对每个连接,TCP管理4个不同的定时器
- 重传定时器使用于当希望收到另一端的确认。
- 坚持定时器使窗口大小信息保持不断流动,即使另一端关闭了其接收窗口。。
- 保活定时器可检测到一个空闲连接的另一端何时崩溃或重启。
- 2MSL定时器测量一个连接处于TIME_WAIT状态的时间。
慢启动:连接上最初只允许传输一个报文段,然后在发送下一个报文段之前必须等待接收它的确认。当报文段2被接收后,就可以再发送两个报文段。
避免拥塞算法
慢启动算法是在一个连接上发起数据流的方法,但有时我们会达到中间路由器的极限,此时分组将被丢弃。拥塞避免算法是一种处理丢失分组的方法。拥塞避免算法和慢启动算法是两个目的不同、独立的算法。但是当拥塞发生时,我们希望降低分组进入网络的传输速率,于是可以调用慢启动来作到这一点。
两种分组丢失的指示:发生超时和接收到重复的确认。
拥塞避免算法和慢启动算法需要对每个连接维持两个变量:一个拥塞窗口cwnd和一个慢启动门限ssthresh。
- 对一个给定的连接,初始化cwnd为1个报文段, ssthresh为65535个字节。
- TCP输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。
- 当拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半( cwnd和接收方通告窗口大小的最小值,但最少为2个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段(这就是慢启动)。
- 当新的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置的半时候才停止(因为我们记录了在步骤2中给我们制造麻烦的窗口大小的一半),然后转为执行拥塞避免。
慢启动算法初始设置cwnd为1个报文段,此后每收到一个确认就加1拥塞避免算法要求每次收到一个确认时将cwnd增加1/cwnd。
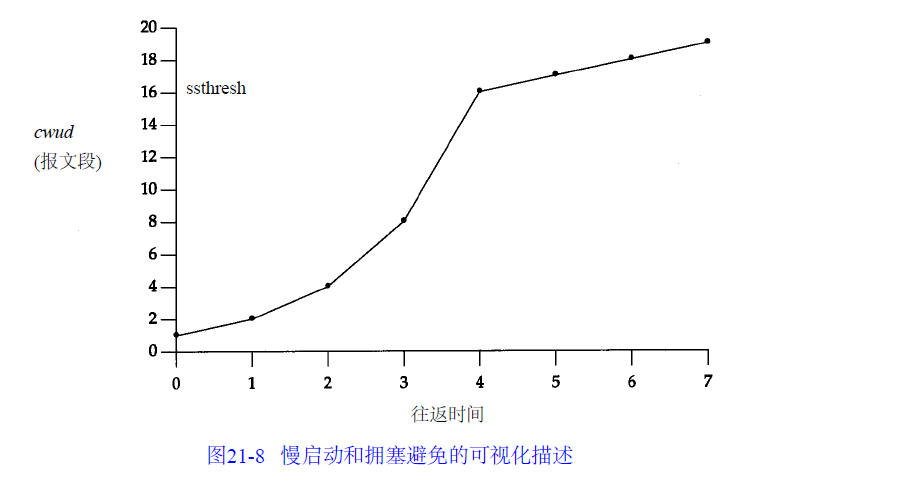
假定当cwnd为3 2个报文段时就会发生拥塞。于是设置ssthresh为16个报文段,而cwnd为1个报文段。在时刻0发送了一个报文段,并假定在时刻1接收到它的ACK,此时cwnd增加为2。接着发送了2个报文段,并假定在时刻2接收到它们的ACK,于是cwnd增加为4(对每个ACK增加1次)。这种指数增加算法一直进行到在时刻3和4之间收到8个ACK后cwnd等于ssthresh时才停止,从该时刻起, cwnd以线性方式增加,在每个往返时间内最多增加1个报文段。
快重传与快恢复算法
在收到一个失序的报文段时, TCP立即需要产生一个ACK(一个重复的ACK)。这个重复的A C K不应该被迟延。该重复的ACK的目的在于让对方知道收到一个失序的报文段,并告诉对方自己希望收到的序号。
不知道一个重复的ACK是由一个丢失的报文段引起的,还是由于仅仅出现了个报文段的重新排序,因此我们等待少量重复的ACK到来。假如这只是一些报文段的重新排序,则在重新排序的报文段被处理并产生一个新的ACK之前,只可能产生1~2个重复的ACK。如果一连串收到3个或3个以上的重复ACK,就非常可能是一个报文段丢失了,于是我们就重传丢失的数据报文段,而无需等待超时定时器溢出。这就是快速重传算法。接下来执行的不是慢启动算法而是拥塞避免算法。这就是快速恢复算法。
这种情况下没有执行慢启动的原因是由于收到重复的ACK不仅仅告诉我们一个分组丢失了。由于接收方只有在收到另一个报文段时才会产生重复的ACK,而该报文段已经离开了网络并进入了接收方的缓存。也就是说,在收发两端之间仍然有流动的数据,而我们不想执行慢启动来突然减少数据流。
这个算法通常按如下过程进行实现:
- 当收到第3个重复的ACK时,将ssthresh设置为当前拥塞窗口cwnd的一半。重传丢失的报文段。设置cwnd为ssthresh加上3倍的报文段大小。
- 每次收到另一个重复的ACK时, cwnd增加1个报文段大小并发送1个分组(如果新的cwnd允许发送)。
- 当下一个确认新数据的ACK到达时,设置cwnd为ssthresh(在第1步中设置的值)。这个ACK应该是在进行重传后的一个往返时间内对步骤1中重传的确认。另外,这个ACK也应该是对丢失的分组和收到的第1个重复的ACK之间的所有中间报文段的确认。这一步采用的是拥塞避免,因为当分组丢失时我们将当前的速率减半。
糊涂窗口综合症
如果发生这种情况,则少量的数据将通过连接进行交换,而不是满长度的报文段。
该现象可发生在两端中的任何一端:接收方可以通告一个小的窗口(而不是一直等到有大的窗口时才通告),而发送方也可以发送少量的数据(而不是等待其他的数据以便发送一个大的报文段)。可以在任何一端采取措施避免出现糊涂窗口综合症的现象。
- 接收方不通告小窗口。通常的算法是接收方不通告一个比当前窗口大的窗口(可以为0),除非窗口可以增加一个报文段大小(也就是将要接收的MSS)或者可以增加接收方缓存空间的一半,不论实际有多少。
- 发送方避免出现糊涂窗口综合症的措施是只有以下条件之一满足时才发送数据: ( a )可以发送一个满长度的报文段; ( b )可以发送至少是接收方通告窗口大小一半的报文段;——主要用来对付通告小窗口 ( c )可以发送任何数据并且不希望接收A C K(也就是说,我们没有还未被确认的数据)或者该连接上不能使用Nagle算法——在有尚未被确认的数据(正在等待被确认)以及在不能使用Nagle算法的情况下,避免发送小的报文段。