对不少 Python 初学者来说,Python 导入其他模块的方式让他们很难理解。什么时候用import xxx?什么时候用from xxx import yyy?什么时候用from xxx.yyy import zzz?什么时候用from xxx import *?
这篇文章,我们来彻底搞懂这个问题。
系统自带的模块
以正则表达式模块为例,我们经常这样写代码:
|
1
2
3
4
|
import re
target = 'abc1234xyz'
re.search('(d+)', target)
|
但有时候,你可能会看到某些人这样写代码:
|
1
2
3
|
from re import search
target = 'abc1234xyz'
search('(d+)', target)
|
那么这两种导入方式有什么区别呢?
我们分别使用type函数来看看他们的类型:
|
1
2
3
4
5
6
|
>>> import re
>>> type(re)
<class 'module'>
>>> from re import search
>>> type(search)
<class 'function'>
|
如下图所示:
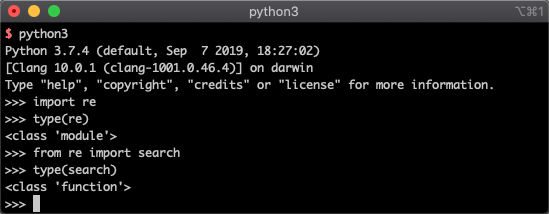
可以看到,直接使用import re导入的re它是一个module类,也就是模块。我们把它成为正则表达式模块。而当我们from re import search时,这个search是一个function类,我们称呼它为search 函数。
一个模块里面可以包含多个函数。
如果在你的代码里面,你已经确定只使用search函数,不会再使用正则表达式里面的其他函数了,那么你使用两种方法都可以,没什么区别。
但是,如果你要使用正则表达式下面的多个函数,或者是一些常量,那么用第一种方案会更加简洁清晰。
例如:
|
1
2
3
4
|
import re
re.search('c(.*?)x', flags=re.S)
re.sub('[a-zA-Z0-9]', '***', target, flags=re.I)
|
在这个例子中,你分别使用了re.search,re.sub,re.S和re.I。后两者是常量,用于忽略换行符和大小写。
但是,如果你使用from re import search, sub, S, I来写代码,那么代码就会变成这样:
|
1
2
3
4
|
import re
search('c(.*?)x', flags=S)
sub('[a-zA-Z0-9]', '***', target, flags=I)
|
看起来虽然简洁了,但是,一旦你的代码行数多了以后,你很容易忘记S和I这两个变量是什么东西。而且我们自己定义的函数,也很有可能取名为sub或者search,从而覆盖正则表达式模块下面的这两个同名函数。这就会导致很多难以觉察的潜在 bug。
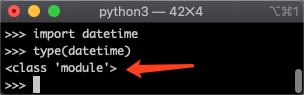
再举一个例子。Python 的 datetime模块,我们可以直接import datetime,此时我们导入的是一个datetime模块,如下图所示:
但是如果你写为from datetime import datetime,那么你导入的datetime是一个type类:
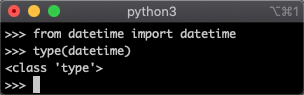
因为这种方式导入的datetime,它就是Python 中的一种类型,用于表示包含日期和时间的数据。
这两种导入方式导入的datetime,虽然名字一样,但是他们的意义完全不一样,请大家观察下面两种写法:
|
1
2
3
4
|
import datetime
now = datetime.datetime.now()
one_hour_ago = now - datetime.timedelta(hours=1)
|
|
1
2
3
|
from datetime import datetime, timedelta
now = datetime.now()
one_hour_ago = now - timedelta(hours=1)
|
第二种写法看似简单,但实则改动起来却更为麻烦。例如我还需要增加一个变量today用于记录今日的日期。
对于第一段代码,我们只需要增加一行即可:
|
1
|
today = datetime.date.today()
|
但对于第二行来说,我们需要首先修改导入部分的代码:
|
1
|
from datetime import datetime, timedelta, date
|
然后才能改代码:today = date.today()
这样一来你就要修改两个地方,反倒增加了负担。
第三方库
在使用某些第三方库的代码里面,我们会看到类似这样的写法:
|
1
2
3
|
from lxml.html import fromstring
selector = fromstring(HTML)
|
但是我们还可以写为:
|
1
2
3
|
from lxml import html
selector = html.fromstring(HTML)
|
但是,下面这种写法会导致报错:
|
1
2
|
import lxml
selector = lxml.html.fromstring(HTML)
|
那么这里的lxml.html又是什么东西呢?
这种情况多常见于一些特别大型的第三方库中,这种库能处理多种类型的数据。例如lxml它既能处理xml的数据,又能处理html的数据,于是这种库会划分子模块,lxml.html模块专门负责html相关的数据。
自己来实现多种导入方法
我们现在自己来写代码,实现这多种导入方法。
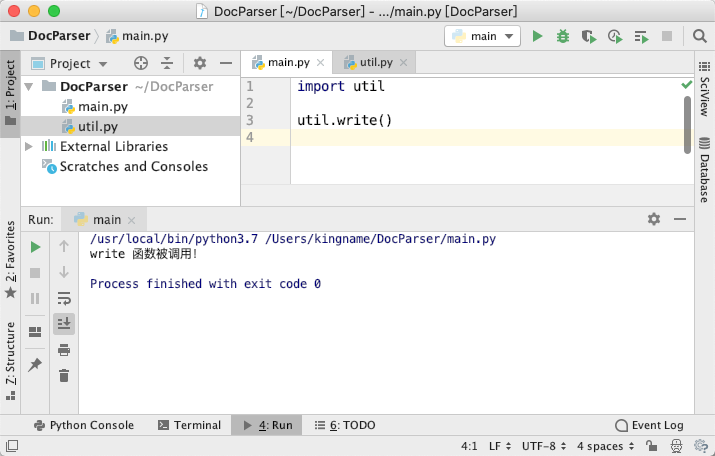
我们创建一个文件夹DocParser,在里面分别创建两个文件main.py和util.py,他们的内容如下:
util.py文件:
|
1
2
|
def write():
print('write 函数被调用!')
|
main.py文件:
|
1
2
3
|
import util
util.write()
|
运行效果如下图所示:
现在我们把main.py的导入方式修改一下:
|
1
2
3
|
from util import write
write()
|
依然正常运行,如下图所示
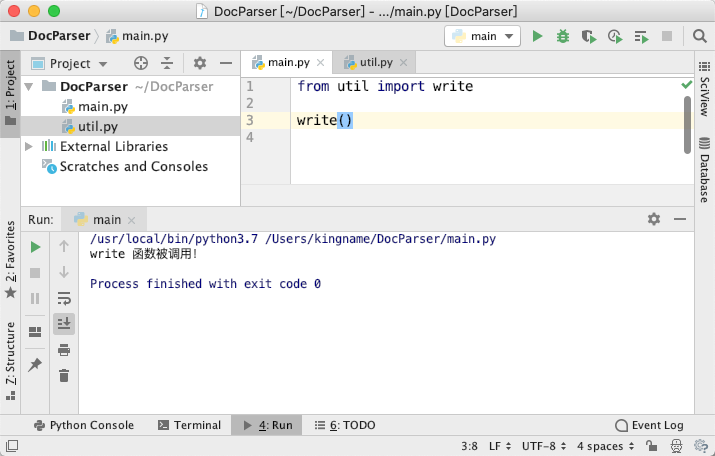
当两个文件在同一个文件夹下面,并且该文件夹里面没有init.py 文件时,两种导入方式等价。
现在,我们来创建一个文件夹microsoft,里面再添加一个文件parse.py:
|
1
2
|
def read():
print('我是 microsoft 文件夹下面的 parse.py 中的 read函数')
|
如下图所示:
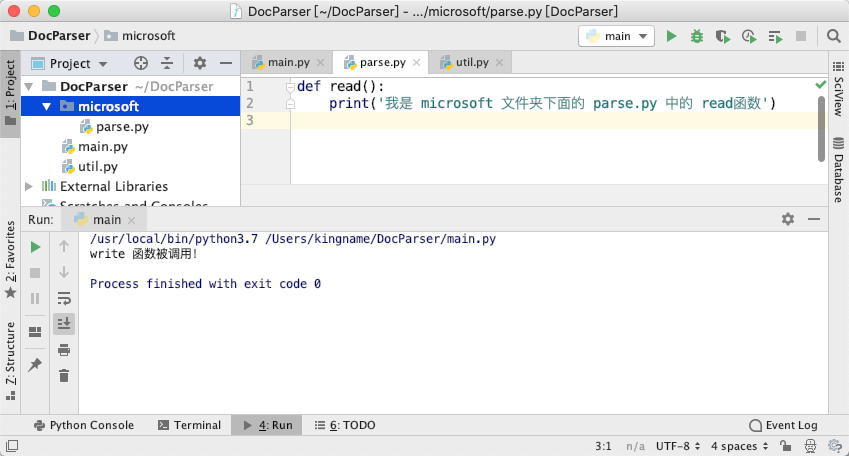
此时我们在 main.py中对它进行调用:
|
1
2
3
|
from microsoft import parse
parse.read()
|
运行效果如下图所示:
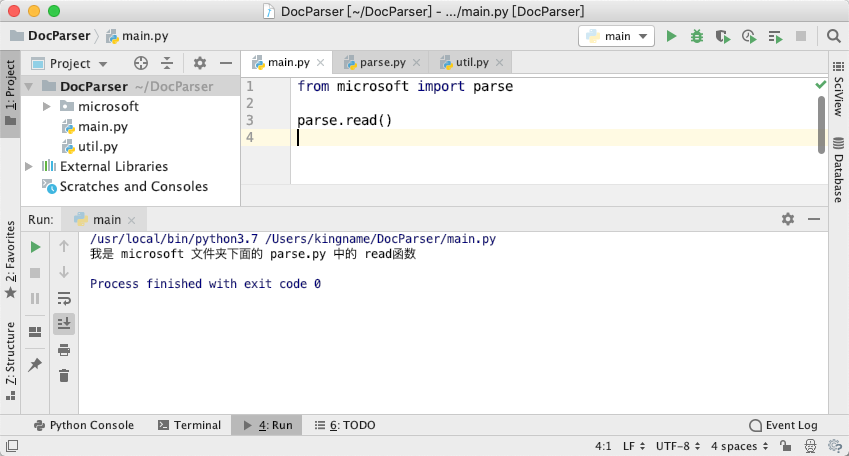
我们也可以用另一种方法:
|
1
2
3
|
from microsoft.parse import read
read()
|
运行效果如下图所示:
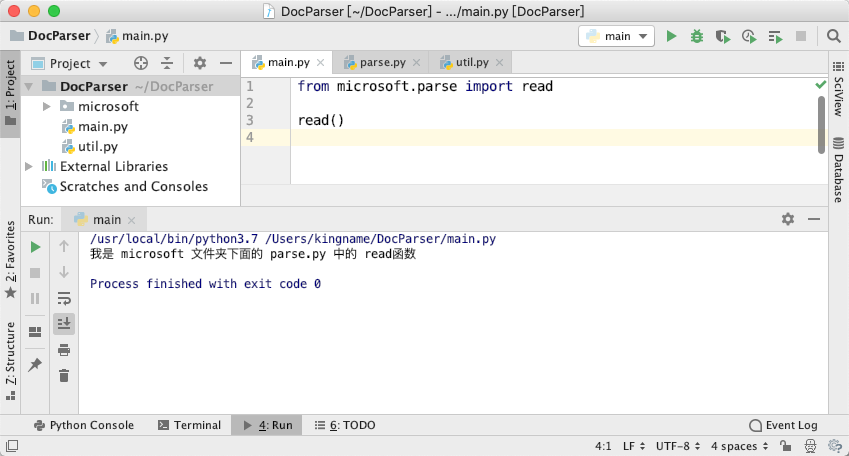
但是,你不能直接导入microsoft,如下图所示:
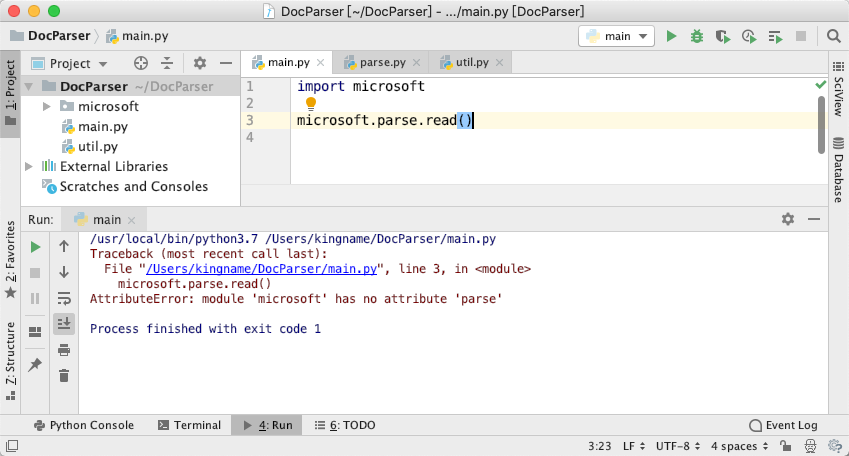
你只能导入一个模块或者导入一个函数或者类,你不能导入一个文件夹
无论你使用的是import xxx还是from xxx.yyy.zzz.www import qqq,你导入进来的东西,要不就是一个模块(对应到.py 文件的文件名),或者是某个.py 文件中的函数名、类名、变量名。
无论是import xxx还是from xxx import yyy,你导入进来的都不能是一个文件夹的名字。
可能有这样一种情况,就是某个函数名与文件的名字相同,例如:
在 microsoft文件夹里面有一个microsoft.py文件,这个文件里面有一个函数叫做microsoft,那么你的代码可以写为:
|
1
2
|
from microsoft import microsoft`
microsoft.microsoft()
|
但请注意分辨,这里你导入的还是模块,只不过microsoft.py文件名与它所在的文件夹名恰好相同而已。
总结
无论是使用import还是from import,第一个要求是代码能够正常运行,其次,根据代码维护性,团队编码风格来确定选择哪一种方案。
如果我们只会使用到某个模块下面的一个函数(或者常量、类)并且名字不会产生混淆,可识别性高,那么from 模块名 import 函数名这没有什么问题。
如果我们会用到一个模块下面的多个函数,或者是我们将要使用的函数名、常量名、类名可能会让人产生混淆(例如 re.S、re.I),那么这种情况下,import 模块名然后再 模块名.xxx来调用会让代码更加清晰,更好维护。
但无论什么情况下,都禁止使用from xxx import *这种写法,它会给你带来无穷无尽的噩梦。
未完待续
在明天的文章中,我们来讲讲还有一种写法from . import xxx,以及当文件夹中存在__init__.py时,导入方式又有什么变化。
转自:微信公众号:未闻code