我们把SQL看成一个大的任务,它由一系列的小任务组成,我们需要优化的就是这些小任务。
我们发送一条sql给服务器,服务器需要做一下操作。
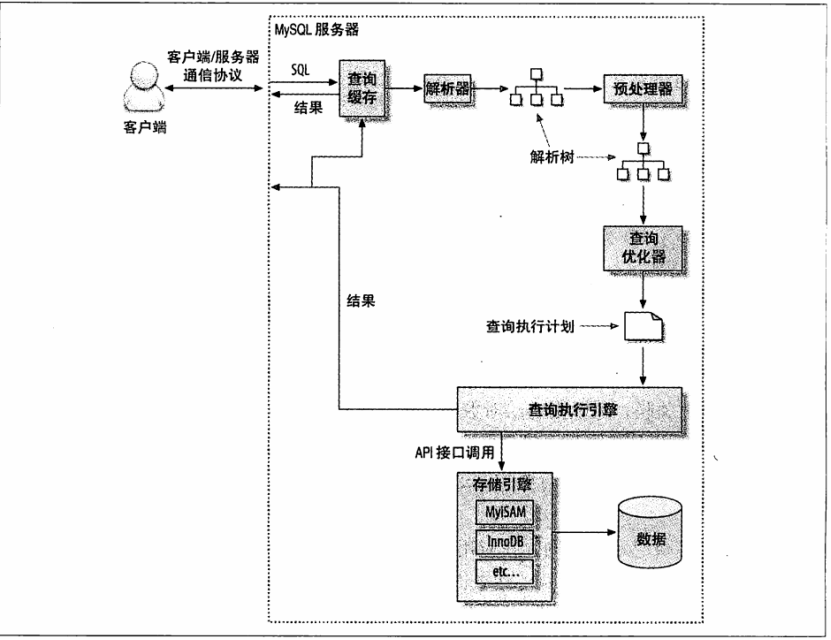
基本步骤:发送sql>查询缓存>解析sql>生成执行计划>执行计划>返回数据(设置缓存)
在执行查询过程中mysql 可以优化一下步骤
1: 重新定义表关联顺序
2: 化外连接为内连接:outer join 语句不都是以外连接的方式执行的,
3: 等价变换 ,移除恒等条件
5== AND a>5 --> a>5
(a<b AND b=c) AND a=5 --> b>5 AND b=c AND a=5
mysql执行关联查询的步骤,
等等...
mysql执行关联查询 原理
mysql认为任意一个查询都是关联查询(包括子查询,单表查询),关联执行的策略是 先在第一个表取出一条数据,再嵌套查询到下一个表寻找匹配的行,依次下去,然后返回上一层表,依次迭代执行。 具体如下图 https://www.cnblogs.com/shengdimaya/p/7123069.html

注意 临时表是没有任何索引的,写子查询和负责关联查询需要注意这一点,因此不要连表太多,第一是数据量大的时候 临时表消耗的IO资源不可小视(表连接越多,搜索空间增长速度急剧增加),第二临时表不具有任何索引,导致查询效率低下。
mysql实现多表关联的图解
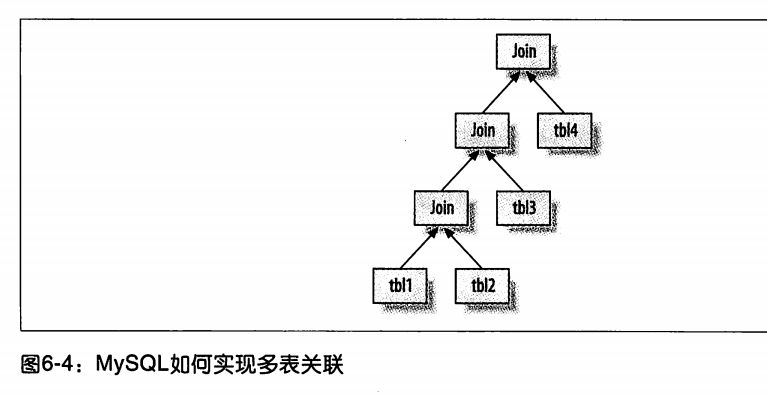
mysql连表顺序并不会安装sql语句来执行的,优化器通过评估不同的顺序成本来选择最小的关联顺序。
mysql返回数据给客户端的过程是一个增量返回的过程,一旦服务器处理了最后一个关联表,服务器就开始返回数据给客户端了。(这样做的好处是1:服务器无需存储太多结果(缓存呢?),2:客户端能尽快获取数据)
查询优化器的局限性
1:关联子查询做的不够好(百度搜索 mysql的子查询效率) where 条件包含IN的子查询的效率, 优化的不够好。(使用关联查询来优化)
2:UMION的优化

1 优化count()
count(1) 和count(*)是一样的,且不忽略null值。
count(col) 忽略null值,
https://blog.csdn.net/lmy86263/article/details/73681633
2 优化关联查询
确保关联列上ON和USING子句的即关联的顺序
3 优化子查询
使用关联查询来优化子查询
4 优化 DISTINCT 和GROUP BY
百度去(mysql 查询性能优化)
5优化LIMIT
limit10000,20的意思扫描满足条件的10020行,扔掉前面的10000行,返回最后的20行