自学Python的时候看了不少老男孩的视频,一直欠老男孩一个会员,现在99元爬虫集训果断参与。
非常喜欢Alex和武Sir的课,技术能力超强,当然讲着讲着就开起车来也说明他俩开车的技术也超级强!
以上是闲扯,开始正式话题。
-----------------------------------------------华丽的分割线--------------------------------------------------
爬虫是什么
百度上是这样讲的。
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
通俗的讲,爬虫就是能够自动访问互联网并将网站内容下载下来的的程序或脚本,类似一个机器人,能把别人网站的信息弄到自己的电脑上,再做一些过滤,筛选,归纳,整理,排序等等。
网络爬虫的英文即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
Python爬虫用到的第三方库
主要有:Requests, Re,BS4, Lxml, Scrapy等
第一章主要是使用Requests, Re 和 BS4
Requests库是由著名的Python界的大神Kenneth Reitz开发的,他同时也是Pipenv的作者,牛人就是牛呀!
关键是人家不仅代码写的好,减肥也减的好呀!以下两张图,大家可以对比下。


Requests主要用来发送请求(get, post等)获取Response,然后使用re正则匹配提取内容,或者使用BS4、Lxml进行解析提取需要的内容。具体用法就不在这里罗列了,传送门如下。
学习心得
写代码这个事,重要的还是自我学习能力和解决问题的能力。自己仍然要加油。老男孩的Python课程讲得真是好,赞赞赞
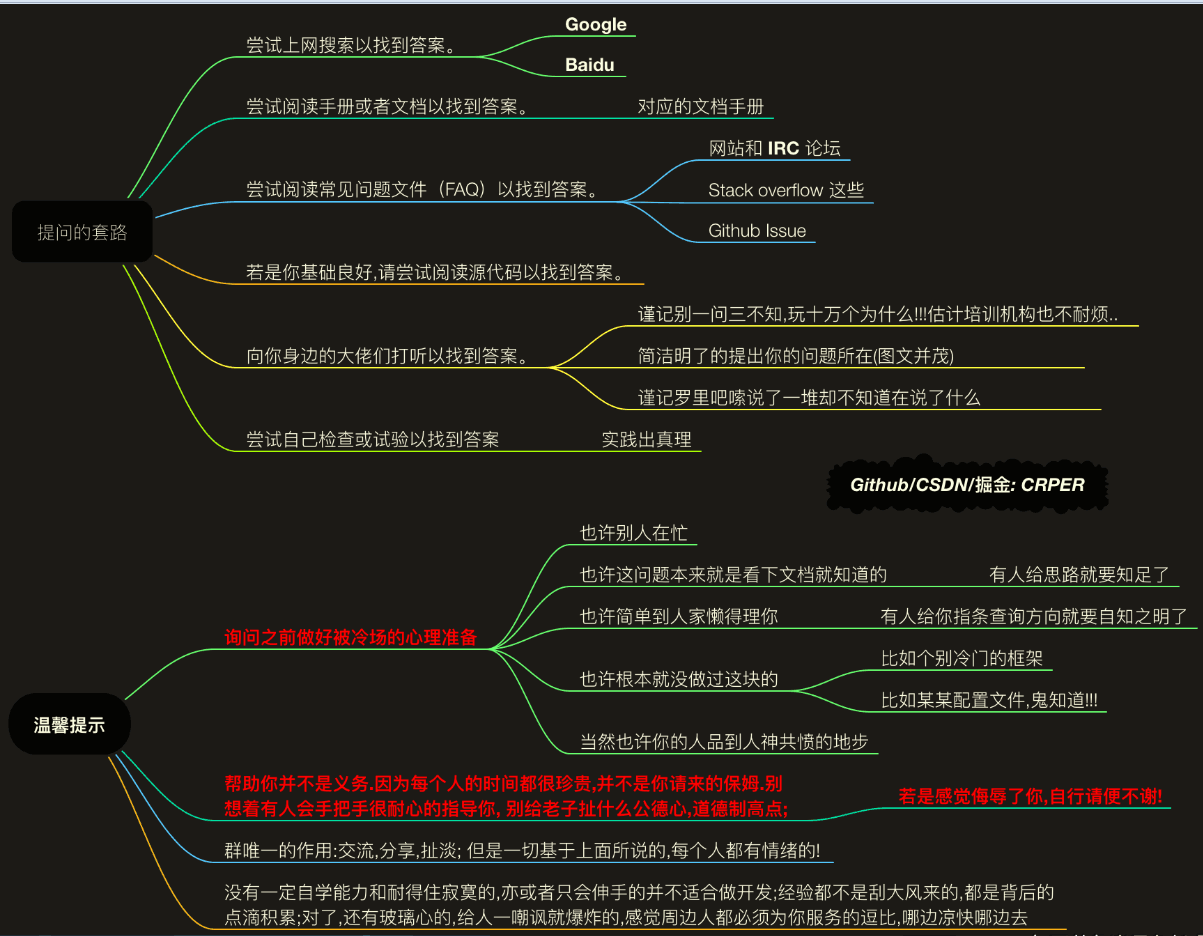
有时候大家问问题可能会被人拒绝,看看下边的图,安慰下玻璃心,重要的还是要自己加油哈!