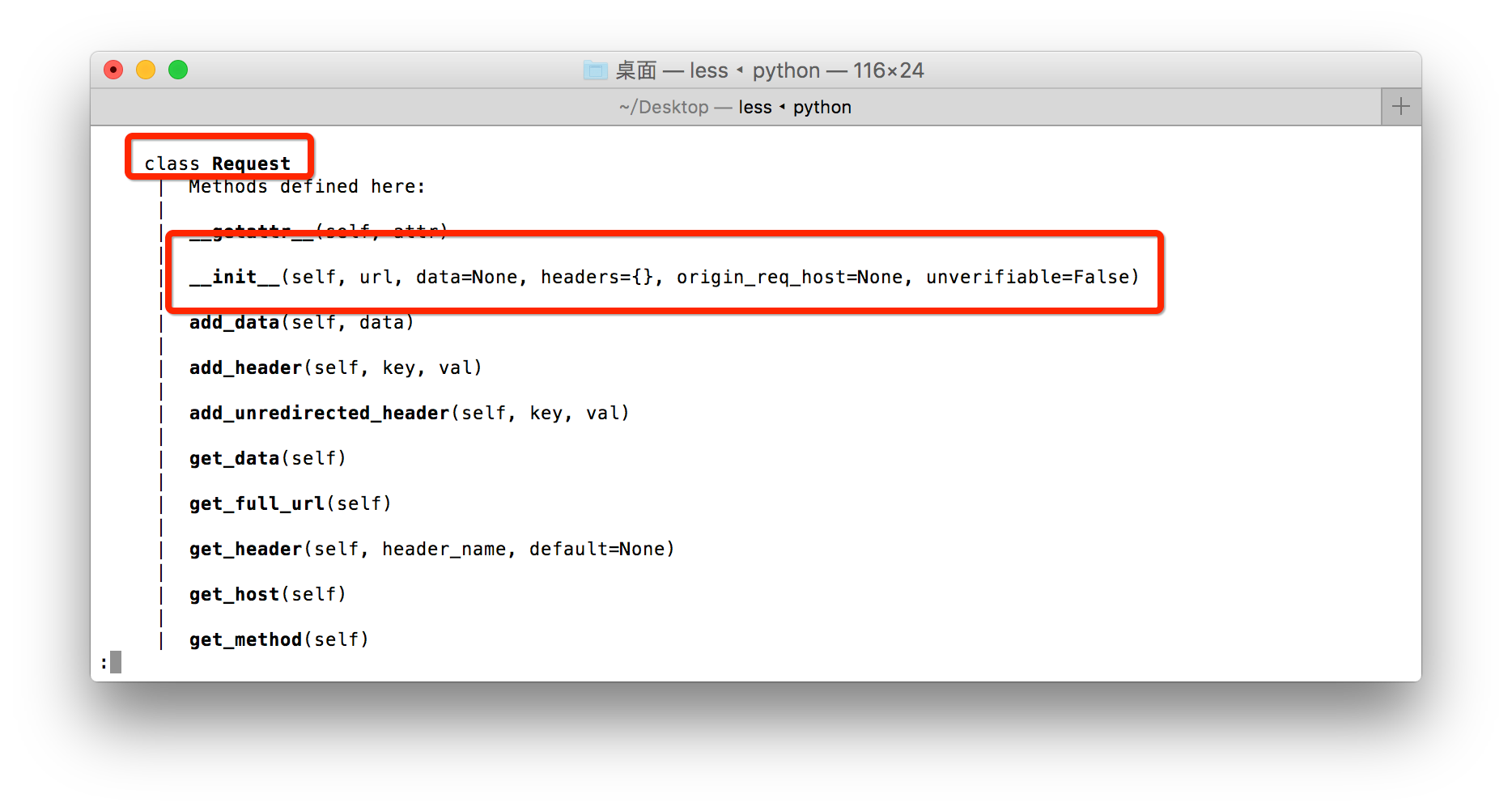
通过urlopen().info() 可以查看到很多的操作方法
urllib和urllib2的区别
- urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。这意味着,你不可以通过urllib模块伪装你的User Agent字符串等(伪装浏览器)。
- urllib提供urlencode方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
- urllib2模块比较优势的地方是urlliburllib2.urlopen可以接受Request对象作为参数,从而可以控制HTTP Request的header部