我们使用pandas经常会用到其下面的一个类:Series,那么这个类都有哪些方法呢?另外Series和DataFrame都继承了NDFrame这个类,df.to_sql()这个方法其实就是NDFrame下面的方法。这三个类是我们要介绍的核心,下面先来介绍Series。
创建Series
import pandas as pd
s = pd.Series(['a', 'b', 'c', 'd'])
print(s)
"""
0 a
1 b
2 c
3 d
dtype: object
"""
Series其实就是给numpy的ndarray对象加上一层索引
print(s.index) # RangeIndex(start=0, stop=4, step=1)
print(s.values, type(s.values)) # ['a' 'b' 'c' 'd'] <class 'numpy.ndarray'>
"""
调用index方法拿到索引
调用values方法拿到具体值
"""
Series还可以让我们自己指定索引
s = pd.Series(['a', 'b', 'c', 'd'], index=['A', 'B', 'C', 'D'])
print(s)
"""
A a
B b
C c
D d
dtype: object
"""
# 通过索引进行取值
print(s['A']) # a
print(s[0]) # a
"""
我们惊奇的发现,即便将索引改变了,依旧可以使用默认的0 1 2 3··进行获取
但前提是索引不能是字母、数字混合,尽管不报错,但是容易乱套
"""
print(s["A": "C"])
"""
A a
B b
C c
dtype: object
"""
print(s[0: 2])
"""
A a
B b
dtype: object
"""
# 即便索引不是数字,也可以使用切片的方式
# 但是对于不是数字的索引来说,是包含结尾的。
# 可以传入指定的索引进行获取,多个索引的话需要放在列表里
print(s[['A', 'C']])
"""
A a
C c
dtype: object
"""
# 但是我们更推荐loc和iloc,当然对于Series来说无所谓。
# 但是对于DataFrame来说非常关键,因此建议Series也是用loc和iloc
# loc和iloc是根据索引来取值的,loc需要传入索引的具体值
# iloc则需要传入把索引看成值、排列起来,所对应的索引。
# 比如A B C D对应0 1 2 3,前者可以传入loc,但是不能传入iloc,iloc必须要求是数字
print(s.loc[['A', 'C']])
"""
A a
C c
dtype: object
"""
print(s.iloc[[0, 2]])
"""
A a
C c
dtype: object
"""
给Series指定名字
s = pd.Series(['a', 'b', 'c', 'd'], index=['A', 'B', 'C', 'D'], name="嘎嘎")
print(s)
"""
A a
B b
C c
D d
Name: 嘎嘎, dtype: object
"""
# 传入的时候,可以指定一个name。
# 调用Series对象下的name属性,可以打印出相应的name
print(s.name) # 嘎嘎
# 当然name也是支持修改的
s.name = "呱呱"
print(s.name) # 呱呱
查看并改变Series的类型
s = pd.Series([1, 2, 3, 4], dtype=float) # 创建的时候,也可以指定dtype,这是什么类型
print(s)
"""
0 1.0
1 2.0
2 3.0
3 4.0
dtype: float64
"""
# 这里面的类型都是numpy里面的类型
# 需要强调的是,python里面的str在pandas里面对应的是object
#调用dtype方法查看类型
print(s.dtype) # float64
# 如果想改变类型的话怎么办呢?比如改成int
# 注意不可以使用s.dtype = int这种形式,我们需要这么做
s = s.astype(int) # 这个方法是有返回值的
print(s)
"""
0 1
1 2
2 3
3 4
dtype: int32
"""
获取Series的值
# 之前说过可以调用values方法获取
s = pd.Series(['a', 'b', 'c'])
print(s.values) # ['a' 'b' 'c']
# 还可以调用s.get_values()
print(s.get_values()) # ['a' 'b' 'c']
# 两者没啥区别,建议使用values,简单一些
获取非零元素的索引
s = pd.Series([0, 1, 2, 0, 3])
print(s.nonzero()) # (array([1, 2, 4], dtype=int64),)
# 但是pandas提示我们这个方法要被移除了,建议我们这样使用
# Series是可以直接转化为numpy的数组的,转为numpy的数组之后调用nonzero()
print(s.to_numpy().nonzero()) # (array([1, 2, 4], dtype=int64),)
# 那么是不是也可以这样使用呢
print(s.values.nonzero()) # (array([1, 2, 4], dtype=int64),)
# 所以获取Series的值又多了一个方法,to_numpy
# 既然能够to_numpy,那么可不可以to_list呢?我们来试一下
print(s.to_list()) # [0, 1, 2, 0, 3]
# 显然是可以的,只是不能调用nonzero方法了。
# 获取到索引了,那么是不是可以取出来呢?
# 多个索引除了可以作为列表传进去,也可以作为ndarray传进去
print(s[s.values.nonzero()[0]])
"""
1 1
2 2
4 3
dtype: int64
"""
print(s.loc[s.values.nonzero()[0]])
"""
1 1
2 2
4 3
dtype: int64
"""
print(s.iloc[s.values.nonzero()[0]])
"""
1 1
2 2
4 3
dtype: int64
"""
# 咦,为什么loc和iloc都可以用。
# 因为当前的Series来说,索引就是0 1 2 3 4···
# 因此loc和iloc的参数是一样的。
对应元素替换
s = pd.Series(['a', 'b', 'c', 'd'])
# 调用put方法,表示将索引为0的元素替换为'A',索引为2的元素替换为'C'
# 注意这个是在本地修改的
s.put([0, 2], ['A', 'C'])
print(s)
"""
0 A
1 b
2 C
3 d
dtype: object
"""
# 但是不常用,我们完全可以使用之前的loc和iloc
# 这里我再改回来
s.loc[[0, 2]] = ['a', 'c']
print(s)
"""
0 a
1 b
2 c
3 d
dtype: object
"""
重复Series
s = pd.Series(['a', 'b'])
s = s.repeat(3)
print(s)
"""
0 a
0 a
0 a
1 b
1 b
1 b
dtype: object
"""
重置索引
s = pd.Series(['a', 'b', 'c'], index=['q', 'w', 'e'])
print(s)
"""
q a
w b
e c
dtype: object
"""
s1 = s.reset_index()
print(s1)
"""
index 0
0 q a
1 w b
2 e c
"""
# 将索引进行重置了
# 原来的索引这变为新的一列,叫做index
# 整体变成DataFrame,而原来的列则默认叫做0
s2 = s.reset_index(name="bigbang")
print(s2)
"""
index bigbang
0 q a
1 w b
2 e c
"""
# 当然可以指定name参数
# 此外原来的索引还是可以丢弃的
s3 = s.reset_index(name="bigbang", drop=True)
print(s3)
"""
0 a
1 b
2 c
dtype: object
"""
# 加上drop=True就丢掉了,当然此时还是Series对象
# 所以这里的name="bigbang"也没有作用了
设置索引
# Series只有一列,不像DataFrame那样,存在set_index
# 对于Series来说,直接设置index即可
s = pd.Series([1, 2, 3])
s.index = ["嘎嘎", "呱呱", "啪啪"]
print(s)
"""
嘎嘎 1
呱呱 2
啪啪 3
dtype: int64
"""
迭代模式
print(s)
"""
嘎嘎 1
呱呱 2
啪啪 3
dtype: int64
"""
print(s.items()) # <zip object at 0x000001E1A6C61148
print(list(s.items())) # [('嘎嘎', 1), ('呱呱', 2), ('啪啪', 3)]
# 当然有items自然有keys,values不用说了
print(s.keys()) # Index(['嘎嘎', '呱呱', '啪啪'], dtype='object')
转成字典
print(s.to_dict()) # {'嘎嘎': 1, '呱呱': 2, '啪啪': 3}
# 索引为键,value为值
转化为DataFrame
print(s.to_frame())
"""
0
嘎嘎 1
呱呱 2
啪啪 3
"""
# 原来的列的名字自动变为0
查看非空元素个数
s = pd.Series([0, False, np.nan, []])
print(s)
"""
0 0
1 False
2 NaN
3 []
dtype: object
"""
print(s.count()) # 3
# 如果是查看元素个数
print(s.size) # 4
print(len(s)) # 4
查看不重复元素以及不重复元素的个数
s = pd.Series([1, 1, 2, 1, 2, 3])
print(s.unique()) # [1 2 3]
print(s.nunique()) # 3
去重以及查看重复元素
s = pd.Series([1, 1, 2, 1, 2, 3])
s = s.drop_duplicates()
print(s)
"""
0 1
2 2
5 3
dtype: int64
"""
# 可以看到去掉重复的元素,默认是保存最上面的
# 如果保存下面的,可以加上一个参数
s = pd.Series([1, 1, 2, 1, 2, 3])
s = s.drop_duplicates(keep="last") # 默认是first
print(s)
"""
3 1
4 2
5 3
dtype: int64
"""
# 那么如何查看,重复的元素呢?
s = pd.Series([1, 1, 2, 1, 2, 3])
flag = s.duplicated(keep="first")
print(flag)
"""
0 False
1 True
2 False
3 True
4 True
5 False
dtype: bool
"""
print(s[flag])
"""
1 1
3 1
4 2
dtype: int64
"""
# 这样就把重复的元素取了出来
# 但是我们发现我们keep="first",但是取出的是后面的
# 这是因为我们目前取的是重复的,keep可以理解为保留,意思是留下来的。因此是相反的。
# 因此我们去重还可以这么写,直接在原来的flag基础上取反即可
print(s[~flag])
"""
0 1
2 2
5 3
dtype: int64
"""
# 怎么样是不是把first给留下了
round、quantile、corr、cov、diff
这些都是针对数值类型而言的
-
round:保留小数s = pd.Series([1.123, 2.211, 3.1232, 11.2132]) print(s.round(2)) """ 0 1.12 1 2.21 2 3.12 3 11.21 dtype: float64 """ -
quantile:求百分位数# quantile是一个0到1的数,比如quantile=0.5的话,说明求的是中位数。 # quantile=0.25,求的是四分位数(前),quantile=0.75,求的是四分位数(后) # quantile=0.8,求的是80%的位置对应的数是多少,这个就要涉及到比例了 s = pd.Series([1, 2, 3, 4, 5]) print(s.quantile([.25, .5, .75, .8])) """ 0.25 2.0 0.50 3.0 0.75 4.0 0.80 4.2 dtype: float64 """ # 索引就是我们指定的百分位,前3个很好理解。0.5就是中位数,对应的值为3。 # 但是0.8比如0.75要大,因此结果也比4大,至于具体大多少,pandas会自动帮我们计算 # 另外一提的是,会先对Series对象从小到大排序,然后计算。 # 这里即便是[5, 4, 3, 2, 1]也没事,因为会先排序 -
corr:求相关性s1 = pd.Series([1, 2, 3, 4]) s2 = pd.Series([1, 2, 3, 4]) print(s1.corr(s2)) # 1.0 # 两个Series是一样的,所以相关性是1.0,即100% s1 = pd.Series([1, 2, 4, 4]) s2 = pd.Series([1, 2, 3, 4]) print(s1.corr(s2)) # 0.9467292624062574 -
cov:求协方差s1 = pd.Series([1, 2, 4, 4]) s2 = pd.Series([1, 2, 3, 4]) print(s1.cov(s2)) # 1.8333333333333333 -
diff:做差s = pd.Series([1, 2, 3, 4, 5, 6, 7]) # 参数为n,n大于0,表示每一个元素与当前位置上面的第n个元素相减 # 参数为n,n小于0,表示每一个元素与当前位置下面的第n个元素相减 print(s.diff(1)) """ 0 NaN 1 1.0 2 1.0 3 1.0 4 1.0 5 1.0 6 1.0 dtype: float64 """ # 第一个元素上面没了,所示NaN print(s.diff(2)) """ 0 NaN 1 NaN 2 2.0 3 2.0 4 2.0 5 2.0 6 2.0 """ # 参数为2,所以索引为n的减去索引为n-2的, print(s.diff(-2)) """ 0 -2.0 1 -2.0 2 -2.0 3 -2.0 4 -2.0 5 NaN 6 NaN """ # 参数为-2,所以索引为n的减去索引为n+2的, # 而后两个元素对应的索引加上2之后,已经没有元素了,索引为NaN
append添加元素
s1 = pd.Series([1, 2, 3])
s2 = pd.Series([4, 5, 6])
s3 = pd.Series([4, 5, 6], index=[3,4,5])
print(s1.append(s2))
"""
0 1
1 2
2 3
0 4
1 5
2 6
dtype: int64
"""
print(s1.append(s3))
"""
0 1
1 2
2 3
3 4
4 5
5 6
dtype: int64
"""
# 忽略索引,从新排序
print(s1.append(s2, ignore_index=True))
"""
0 1
1 2
2 3
3 4
4 5
5 6
dtype: int64
"""
# append函数是有返回值的
combine
s1 = pd.Series([1, 22, 33])
s2 = pd.Series([11, 2, 3])
s3 = s1.combine(s2, func=lambda a, b: (a+b)/2)
print(s3)
"""
0 6.0
1 12.0
2 18.0
dtype: float64
"""
# func接收两个参数,分别是s1、s2对应的相同位置的元素,然后自定义返回值。
s1 = pd.Series([1, 22, 33])
s2 = pd.Series([11, 2, 3])
s3 = s1.combine(s2, func=lambda a, b: a if a > b else b)
print(s3)
"""
0 11
1 22
2 33
dtype: int64
"""
# 返回较大的一个
s1 = pd.Series([1, 22, 33])
s2 = pd.Series([11, 2, 3, 44])
s3 = s1.combine(s2, func=lambda a, b: a if a > b else b)
print(s3)
"""
0 11
1 22
2 33
3 44
dtype: int64
"""
# 长度不一致也不要紧
update
# 和combine类似,但是不用传入func,因为是跟NaN来判断的
# s1.update(s2),用s2对应元素替换掉s1,如果s2位空,则保留s1
# 所以有人可能注意到了,这个操作是在s1本身修改的,没有返回值
s1 = pd.Series([1, 2, np.nan, 4])
s2 = pd.Series([1, 2, 3, 4])
s1.update(s2)
print(s1)
"""
0 1.0
1 2.0
2 3.0
3 4.0
dtype: float64
"""
# 我们可以使用combine实现
s1 = pd.Series([1, 2, np.nan, 4])
s2 = pd.Series([1, 2, 3, 4])
s3 = s1.combine(s2, func=lambda a, b: a if pd.notna(a) else b)
print(s3)
"""
0 1.0
1 2.0
2 3.0
3 4.0
dtype: float64
"""
# 当然combine是有返回值的
# 当然可以再看两者区别
s1 = pd.Series([1, 2, np.nan, 4])
s2 = pd.Series([1, 2, 3, 4, 5, 6])
s3 = s1.combine(s2, func=lambda a, b: a if pd.notna(a) else b)
print(s3)
"""
0 1.0
1 2.0
2 3.0
3 4.0
4 5.0
5 6.0
dtype: float64
"""
s1 = pd.Series([1, 2, np.nan, 4])
s2 = pd.Series([1, 2, 3, 4, 5, 6])
s1.update(s2)
print(s1)
"""
0 1.0
1 2.0
2 3.0
3 4.0
dtype: float64
"""
# 查看到区别了吗?
# combine是两者比较,哪个满足取哪个,然后生成新的Series对象
# 而update表示更新,意思是使用s2的元素替换s1的元素,是在s1本身上操作的
# 结果的长度以s1为准,类似于sql中的left join
# 另外关于Series,不光这里的替换,还有比较,其实针对的都是相同索引对应的元素
s1 = pd.Series([1, 2, np.nan, 4])
s2 = pd.Series(["嘎嘎"], index=[2])
s1.update(s2)
print(s1)
"""
0 1
1 2
2 嘎嘎
3 4
dtype: object
"""
# 这里指定了index为2,那么会自动寻找s1中索引为2的元素
s1 = pd.Series([1, 2, np.nan, 4])
s2 = pd.Series([1, 2, 3, 4, 5, 6, 7], index=[0, 1, 3, 4, 5, 6, 7])
s1.update(s2)
print(s1)
"""
0 1.0
1 2.0
2 NaN
3 3.0
dtype: float64
"""
# 可以看到,原来的NaN并没被替换掉,因为s2中根本没有索引为2的对应项
# 这也再次说明,Series,其实不光Series,还有DataFrame,都是根据索引来的
sort_values 、sort_index排序
s1 = pd.Series(np.random.randint(1, 100, 6))
print(s1)
"""
0 89
1 55
2 85
3 56
4 71
5 36
dtype: int32
"""
print(s1.sort_values())
"""
5 36
1 55
3 56
4 71
2 85
0 89
dtype: int32
"""
# 降序排列
print(s1.sort_values(ascending=False))
"""
0 89
2 85
4 71
3 56
1 55
5 36
dtype: int32
"""
# 但是我们发现索引变了,这是有用的
# 可如果我们希望索引重置的话,怎么办呢?对,之前介绍过了
print(s1.sort_values(ascending=False).reset_index(drop=True))
"""
0 89
1 85
2 71
3 56
4 55
5 36
dtype: int32
"""
# 除此之外,还可以使用sort_index,直接对索引排序
# 当然索引具体值是与之前的索引有关系的
print(s1.sort_values(ascending=False).sort_index())
"""
0 89
1 55
2 85
3 56
4 71
5 36
dtype: int32
"""
s1 = pd.Series(np.random.randint(1, 100, 6), index=[3, 7, 5, 1, 6, 9])
print(s1.sort_values(ascending=False).sort_index())
# 这里索引依旧会从小到大排,想倒序的话,依旧加上ascending=False即可
"""
1 80
3 7
5 85
6 11
7 52
9 16
dtype: int32
"""
print(s1.sort_values(ascending=False).reset_index(drop=True))
"""
0 85
1 80
2 52
3 16
4 11
5 7
dtype: int32
"""
# reset_index的话,索引依旧是从0开始,步长为1
nlargest、nsmallest
# 选择前n个最大的元素和选择前n个最小的元素
# 生成100个1到100的元素
s1 = pd.Series(np.random.randint(1, 100, 100))
# 选择前10个最大的元素
print(s1.nlargest(10))
"""
73 99
33 97
78 95
57 94
42 93
47 93
81 92
49 91
98 91
10 90
dtype: int32
"""
print(s1.nsmallest(10))
"""
45 2
82 2
22 4
59 4
18 6
20 6
26 7
51 7
79 7
84 8
dtype: int32
"""
unstack
# 怎么解释呢?一句话,就是将具有二级索引的Series转换成DataFrame。
# 以及索引变成DataFrame的索引,二级索引变成DataFrame的列
# 举个例子吧
"""
现在有一个DataFrame,索引就不写了
姓名 科目 成绩
小红 语文 90
小红 数学 90
小红 英语 90
小胖 语文 91
小胖 数学 91
小胖 英语 91
小花 语文 92
小花 数学 92
小花 英语 92
我们的目标是变成这样子
姓名 语文 数学 英语
小红 90 90 90
小胖 91 91 91
小花 92 92 92
要怎么办呢?
"""
print(df)
"""
姓名 科目 分数
0 小红 语文 90
1 小红 数学 90
2 小红 英语 90
3 小胖 语文 91
4 小胖 数学 91
5 小胖 英语 91
6 小花 语文 92
7 小花 数学 92
8 小花 英语 92
"""
# 将姓名和科目设置索引,然后只取出"分数",得到对应的二级索引Series对象
df = df.set_index(["姓名", "科目"])
two_level_index = df["分数"]
print(two_level_index)
"""
姓名 科目
小红 语文 90
数学 90
英语 90
小胖 语文 91
数学 91
英语 91
小花 语文 92
数学 92
英语 92
Name: 分数, dtype: int64
"""
new_df = two_level_index.unstack()
print(new_df)
"""
科目 数学 英语 语文
姓名
小红 90 90 90
小胖 91 91 91
小花 92 92 92
"""
# 怎么样是不是改回来了呢?但是还有不完美的地方
# 那就是这个new_df的index和columns都有名字
# index的名字就是"姓名",columns的名字就是"科目"
# rename_axis表示给坐标轴重命名
# 这里只给columns变为空,至于index不为空的原因继续看
new_df = new_df.rename_axis(columns=None)
print(new_df)
"""
数学 英语 语文
姓名
小红 90 90 90
小胖 91 91 91
小花 92 92 92
"""
new_df = new_df.reset_index()
print(new_df)
"""
姓名 数学 英语 语文
0 小红 90 90 90
1 小胖 91 91 91
2 小花 92 92 92
"""
# 大功告成,如果index变为空的话,那么在reset_index之后,列名会变成index
# 但是如果原来索引有名字,reset_index,列名就是原来的索引名
DataFrame我会单开一篇文章介绍
map
# 映射,把Series的每一列都按照相同的规则进行变换
s = pd.Series([1, 2, 3])
# 传入一个函数,函数接收一个参数,就是Series对象的每一个值,然后进行操作、返回
print(s.map(lambda x: x+10))
"""
0 11
1 12
2 13
dtype: int64
"""
# 把每个元素都加上10
s = pd.Series([(1, 2), (2, 3), (3, 4)])
print(s.map(lambda x: x[1]))
"""
0 2
1 3
2 4
dtype: int64
"""
# 只取第一个元素
s = pd.Series(["mashiro", "satori", "nagisa"])
print(s.map(lambda x: f"my name is {x}"))
"""
0 my name is mashiro
1 my name is satori
2 my name is nagisa
dtype: object
"""
# map还有一个功能,可以传入一个字典
s = pd.Series(["北京", "上海", "南京"])
print(s.map({"北京": "beijing", "上海": "shanghai", "南京": "nanjing"}))
"""
0 beijing
1 shanghai
2 nanjing
dtype: object
"""
agg聚合
# 既然是聚合,那么针对的是数值类型
s = pd.Series([1, 2, 3, 4])
s.agg(["min", "max", "mean"])
"""
min 1.0
max 4.0
mean 2.5
dtype: float64
"""
apply
对于Series来说,apply和map是差不多的。但是apply只能接收函数。
s = pd.Series(["北京", "上海", "南京"])
def foo(x):
if x == "北京": return "beijing"
elif x == "上海": return "shanghai"
elif x == "南京": return "nanjing"
print(s.apply(foo))
"""
0 beijing
1 shanghai
2 nanjing
dtype: object
"""
# 此外apply还是可以接收函数的参数的
s = pd.Series([1, 2, 3, 4])
def foo(x, a, b):
return x + a + b
print(s.apply(foo, args=(1, 2)))
"""
0 4
1 5
2 6
3 7
dtype: int64
"""
rename
# rename是专门用来改变索引的
# 既可以替换索引值,也可以改变索引的名字
s = pd.Series([1, 2, 3, 4])
print(s)
"""
0 1
1 2
2 3
3 4
dtype: int64
"""
print(s.rename("gaga")) # 传入字符串,则改变索引名
"""
0 1
1 2
2 3
3 4
Name: gaga, dtype: int64
"""
print(s.rename(lambda x: str(x) + "哼哼")) # 传入一个函数,替换索引值
"""
0哼哼 1
1哼哼 2
2哼哼 3
3哼哼 4
dtype: int64
"""
# 其实完全可以用我们之前学的方法替代
s = pd.Series([1, 2, 3, 4])
print(s)
"""
0 1
1 2
2 3
3 4
dtype: int64
"""
s.name = "gaga"
print(s)
"""
0 1
1 2
2 3
3 4
Name: gaga, dtype: int64
"""
s.index = list(map(lambda x: str(x) + "哼哼", s.index))
print(s)
"""
0哼哼 1
1哼哼 2
2哼哼 3
3哼哼 4
dtype: int64
"""
当然rename还可以传入一个字典
s = pd.Series([1, 2, 3, 4])
print(s.rename({1: "一", 2: "二"}))
"""
0 1
一 2
二 3
3 4
dtype: int64
"""
reindex
选择指定的索引
s = pd.Series([1, 2, 3, 4])
print(s.reindex([0, 1, 2])) # 只选择0 1 2
"""
0 1
1 2
2 3
dtype: int64
"""
print(s.reindex([0, 1, 2, 3, 4])) # 指定不存在的索引为NaN
"""
0 1.0
1 2.0
2 3.0
3 4.0
4 NaN
dtype: float64
"""
# 有点像loc
s = pd.Series([1, 2, 3, 4])
print(s.loc[[0, 1, 2]])
"""
0 1
1 2
2 3
dtype: int64
"""
print(s.loc[[0, 1, 2, 3, 4]])
"""
0 1.0
1 2.0
2 3.0
3 4.0
4 NaN
dtype: float64
"""
# 可以看到是一样的
# 但是这里给了一个警告
# 原来的Series对象是没有索引为4的值的
# 使用loc这种方式,如果给了一个不存在的label,这里是4,那么在未来的版本会引发一个KeyError
# 建议我们使用reindex替代
drop
指定索引,删除某些元素
s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
print(s.drop(['a', 'c']))
"""
b 2
d 4
dtype: int64
"""
fillna
填充缺失值
s = pd.Series([1, np.nan, 2, np.nan])
print(s.fillna(value=123))
"""
0 1.0
1 123.0
2 2.0
3 123.0
dtype: float64
"""
# 还可以使用方法填充,ffill表示使用上一个值作为填充值
# 当然还有bfill,表示用后一个值填充
print(s.fillna(method="ffill"))
"""
0 1.0
1 1.0
2 2.0
3 2.0
dtype: float64
"""
print(s.fillna(method="bfill"))
"""
0 1.0
1 2.0
2 2.0
3 NaN
dtype: float64
"""
# 如果value和method同时指定,会报错,只能指定一个
replace
替换,通过指定一个字典,将Series对象里面的元素进行替换。和map里面指定字典是类似的
shift
这是一个比较重要的地方,从名字也能看出来表示平移。
s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9])
# 里面传入一个int,表示向上或向下平移多少个单位
# 关于方向的问题,如果参数大于0,向上平移,参数小于0,向下平移
# 这个和diff是一样的,其实不光是diff,还有其它的,我们后面介绍
# 大于0,都是向上,小于0,向下
# 比如diff,大于0,当前元素减去上面的元素,小于0,减去下面的元素。
# 对shift来说,大于0,表示向上平移。小于0向下平移
# 既然这样的话,两端必然会有NaN。
# 当然肯定会有人产生一个疑问,请看下面的图
print(s.shift(1))
"""
0 NaN
1 1.0
2 2.0
3 3.0
4 4.0
5 5.0
6 6.0
7 7.0
8 8.0
dtype: float64
"""
print(s.shift(-1))
"""
0 2.0
1 3.0
2 4.0
3 5.0
4 6.0
5 7.0
6 8.0
7 9.0
8 NaN
dtype: float64
"""
肯定会有人觉得,既然大于0是向上平移,那么shift(1)向上平移之后的第一个元素应该是平移之前的第二个元素啊,而且NaN应该是最后一个才对,同理shift(-1),NaN应该是第一个啊,是不是写错了,请看图。
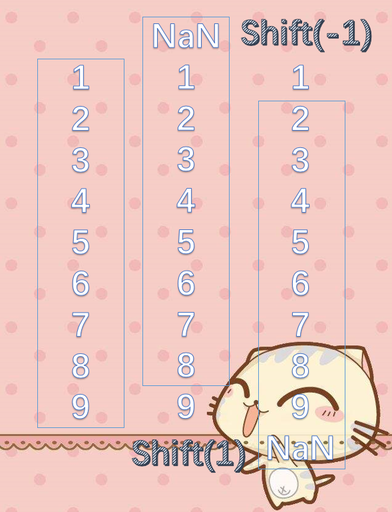
想象成一个框,shift(1)是框往上面平移一个单位,然后将框里面的数据替换为原来的数据。框不到的数据就使用NaN代替
我们可以使用shift实现diff
s = pd.Series([1, 3, 2, 5, 7])
print(s.diff(1).tolist()) # [nan, 2.0, -1.0, 3.0, 2.0]
print((s - s.shift(1)).tolist()) # [nan, 2.0, -1.0, 3.0, 2.0]
# 结果是一样的
memory_usage
查看当前的Series对象使用了多少内存
s1 = pd.Series(range(5))
print(s1.memory_usage()) # 120
s2 = pd.Series(range(10))
print(s2.memory_usage()) # 160
isin
查看Series中的元素是否在指定的列表里面,返回的是一个bool值
s = pd.Series(['a', 'b', 'c', 'd'])
print(s.isin(['a', 'c']))
"""
0 True
1 False
2 True
3 False
dtype: bool
"""
between
不用介绍了吧这个,值得一提的是,不仅是数字,还可以是字符串
s = pd.Series(['aa', 'b', 'c', 'd'])
print(s.between('a', 'c'))
"""
0 True
1 True
2 True
3 False
dtype: bool
"""
# 字符串的话,比较的是ascii码
# 默认是包含边界的,如果不想包含边界,指定inclusive=False即可
s = pd.Series([1, 2, 3, 4])
print(s.between(1, 4, inclusive=False))
"""
0 False
1 True
2 True
3 False
dtype: bool
"""
isna、isnull、notna、notnull
查看元素是否为空,是否不为空
# isna <==> isnull, notna <==> notnull
s = pd.Series([np.nan, 1, 2, np.datetime64("nat"), None])
print(s.isna())
"""
0 True
1 False
2 False
3 True
4 True
dtype: bool
"""
print(s.notna())
"""
0 False
1 True
2 True
3 False
4 False
dtype: bool
"""
# NaN(读取int、float时,空值就会变成NaN,np.nan是float类型)
# NaT(读取时间类型,空值会变成NaT)
# None
# 以上三者在pandas里面都是空
print(pd.isna(None), pd.isna(np.nan), pd.isna(np.datetime64("nat"))) # True True True
dropna
和drop类似,drop是通过指定索引。dropna则是自动删除空值
s = pd.Series([np.nan, 1, 2, np.datetime64("nat"), None])
print(s.dropna())
"""
1 1
2 2
dtype: object
"""
Series还有两个比较重要的方法
如果是object(字符串)类型的话,可以调用.str方法,这个我在当前版块已经介绍了如果是时间类型的话,可以使用.dt,得到和python中的datetime类型是类似的,python中datetime类型可以使用的方法,.dt基本上都可以使用,可以的话自己尝试一下。
到此结束啦!!!