(一)flume的产生
为什么会有flume
随着互联网的发展,人们对网络日志产生的信息也越来越重视。不仅如此,我们的服务器,比如Nginx,每天都会产生大量的日志。我们要将这些日志收集到指定的地方,比如hdfs平台,进行分析。但是大量的日志产生的位置比较分散,可能来自于Tomcat、Nginx、甚至是数据库等等,而且存储的目的地也不一样,这就导致了数据采集的复杂性。然鹅最关键的问题是,如果在采集的过程中,出现问题了该怎么办?比如我们要把日志收集到hdfs平台上进行分析,我们可以通过hdfs shell的方式,但是我们无法对日志采集的状况进行监控。针对以上种种问题,flume就诞生了,因此看到这里小伙伴也能猜到flume是干什么的了。
flume是什么
关于flume是什么?官网给出了定义,我们来看一下。因为flume是Apache的一个顶级项目,所以官网就是flume.apache.org
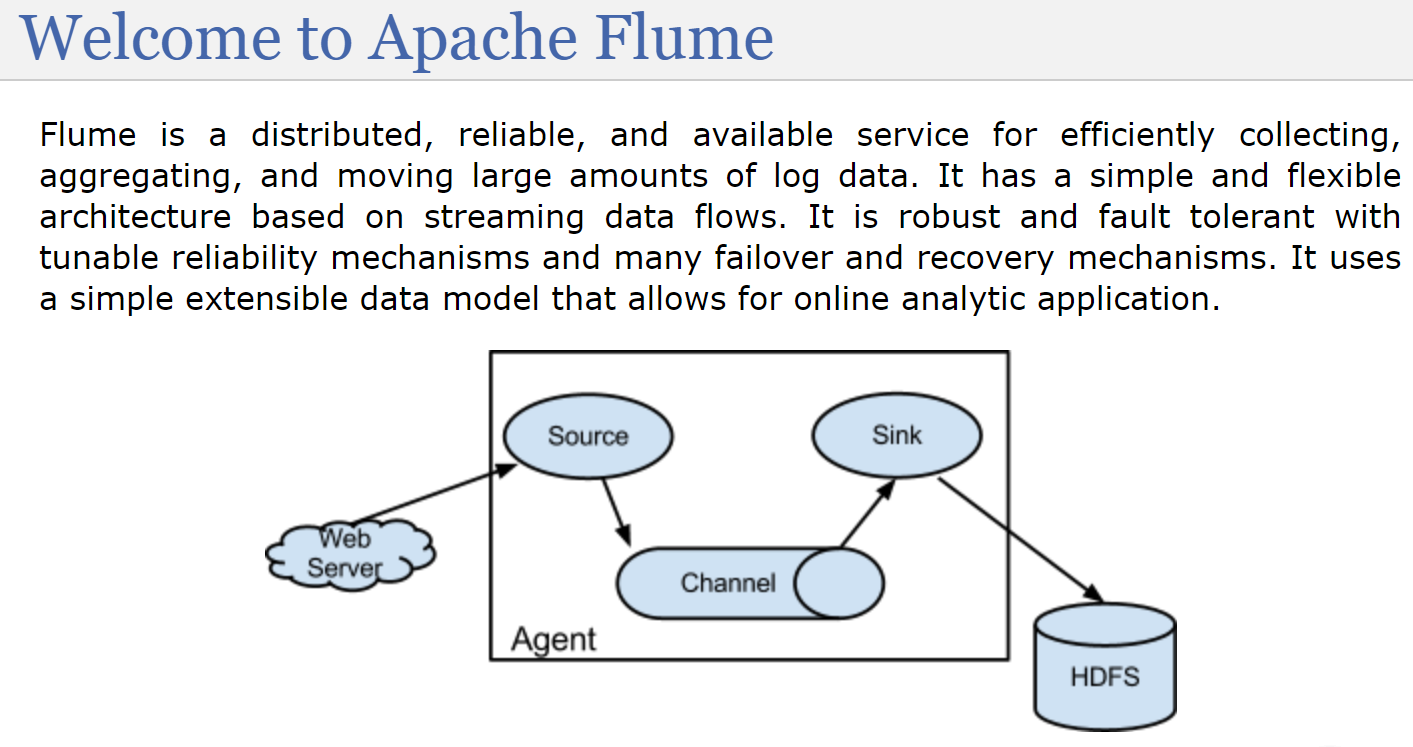
flume是一个分布式、高可靠、高可用的服务,用于高效地收集、聚合、移动大量的数据集。flume具有一个简单、灵活并基于数据流的架构,它具备可调节的可靠机制和许多故障转移以及恢复机制,并具有很强的健壮性和容错性。通过使用一种简单可扩展的数据模型来提供应用程序的在线分析。
我们从图中,可以看到一个长方形,里面围住的部分就是flume的一个agent。我们通过flume移动数据就相当于在写一个配置文件。source:源。表示我们要从哪里收集,比如这里来自于web服务器。sink:下沉。表示我们要把数据沉到什么地方去,这里是hdfs。那么中间还有一个channel是干什么的呢?channel:管道,我们不会把刚收集到的日志立刻sink到hdfs上面,那样效率太慢,而是会先存到channel里面,这个channel就是消息队列,一般是kafka,当管道满了,然后再把管道里面的数据一次性sink的目的地,这里是hdfs。
因此通俗一点的说:
flume就是一个日志采集工具,或者理解为一个搬运工,将日志从一个地方搬到另一个地方去。特征是:具备高可用、高可靠、分布式处理模式。里面定制了很多的source和sink,支持我们从不同的源端读取日志文件,然后sink到不同的地方去。
flume的特征
-
flume可以高效率地从多个服务器中收集日志并存储到hdfs/hbase中
-
除了日志信息,flume也可以用来接入收集规模宏大的社交网络节点事件数据,比如Facebook、Twitter等等
-
支持各种不同数据源,并能够输送到不同的地方
-
支持多路径,多管道输入,多管道输出,上下文路由等等
什么意思呢?意思就是我们sink的时候,也可以作为下一个agent的source,不一定要是hdfs等平台,并且多个sink还可以到同一个source里面。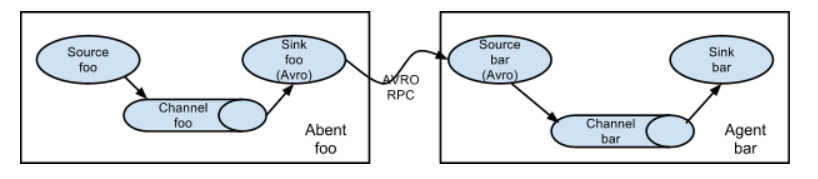
同理,一个source也可以到多个channel,然后sink到多个地方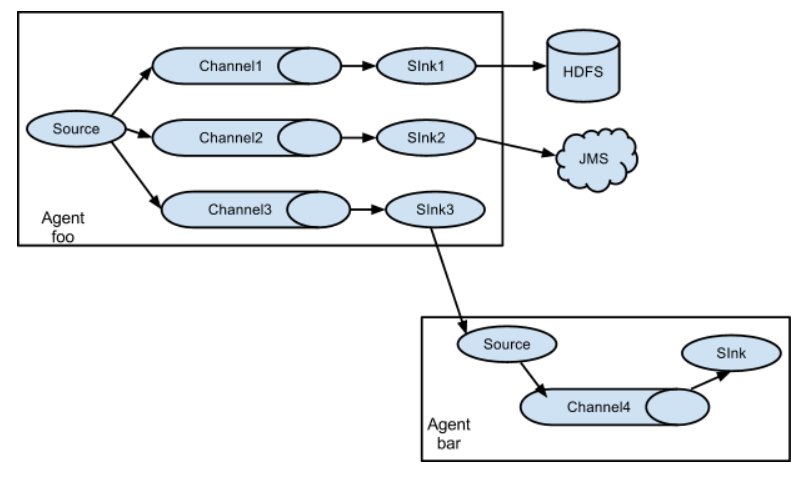
-
可以水平扩展
flume的应用场景
flume其实还可以有其他的功能,比如数据的处理,但是在大数据实际应用中,flume基本上只用于日志收集工作,根据不同的业务场景,编写不同的配置文件。
(二)flume的client
flume的客户端
什么是flume的客户端呢?实际上,部署flume的机器就可以称之为一个客户端。部署flume,是不是需要一些环境呢?
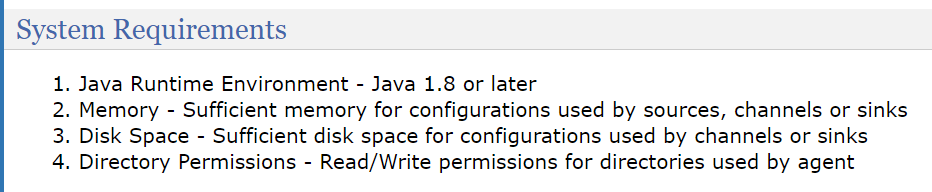
根据官网的要求,至少要满足以下几点
- 1.jdk1.8或更高,大数据的这些组件都和java脱不开关系
- 2.内存。因为flume是基于流式的,因此内存也是必须的
- 3.磁盘空间,我们不会把数据一直保存到内存里面,最终要刷到磁盘上,因此磁盘空间也是必须的。
- 4.目录权限,你要往一个目录里面写文件的话,总要有写或者读的权限吧
感觉2、3、4都是废话,这不是显然的吗?
(三)flume的source
我们之前说过,一个agent就相当于一个配置文件,里面有三剑客,分别是source、channel、sink。通过编写配置文件,配置source、channel、sink,来将数据从一端传输到另一端。
我们来看看source。
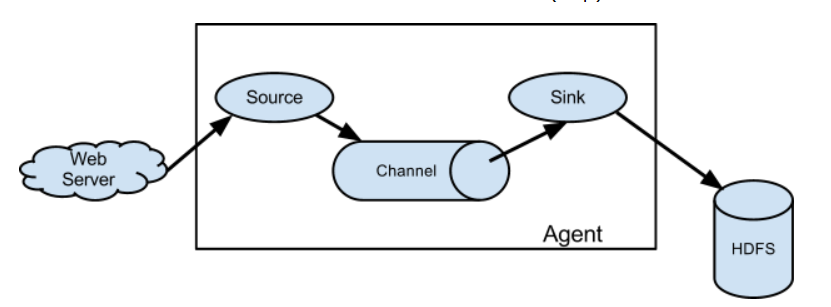
source就是我们的源端,从不同的数据源读取日志信息放到channel里,然后sink取出channel里面的日志信息到其他的地方,比如hdfs、hbase等等。
因此flume的架构很好理解,就这三个组成部分。既然flume的source支持不同的数据源,那么我们就来看看,它都支持哪些不同的数据源呢?
source支持的数据源
支持以下几种source
-
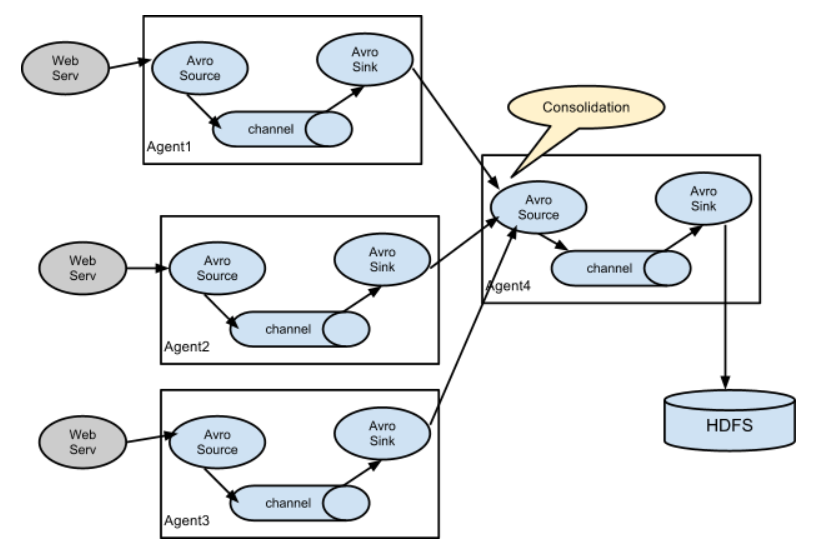
Avro Sourceflume第一种数据来源,可以监听IP和端口,并不一定是本机的IP,可以监听其他机器的IP和port,用于获取数据。从外部的Avro client streams接收events,当与另一个flume agent内置的avro sink配对时,可以创建分层搜集的拓扑结构。感觉官网说的好阳春白雪,其实说白了,还是下面这张图,一个agent的source可以是上一个agent的sink,之间通过avro去连接

字体加粗的属性必须进行设置
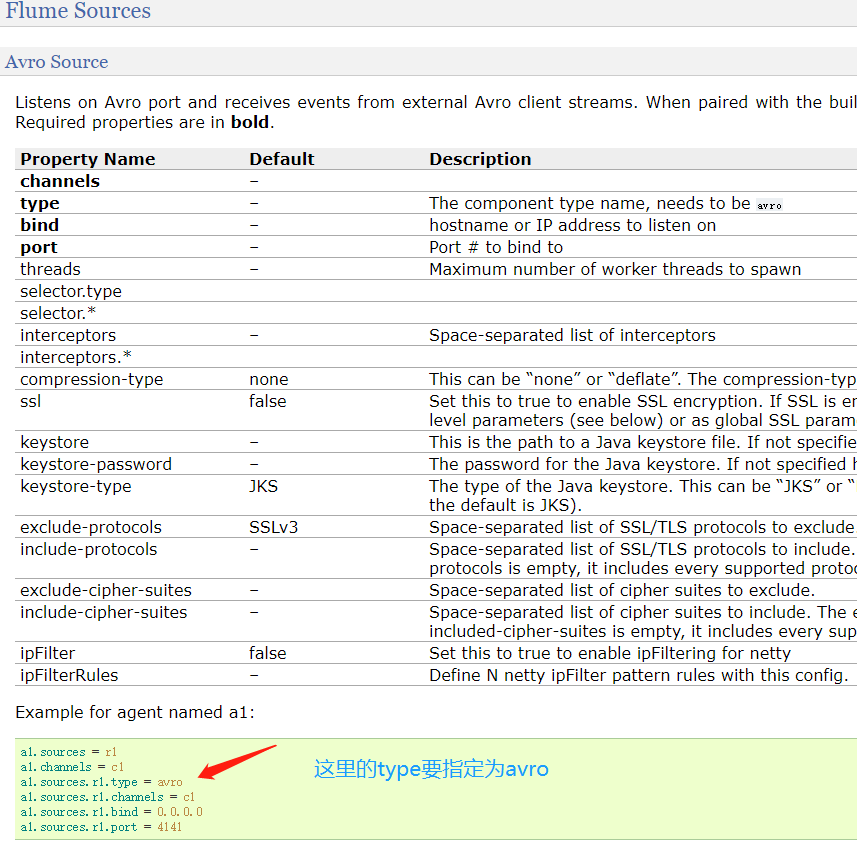
因为source的类型是avro,因此type也要指定为avro -
Thrift Source和avro source基本类似,但是avro可以支持ip过滤,但是thrift不支持。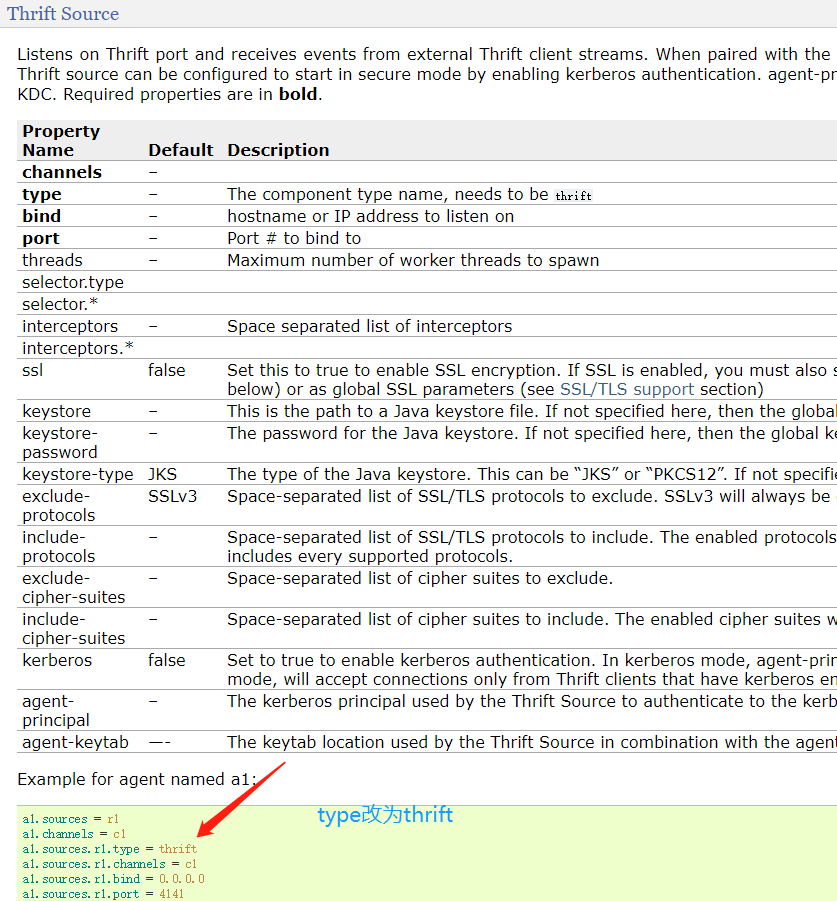
因为source是thrift,所以type要改成thrift。是什么样的source,那么type就改成什么。
-
Exec Source比较常用的一种source,可以运行Unix命令,然后该命令会一直执行,读取文件,作为flume数据的来源,需要配置相应的channel、type、以及运行的命令。并且根据官网介绍,本方式不保证数据百分百会传送到指定的位置,如果出现问题,数据可能丢失。可以使用Spooling Directory等其他手段,保证数据传输
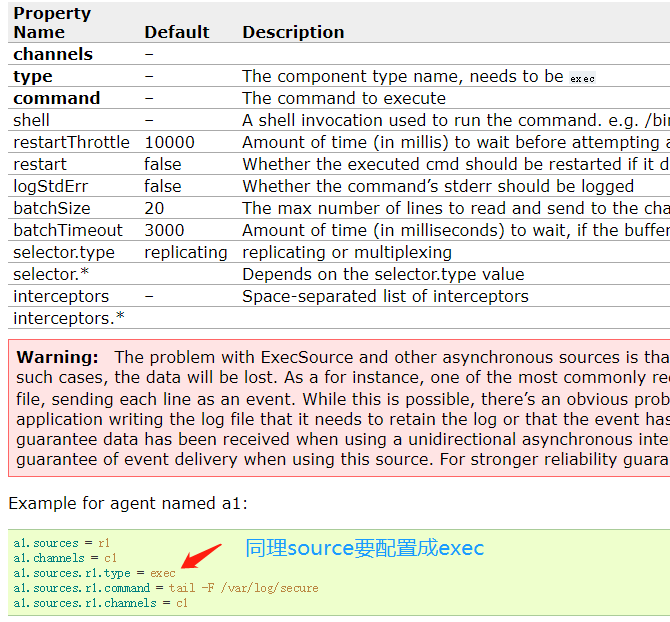
-
JMS Source本方式会从JMS消息队列的目的地,比如一个队列或者一个topic中读取数据;需要在plugins.d即插件目录下放置相应的jar包;不过此来源一般用的较少,因为局限性比较强。
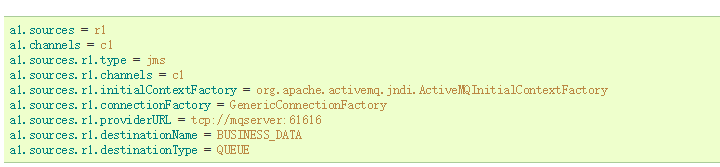
-
Spooling Directory SourceSpooling Directory Source监测配置的目录下新增的文件,并将文件中的数据读取出来。其中,Spool Source有2个注意地方,第一个是拷贝到spoolDir指定的目录下的文件不可以再打开编辑,第二个是spool目录下不可包含相应的子目录。这个主要用途作为对日志的准实时监控。
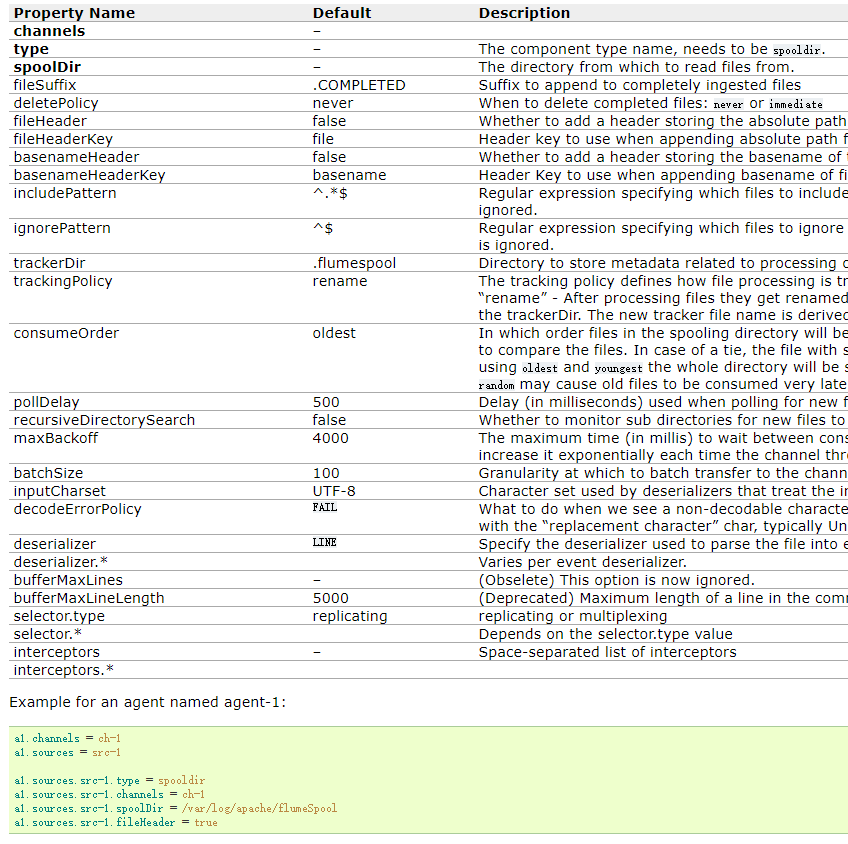
加粗的表示必须填写,其中spooldir,就是我们指定的目录,当然type也要指定为spooldir
-
自定制source其实flume提供的source还是不能完全满足我们的需求,因此我们也可以自定义source。
当然还有其它source,不过不常用。这里可能有点抽象,先来清楚一下概念,了解一下flume的架构、各个组成部分的功能,后续会进行演示
(四)flume的channel
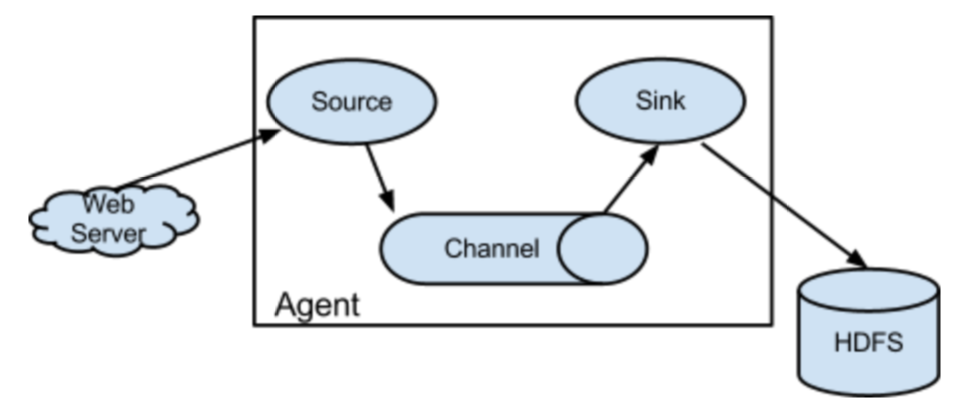
还是这张放了好几遍的图,source我们已经介绍过了,下面介绍channel。
channel我们其实我们之前也说过了,是一个管道,类似于golang里面的channel。或者我们把它理解为一个缓存也行,source收集过来的日志并不直接sink到hdfs上面,而是会放到缓存里面,等缓存满了再一次性sink到指定的地方。
为什么要这么设计呢?介绍source收集日志的速度很快,但是sink的速度很慢,如果source直接对接sink的话,那么就会导致读写速度不一致了,这就跟双十一要引入消息队列一样,如果上游的订单系统直接对接下游的库存系统,那么上游爆发的流量很容易将下游冲垮,所以才需要引入消息队列进行削峰填谷,两者的道理是类似的。
关于缓存,有两种。一种是基于内存的缓存,另一种是基于磁盘的缓存。
基于内存的缓存:速度快,但是不安全,而且容量有限
基于磁盘的缓存:可靠性高,容量大,但是读写速度会慢一些。

flume官方为我们提供了如下channel
基于内存的channel,我们很少使用,因为数据容易丢失。File channle和kafka channel很常用
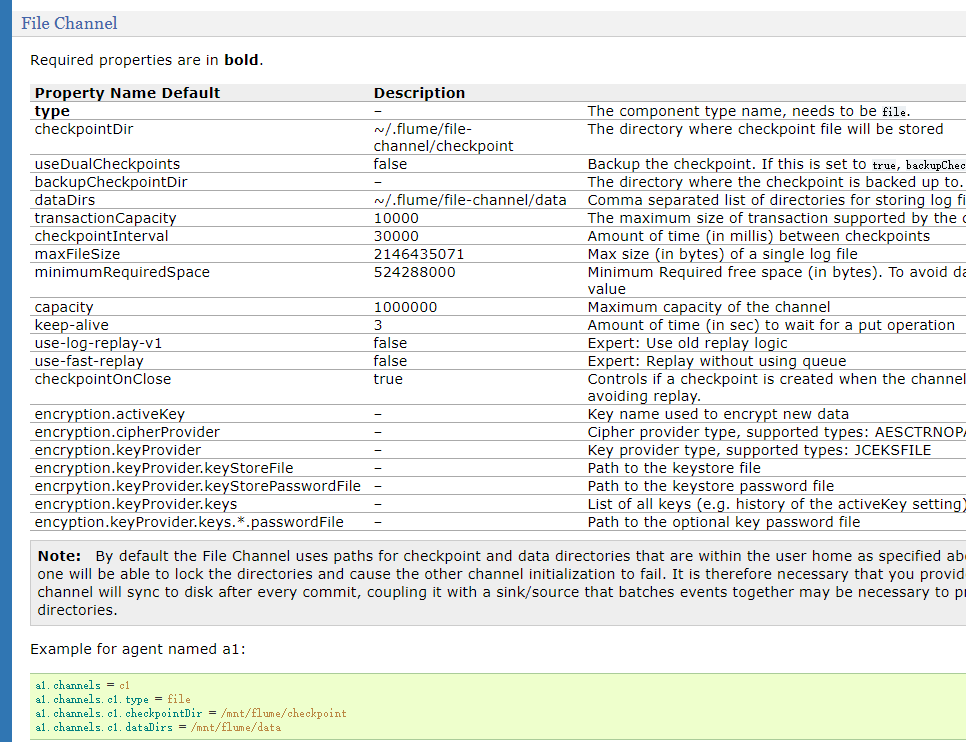
比如file channel,那么这里的type要指定为file,因为这里的缓存使用文件来实现的。配置的话可以指定大小
(五)flume的sink
我们之前说过,source是用于收集数据,channel是用于缓存数据,sink是用于将数据写到外部的存储设备。那我们外部的存储设备不一样,那么sink的类型就会不一样,因此sink实际上也是可定制的,可配置的。对于不同的外部地址,那么sink就有不同的实现。
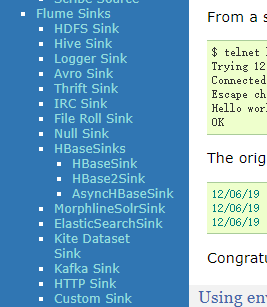
flume也为我们提供了很多sink,比如hdfs sink、hive sink等等。当然还有avro sink,这个在之前介绍过,是为了对接下一个agent的avro source

当然每一个sink都有很多额外的配置,比如文件的前缀啊、回滚间隔、回滚策略啊等等
(六)flume的interceptor
flume的拦截器,这是什么?

flume可以在移动数据时修改/删除事件,这是在拦截器的帮助下完成的。所有的拦截器都是实现了org.apache.flume.interceptor.Interceptor接口的类,拦截器可以基于开发人员所选择的任意条件来修改、甚至删除事件。并且flume还支持链式的拦截器(补充:意思就是可以设置多个拦截器,然后顺序的调用。),这可以通过在配置中指定多个拦截器的类名组成的列表来实现。拦截器在源配置中通过一系列的空格进行分隔,拦截器被指定的顺序也是它们被调用的顺序,每一个拦截器所返回的事件在列表中会链式的传递到下一个拦截器,并且可以修改或者删除事件。如果一个拦截器需要删除事件,那么它只需要在列表中将该返回的事件不进行返回即可。如果要删除所有事件,只需要简单地返回一个空列表即可。拦截器是一个命名组件,以下是如何通过配置创建拦截器的一个例子。

拦截器主要用于source端,我们可以将获取的数据拦截下来,然后加上一个键值对,可以指定文件的名字、来源、时间戳等等,然后sink到不同的地方去。比如我们 收集了很多日志,比如登陆日志、行为日志等等,那么我们在拦截的时候,便可以指定哪些日志都是什么类型,然后输出的时候,不同的日志输出到不同的地方去
(七)flume的selector

我们的source在收集完数据之后要写到哪一个channel里面呢?比如我们搜集的日志有三种,一种是只包含字母,另一种只包含数字,最后一种只包含符号(假设是这样蛤)。hdfs上面有三个文件,正好对应三种日志类型。现在我们的问题是,不同类型的日志怎么存到不同的文件里面去呢?既然要存到不同的文件里面,那么首先要存到不同的channel里面,channel1只包含字母、channel2只包含数字、channel3只包含符号,然后sink1对接channel1、sink2对接channel2、sink3对接channel3,理论上情况是这样的。
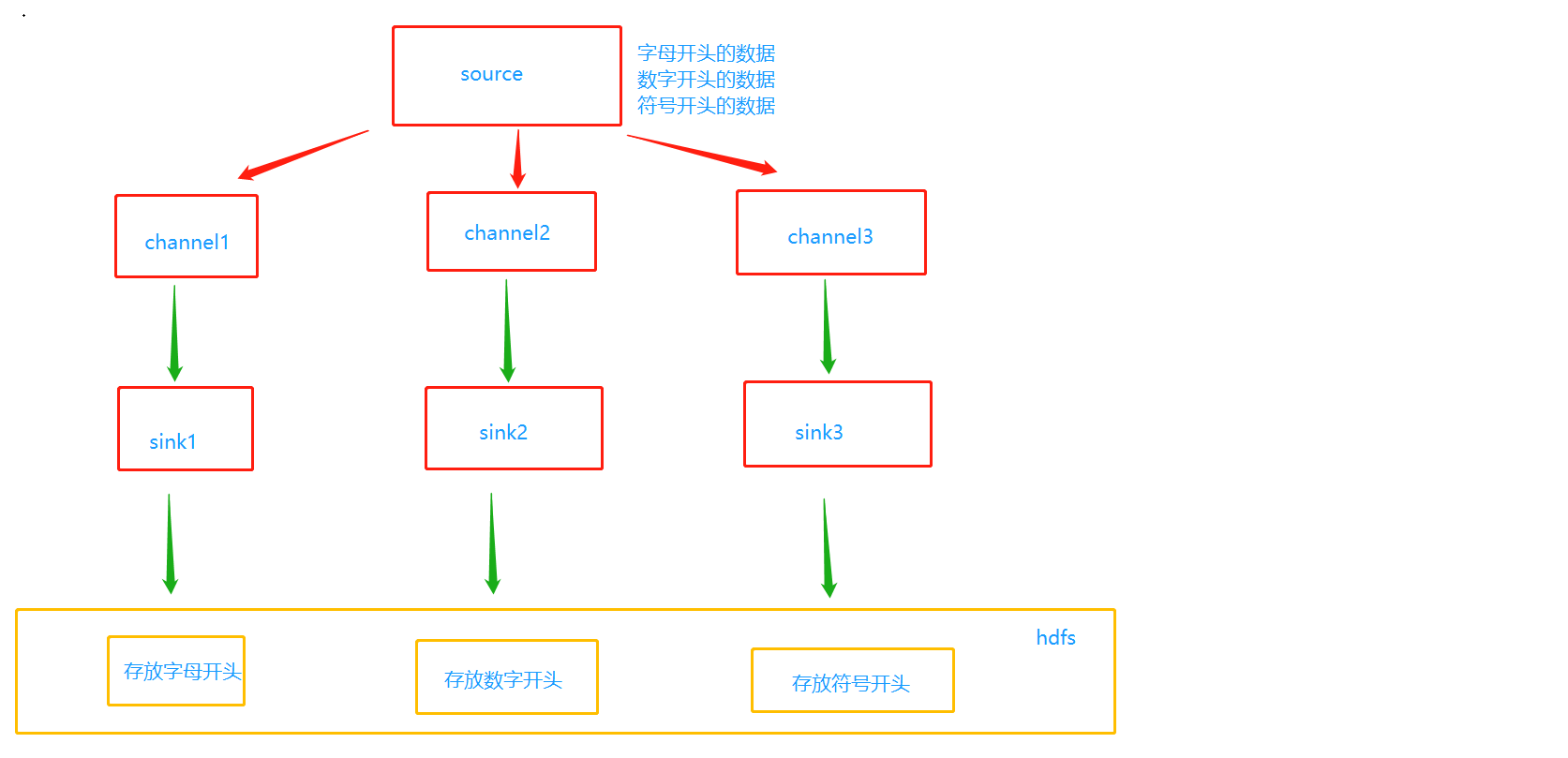
但是现在问题又来了,怎么存到不同的channel里面呢?这个时候选择器就出现了
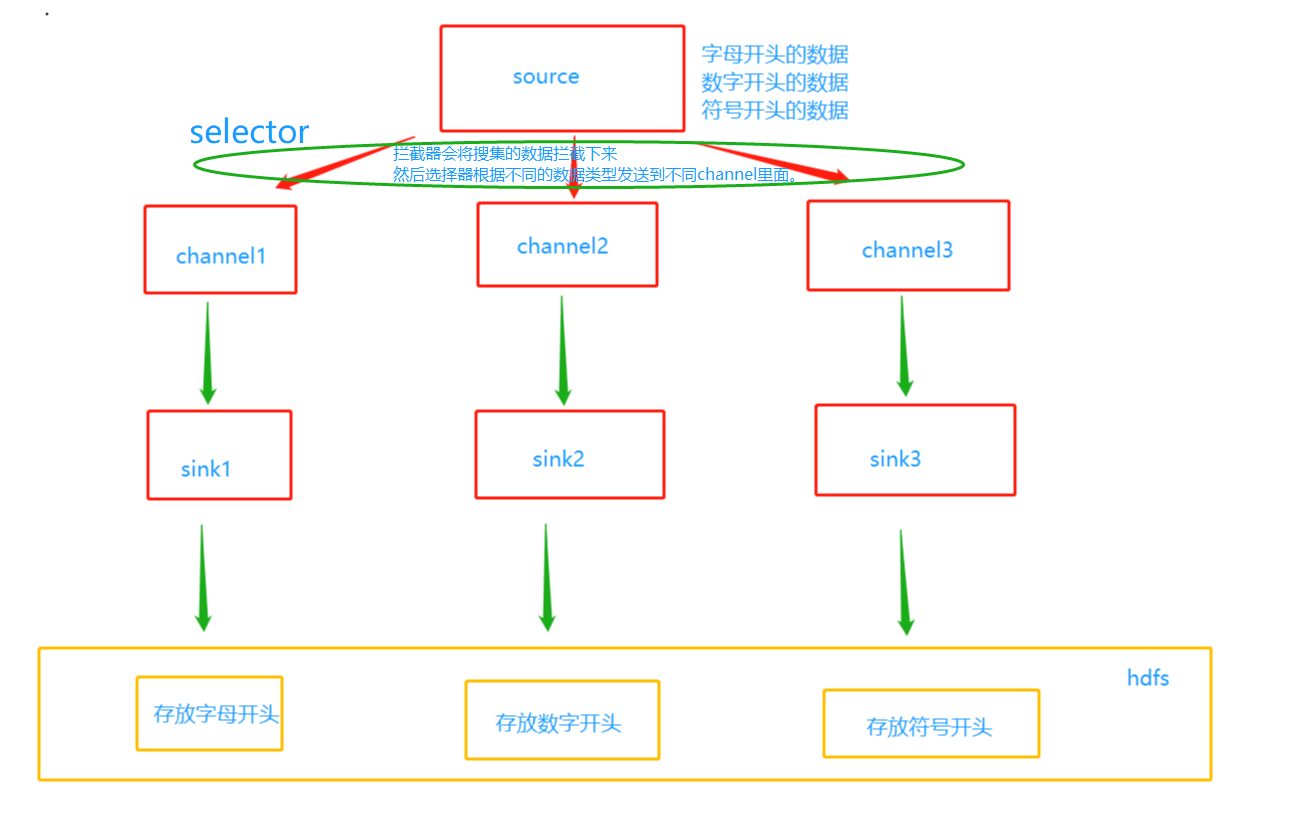
官网提供了哪些selector呢
-
Replicating Channel Selector (default)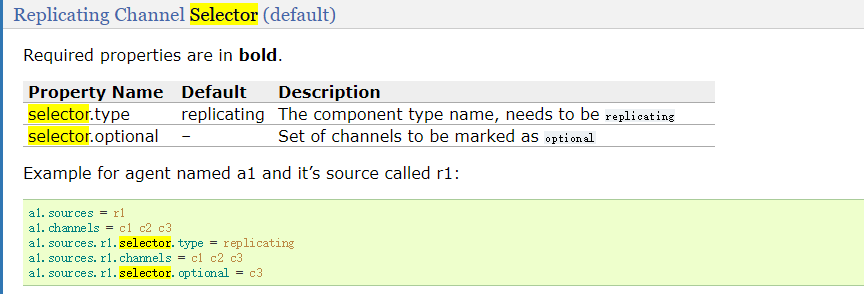
这也是默认的channel,type指定为replicating。意思是数据会复制到每一个channel中。 -
Multiplexing Channel Selector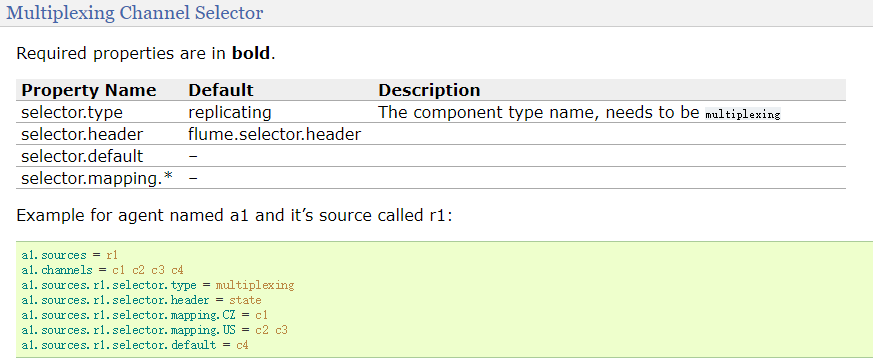
复分模式的channel,不会把数据拷贝了,而是将数据整体分发到不同的channel中,当然要指定type为multiplexing。可以看到不管是source、channel、sink还是这里的selector,都有不同的类型,然后在各自的type中指定即可。 -
Custom Channel Selector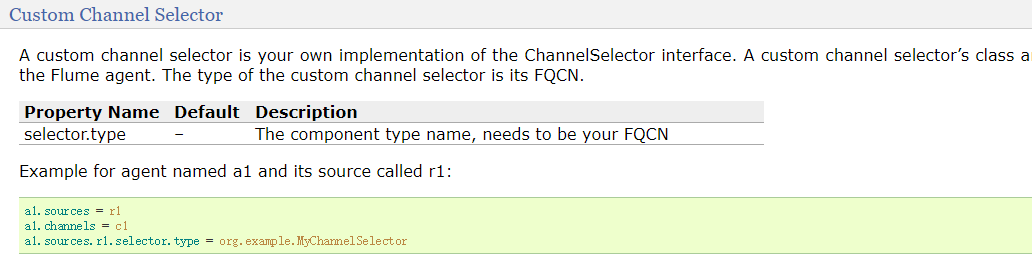
自己实现的channel,不同的数据分发到不同的channel中,相当于对Multiplexing Channel Selector进行了自定制,这样就可以按照我们自己的逻辑来决定数据分发到哪一个channel当中。
(八)flume的event
例如一些消息队列,发送的数据并不是原生的数据,而是对数据要进行一个封装,我们可以通过python往activemq里面发送数据,然后使用golang去接。但是python最终发到mq里面不是一个简单的数据,golang接收的也不是一个简单的数据,而是对数据进行了一个封装。同理flume也是一样,在flume中,有一个event,我们好像在拦截器的时候提到过,那么它是什么呢?event在flume当中叫做事件,flume在传输日志的时候,每一条数据都会被封装成一个event。
为什么要有event呢?
首先我们可以想一下,数据格式有很多种,source也不同,channel不同、sink也各不相同,那么我如何才能将其统一起来呢?这个时候就需要event了,将每一条记录都封装为大家都认识event不就行了吗?这就是为什么要有event。当然event主要包含两个部分,一个是header,一个body。body是一个字节数组,里面记录了日志信息,header则是一个hashmap,我们可以添加一些自己的信息,如果只有body没有header的话,那么我们的信息就会打到body里面,这样就对我们要传送的数据造成污染了,具有侵入性,所以要有header
(九)flume的agent
agent是flume的运行核心,是flume运行的最小单位。一个flume的agent就是包含了source、channel、sink的一个jvm进程,用于日志的收集和传输。
首先我们到目前为止介绍的都是概念,其实flume的概念也很好理解,主要就是各个组件的那些配置还没有介绍,后面会介绍,目前先了解flume的基础架构即可。因此之前也说过,用flume传输日志,就相当于在指定agent中各个组件的配置。一个agent可以包含多个source、多个channel、多个sink
A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes. A Flume agent is a (JVM) process that hosts the components through which events flow from an external source to the next destination (hop).
一个flume事件被定义为一个数据流单元,具有字节负载和可选的字符属性集。一个flume agent就是一个jvm进程,承载着各个组件(source、channel、sink),事件可以通过这些组件从外部源流向下一个目的地。
当然不要忘记,agent还是可以串联的,一个agent的sink对接下一个agent的source
(十)flume的安装
flume下载地址:http://archive.cloudera.com/cdh5/cdh/5
选择flume即可,为什么不到官网下载,因为cdh版本的话可以避免很多问题,比如jar包的冲突。
因此大数据组件安装的话,推荐去这个网站下载,不建议使用社区版本的。
我用的是阿里云的云服务器,所有大数据相关的软件都放在/opt目录下,因此我们在/opt下面新建一个flume目录,然后把相应的安装包放进去解压
解压完成之后,我们来看看flume的结构
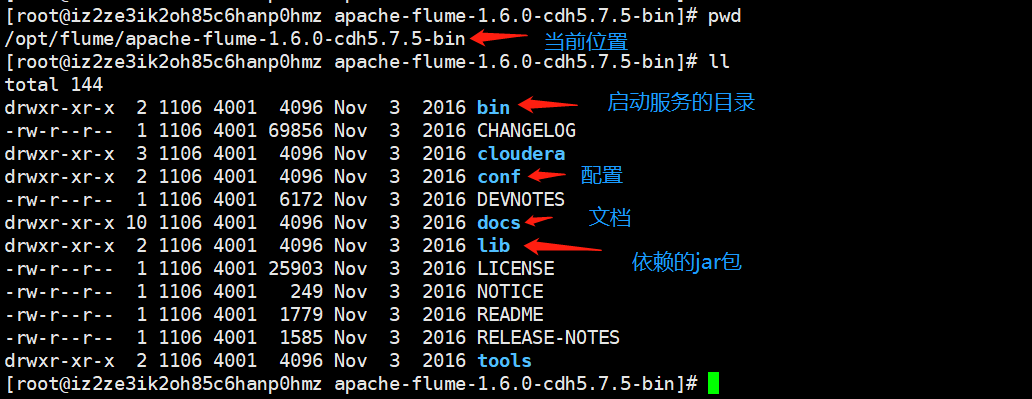
我们进入conf目录下,修改一下配置。如果我们只修改一个配置的话,那么需要修改什么呢?不用想,肯定是jdk的路径。对,我们需要在flume-env.sh中指定JAVA_HOME,但是进入目录发现没有这个文件,但是有一个flume-env.sh.template,这是模板,我们用这个模板生成一个即可
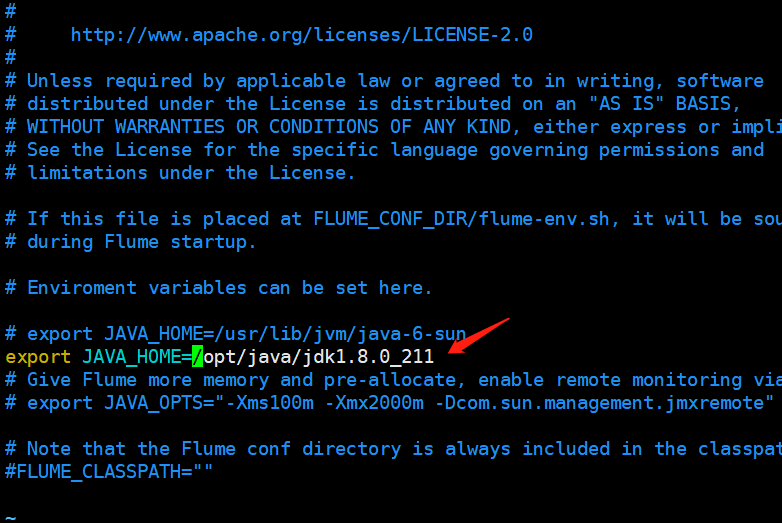
然后将flume加到环境变量里面去
export FLUME_HOME=/opt/flume/apache-flume-1.6.0-cdh5.7.5-bin
export PATH=$FLUME_HOME/bin:$PATH
然后source一下

输入flume-ng version查看版本,和其他框架不一样,flume的话需要加上-ng,至于原因后面会说。
(十一)flume的两种版本
flume分为两个版本,一个1.x之前的版本,叫做flume og,另一个是1.x版本,叫做flume ng
至于差别就不介绍了,总之现在用的话就是用flume 1.x版本的就行了。
(十二)flume的avro_source
任务:使用avro_source收集数据,打印到控制台
终于到实战部分了,我们下面就通过编写配置文件的方式来移动数据,之前也说了,使用flume就是编写配置文件。
至于channel,我们就无所谓了,使用内存channel还是磁盘channel都无所谓,我们这里主要是介绍source。而sink则就是控制台
那么配置怎么写呢?
# 这里的a1就是我们agent的名字
a1.sources = r1 # 命名agent的source为r1
a1.channels = c1 # 同理c1是channel的名字
a1.sinks = k1 # 同理k1是sink的名字
a1.sources.r1.type = avro # 配置r1的的类型avro
a1.sources.r1.bind = localhost # 绑定的端口为本地
a1.sources.r1.port = 4141 # 端口为4141
a1.channels.c1.type = memory # 指定c1的类型为内存
a1.channels.c1.capacity = 1000 # 指定c1的容量为1000个event
a1.channels.c1.transcactionCapacity = 1000 # 指定c1的每次处理容量为1000个event
a1.sinks.k1.type = logger # 表示不产生实体文件,就打印在控制台
# 将source和sink与channel绑定起来
a1.sources.r1.channels = c1 # source r1的channel指定为c1
a1.sinks.k1.channel = c1 # sink k1的channel指定为c1。但是这里不再是channels,而是channel,要注意
我们随便在一个目录,新建一个文件,将上面的内容去掉注释然后写进去
那么如何启动flume呢?
flume-ng agent -c $FLUME_HOME/conf -f 我们写的配置文件的路径 -n a1 -Dflume.root.logger=INFO,console
参数解释:
-c $FLUME_HOME/conf:首先flume启动是有默认配置的,这个配置就在$FLUME_HOME/conf下面
-f 我们写的配置文件的路径:这个很好理解,我们自己写的配置可以通过-f来指定
-n a1:我们在配置文件中指定的agent名字
-Dflume.root.logger=INFO,console:表示flume自身运行状态的日志,按需配置,详细信息控制台打印
我们启动服务,由于我们自己的conf就在当前目录下,所以直接flume-ng agent -c $FLUME_HOME/conf -f ./conf -n a1 -Dflume.root.logger=INFO,console启动即可
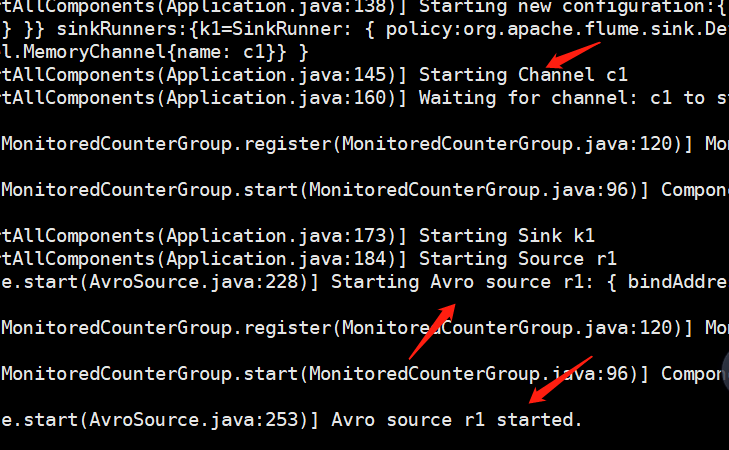
服务已经启动了,监听本地的4141端口,那么我们就往这个端口里面发送数据。
发送数据,我们可以发送一个文件,可以使用flume自带的一个方法。
flume-ng avro-client -c $FLUME_HOME/conf -H localhost -p 4141 -F ~/.bashrc
avro-client:创建一个客户端
-c $FLUME_HOME/conf:指定配置,刚才说了
-H localhost:指定目的ip
-p 4141:指定目的端口
-F ~/.bashrc:指定发送的文件
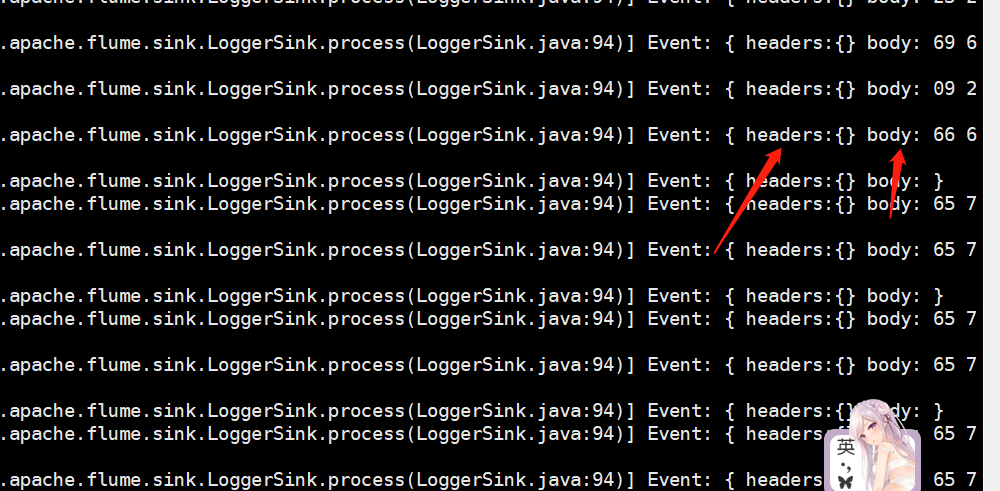
显示内容已经接受到了,会将文件打开,每一条都是一个event,包含header(我们这里没有指定)和event(是一个字节数组)
(十三)flume的exec_source
下面来看看flume的exec_source,flume之所以有这么多source、channel、sink,主要是为了解决不同场景的业务,那么这个exec_source是用来干什么的呢?
exec_source可以实时监控一个文本文件,如果文件有变化,可以打印出来
下面就来写配置文件,在当前目录新建一个conf1,写上如下内容(不含注释)
a1.sources = r1 # 命名agent的source为r1
a1.channels = c1 # 同理c1是channel的名字
a1.sinks = k1 # 同理k1是sink的名字
a1.sources.r1.type = exec # 配置r1的的类型exec
# a1.sources.r1.bind = localhost # 绑定的端口为本地
# a1.sources.r1.port = 4141 # 端口为4141
# 由于是监控一个文件,所以不需要在绑定ip和端口了
a1.sources.r1.command = tail -F /root/mashiro.txt # 指定命令,监控这个文件
a1.channels.c1.type = memory # 指定c1的类型为内存
a1.channels.c1.capacity = 1000 # 指定c1的容量为1000个event
a1.channels.c1.transcactionCapacity = 1000 # 指定c1的每次处理容量为1000个event
a1.sinks.k1.type = logger # 表示不产生实体文件,就打印在控制台
# 将source和sink与channel绑定起来
a1.sources.r1.channels = c1 # source r1的channel指定为c1
a1.sinks.k1.channel = c1 # sink k1的channel指定为c1。但是这里不再是channels,而是channel,要注意
启动flume,flume-ng agent -c $FLUME_HOME/conf -f ./conf1 -n a1 -Dflume.root.logger=INFO,console

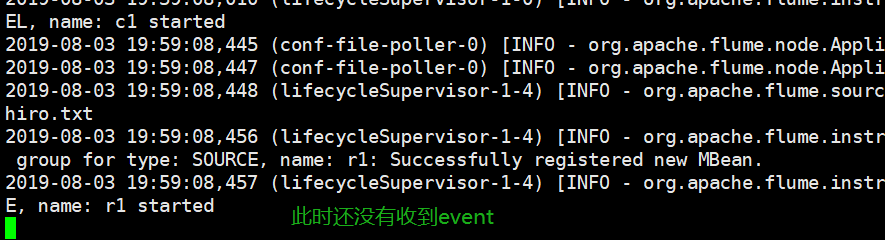
此时服务启动成功,但是还没有东西过来


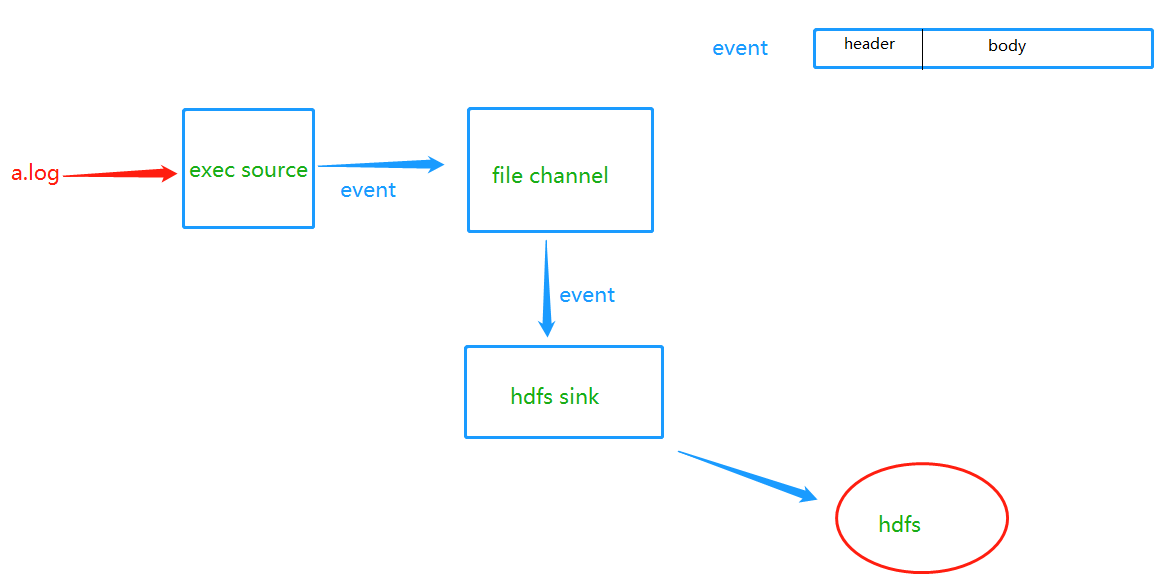
(十四)file channel
基于内存的channel,我们在介绍source的时候,演示过了,下面来看看基于文件的channel。
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/mashiro.txt
a1.channels.c1.type = file # 指定类型为file
a1.channels.c1.checkpointDir = /root/checkPoint # checkpoint将被存储的目录
a1.channels.c1.dataDirs = /root/data # 数据的存储位置
a1.sinks.k1.type = logger # 表示不产生实体文件,就打印在控制台
# 将source和sink与channel绑定起来
a1.sources.r1.channels = c1 # source r1的channel指定为c1
a1.sinks.k1.channel = c1 # sink k1的channel指定为c1。但是这里不再是channels,而是channel,要注意
先来看看/root目录的内容
然后执行命令,flume-ng agent -c $FLUME_HOME/conf -f ./conf2 -n a1 -Dflume.root.logger=INFO,console
再来查看当前目录
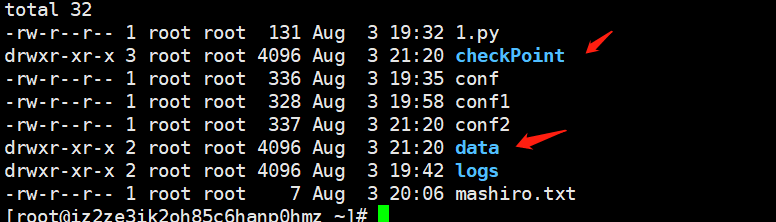
可以看到checkPoint和data两个目录,而且这是flume帮我们创建的,我们来往文件里面写点东西

(十五)hdfs sink
下面介绍sink,这里介绍一下hdfs sink,因为收集过来的日志主要放到hdfs平台上面。
既然要把收集的数据放大hdfs上面,那么flume就必须能连接hdfs,需要把依赖的jar包,放到$FLUME_HOME/lib下面,需要哪些jar包呢?又从哪里找呢?我们可以从$HADOOP_HOME/share/hadoop目录里面找。
commons-configuration-x.x.jar
hadoop-auth-x.x.x.jar
hadoop-common-x.x.x.jar
hadoop-hdfs-x.x.x.jar
# jar前面的x表示版本号,在找的时候可以使用模糊查询,比如我现在在$HADOOP_HOME/share/hadoop目录下,要找commons-configuration-x.x.jar 的话,便可以通过find ./ -name commons-configuration*即可。
如果你的flume版本是1.99的话,那么还需要以下两个jar包,否则的话就不需要
commons-io-x.x.jar
htrace-core-.x.x.x-incubating.jar
找到之后,cp到$FLUME_HOME/lib下面
下面就是编写配置文件
# 给source、channel、sink指定名字
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# source的配置
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/test.log
# channel的配置
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# sink的配置
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://localhost:9000
# 这条配置是给文件起一个前缀
a1.sinks.k1.hdfs.prefix = hive-
# 绑定channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1