前言:
这次练习完成的是图模型的近似推理,参考的内容是coursera课程:Probabilistic Graphical Models . 上次实验PGM练习四:图模型的精确推理 中介绍的是图模型的精确推理,但在大多数graph上,其精确推理是NP-hard的,所以有必要采用计算上可行的近似推理。本实验中的近似推理分为2个部分,LBP(loop belief propagation算法)和MCMC采样。实验code可参考:实验code可参考网友的:code.
算法流程:
LBP(loop belief propagation)算法近似推理:
(a): 输入factor list F和Evidence E.
(b): 用evidence E掉F中的每个factor, 得到新的F.
(c): 利用F中的factor构造bethe cluster graph,该graph中的factor要么是single的要么是pairwise的.
(d): 按照某种策略选择一条message来发射,并更新message passing前后的MESSAGE矩阵。
(e): 继续步骤(d)直到收敛,收敛是指前后MESSAGE矩阵中的message的val值都非常接近.
(f): 步骤(e)完成后,说明bethe cluster graph已经是calibration的. 求某个变量的边缘概率时,找到该graph中含有该变量的某个cluster,并对其求和积分掉其它变量,最后归一化即可。
Gibbs算法图模型的近似推理过程如下:

由此可知,图摸型的状态指的是所有节点的一个assignment,并不是指单独分析某一个节点。
Metropolis-Hastings(简称MH算法)算法流程如下:
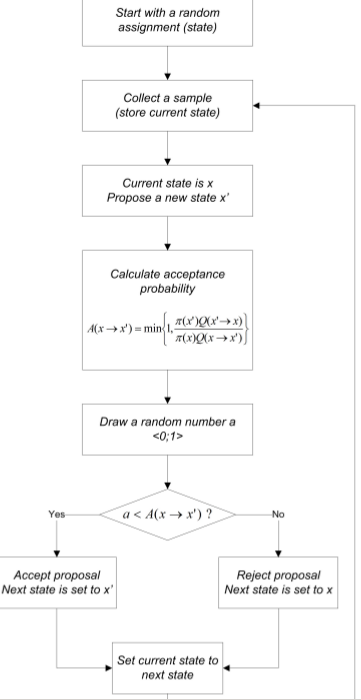
由上面的流程可知,MH算法与Gibbs不同之处在于,它每次更新state时是将图中所有节点都更新,而不是一个个来。其最关键之处是建议分布的设计。
matlab知识:
在matlab中尽量少使用for-loop,因为速度非常慢。
[I,J] = ind2sub(siz,IND):
其中siz是一个线性递增矩阵(从1开始按列递增)的长和宽,IND为需要进行index的向量值。返回的I和J就是这些值所在的行和列。
ind = find(X, k):
找到矩阵X中元素不为0的最多前k个元素,ind为这k个元素的下标(linear indices ).记住find函数找到的是下标index即可。
S = sparse(i,j,s,m,n):
生成一个稀疏矩阵,矩阵中的下标分别存在向量I,j中,对应的值存在向量s中。生成的稀疏矩阵大小为m*n.
n = nnz(X):
算出矩阵X中非0元素的个数。
实验中一些函数简单说明:
V2F = VariableToFactorCorrespondence(V, F):
该函数的作用是找出变量所对应的factor集。其中V就是变量构成的向量,F是所有的factor构成的向量。
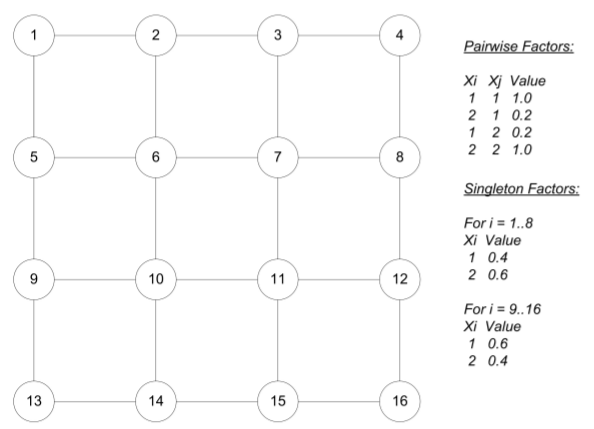
[toy_network, toy_factors] = ConstructToyNetwork(on_diag_weight, off_diag_weight):
该函数的作用是构造一个pair-wise的小网络,网络大小4×4,每个节点都只能取0和1. 网格中每条edge上的2个节点如果取值相同的话,则边的权值大小为on_diag_weight, 反之为off_diag_weight. 返回值toy_network就是所构成的网络结构体,里面包含的成员有names、card、edges、var2factors. 下面是一个toy network的例子:
[i, j] = NaiveGetNextClusters(P, m):
实验1的内容。参数P为cluster graph, 里面包含的变量有clusterList, edges. 参数m表示已经传递了m条消息。I→j表示需要传递的第m+1条消息。按照j下标的升序来选edge.
[i j] = SmartGetNextClusters(P,Messages,oldMessages,m):
另一种选择需要传送message的方法。不过在函数内部参数Messages和oldMessages主要用于smoothing messages和informed message scheduling两种方法,这两种方法都是为了提高BP收敛速度的。这里没有去实现它。课件中有对应的理论。
[i j] = GetNextClusters(P,Messages,oldMessages,m,useSmart):
用参数useSmart来选择上面的两种message passing方法。
P = CreateClusterGraph(F, Evidence):
实验2的内容。用factorlist F来构造cluster graph,这比PGM练习4中构造clique tree要简单很多,因为不要求是tree,且只需edge是两相邻节点交集的子集。Evidence为观察到的变量。返回的P包含clusterList和edges两部分。该函数内部构造的是bethe cluster tree.
converged = CheckConvergence(mNew, mOld):
实验3的内容。该函数是用来判断message passing过程是否收敛,如果message passing前后的message矩阵中所有元素对应的value差值都很小(e-6)时,则代表已差不多收敛。
[P MESSAGES] = ClusterGraphCalibrate(P,useSmartMP):
实验4的内容。和PGM练习4里面的一样,也是找到一条message,然后发送,不同的是,PGM练习4中message passing的次数固定了,而这里其次数需达到cluster graph收敛的次数才行。
M = ComputeApproxMarginalsBP(F,E):
实验5的内容。利用LBP算法进行对变量的条件概率进行近似推理。具体过程见前面的LBP算法流程。
LogBS = BlockLogDistribution(V, G, F, A):
实验6的内容。V为需要计算条件概率的变量集(如果在Gibbs情况下,则一般每次只取一个变量,此时V的长度就为1; 如果长度不为1,则需它们之间的值是相同的),每个变量的取值范围必须一样,G为cluster graph,F为factorlist,A为当前graph的一个assignment. 该函数的作用是计算V中每个变量的log条件概率值. 计算依据如下:
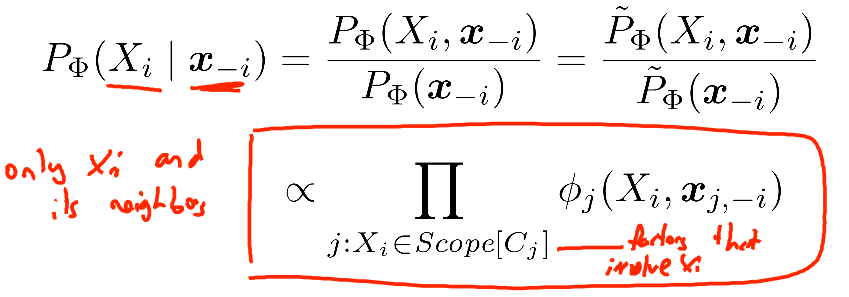
由上面的公式可知,采样Xi时只将与包含Xi的那些factor相乘(不考虑归一化时).同时,程序中为了防止数值下溢(numerical underflow)问题,上面值的计算将在log空间进行。
[v] = randsample(vals,numSamp,replace,weightIncrements):
该函数实际上完成的是一个多项式分布采样。其中参数vals一般表示采样的最大值,numSamp表示需要采样的样本数。weightIncrements表示多项式分布的区间(因为是用0~1之间的随机数来投票).但GibbsTrans()一直通过不了测试,课程老师说matlab 2012后的版本都不行,是个bug。但从函数内部的代码也没看出有和matlab版本相关的代码,所以只要用到这个函数的,提交答案时都通过不了。下面是PGM课程团队在新的实验教程中对bug的提示:

A = GibbsTrans(A, G, F):
实验7的内容。转移矩阵采用Gibbs方法。A为图G的一个assignment, F为factorlist.该函数的作用是从当前的A得到下一个assignment,也保持在A中。内部调用函数BlockLogDistribution()得到了其分布,然后使用randi()函数实现多项式的随机采样。
M = ExtractMarginalsFromSamples(G, samples, collection_indx):
参数G仍为graph, sample为采样到的所有样本(包括mix-time前面的样本), collection_indx为samples中用于inference样本的下标。输出M为每个样本的margin值。内部实现很简单,其实就是求估计变量的概率,用符合要求的样本个数除以样本总数。
E2F = EdgeToFactorCorrespondence(V, F):
算出图中每条edge所对应的factor编号。
[M, all_samples] = MCMCInference(G, F, E, TransName, mix_time, num_samples, sampling_interval, A0):
实验8和实验12的内容。MCMC的接口函数。其中的G、F、E与前面的一样;TransName代表MCMC转移矩阵的类型; mix_time表示分布达到稳定前的时间。num_samples为所需sampling的样本。sampling_interval为采样间隔,一般都设置为1. A为Markov Chain的初始状态,即初始的assignment. 该函数输出值M求的就是每一个变量的条件概率,是调用函数ExtractMarginalsFromSamples()来实现的。
ogp = LogProbOfJointAssignment(F, A):
求出assignment A与F中所有相关factor对应var处的乘积,就是联合概率。这个乘积与MH算法公式:

里那个分子分母有关,如果A为当前时刻的,则logp值为公式中的分母;如果A为状态转移得到的下一时刻,则lopg为公式中的分子。为什么这里2个会与实验教程公式1中相对应呢?主要是因为公式中的转移矩阵T此时为1,直接可以约掉。另外因为公式中是相除,所以概率值不用归一化。
A = MHUniformTrans(A, G, F):
实验9的内容。转移矩阵采用MH方法。同样是从当前的assignment得到下一个assignment,只不过这里采用的是均匀分布取下一状态. 内部可采用类似的LogProbOfJointAssignment()思想实现。
[sci sizes] = scomponents(A):
生成的sci,sizes是2个列向量。其中的sci是返回的每个顶点所对应连通区域的标号, sizes是对应连通区域中元素的个数。
A = MHSWTrans(A, G, F, variant):
实验10和实验11的内容,实现MH转移概率。采用Swendsen-Wang建议分布的MH算法。该算法有2种建议分布类型, 两者的主要不同之处体现在状态转移概率那里。下面是Swendsen-Wang状态转移的示意图:
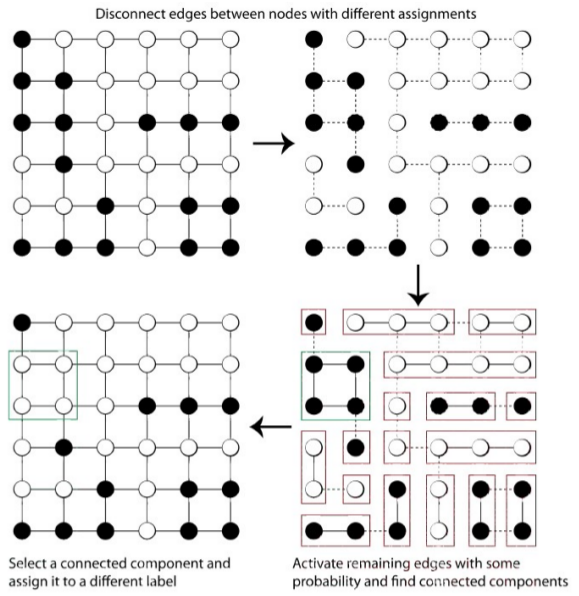
由图可以看出,其转移过程主要有下面几个步骤:
- 对graph随机取一个初始状态;
- 将graph中不同值两节点之间的边断开,这样相同值的节点就构成了一个个小连通图;
- 将上面得到的每个小连通图中的每条边以概率(1-qij)随机断开,这样就得到了更多小小连通图;
- 以均等概率选取图中的一个小连通图,并将该小图记为Y;
- 以R概率分布对Y中节点值进行改变,不管是改变前还是改变后,Y中所有节点的值都是一样的;
套用公式1中的MH理论,此时建议分布为:

两个的比为:
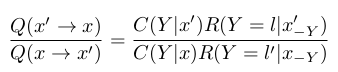
其中记:
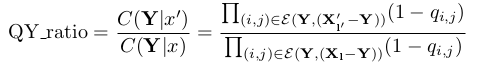
而练习中的2个Swendsen-Wang算法不同主要体现在qij选取不同以及R分布的不同。算法2中的qij计算公式为:

其R采用的是BlockLogDistribution.m中的方法。
相关理论知识点:
LBP算法不仅限于clique trees,它对任意的cluster graph都适应。只不过是不同的cluster graph的收敛速度和精度不同。由于cluster graph中有feedback环,所以它只能用于近似推理。在LBP算法中,message passing order并没有严格要求,不用规定root节点。
如果给定样本(IID样本)后,则可以利用这些样本来估计一些统计量,且由Hoeffding Bound和Chernoff Bound理论保证,当样本数越多时,其估计越准确。Hoeffding Bound也称为additive bound, Chernoff Bound被称为Chernoff Bound.
如果给定统计量估计的错误率,则由这2个bound都可以计算出小于该错误率所需的最小样本数。
两个bound虽然存在,但是作用不大,因为有些统计量需要的样本数呈指数增加。
对BNs进行forward sampling比较简单(网络参数给定的前提下),先sampling父节点,然后sampling子节点。如果已知某些变量的观察值,则直接将那些不符合观测值的样本点去掉即可。
Forward sampling不适用于Mns.
Regular Markov Chains是指任意两个状态之间都有连线,并且每一个状态都有自己的一个环(self-transition).
不管初始化状态如何,Regular Markov Chains都收敛于一个唯一的稳定分布(离散的话则是多项式分布),对这个分布进行采样比较简单。
如果某个分布P的样本不好直接采样,则我们可以构造一个Regular Markov Chains T,使得T的稳定分布就是分布P,这样从T上采样就可得到P的样本。
mixing: Regular Markov Chains达到稳定状态时则称为mixed. 但是很难证明Regular Markov Chains是否已mixed,顶多能验证它有没有mixed. 采用MC sampling方法的难点就在于对mixed状态的判断。一般可从多个不同初始状态值出发,对chain采用窗口计算一些统计量,通过可视化这些统计量来判断。
即使Regular Markov Chains已经mixed,稳定分布下连续采样得到的样本也是相关的,并不属于IID,所以这些样本不能直接用于统计推断。按照经验来说,如果Regular Markov Chains收敛速度越快,则这些相邻样本的相关性越弱,也就越趋于IID,越有用。
前面的sampling都是假设我们已经构造好了P所对应的Regular Markov Chain. 那么到底该怎样来构造呢?对应有很多的理论。不过对于PGM中的两种模型BNs和MNs而言,已有理论证明:对Gibbs chian的采样过程是可行的。
如果graph中所有的factor都是positive的,则Gibbs chain是regular的。并且Gibbs chain采样某个元素值时只与该元素所在的factor有关,与其它factor无关。当然,前提是我们知道怎样从这些factor中来采样。
精确推理在general networks上是NP-hard的。
Reversible Chains: 满足细致平衡的chain. 细致平衡是指当前状态为x,且下一状态为x'的概率与当前状态为x', 且下一状态为x的概率相等。
构造分布P对应的MCMC链的一个通用的理论框架是MH(Metropolis-Hasngs)算法(Gibbs也属于MH算法的一种)。
MH框架下需要一个建议分布Q,以及一个接受率A。该建议分布必须是reversible的。为了缩短mix time,Q应该越宽越好,但是如果太宽则接受率又会过低。
一般来说,当graph越稀疏就越适合用message passing的方法来inference,如果越dense,则越适合用sampling的方法。
为了使inference更准确,message passing方法中应该使cluster graph 中的cluster更大;在sampling方法中应该使建议分布每次转移覆盖更多变量。
参考资料:
Daphne Koller,Probabilistic Graphical Models Principles and Techniques书籍第12章