掌握了前面所讲的正则表达式、网页解析以及 BeautifulSoup 抓取基本内容后,就可以编写网络爬虫代码获取数据了。
从 http://www.pm25x.com/ 网站抓取北京的 PM2.5 实时数据 。
抓取北京市 PM2.5 实时数据
现在我们的目的很明确,就是取回北京市 PM2.5 当时的实时数值。 因为这个结果会实时改变,所以你们实际取得的数值会和此时我在案例中抓取到的数据有所不同,但抓取数据的过程是完全相同的 。
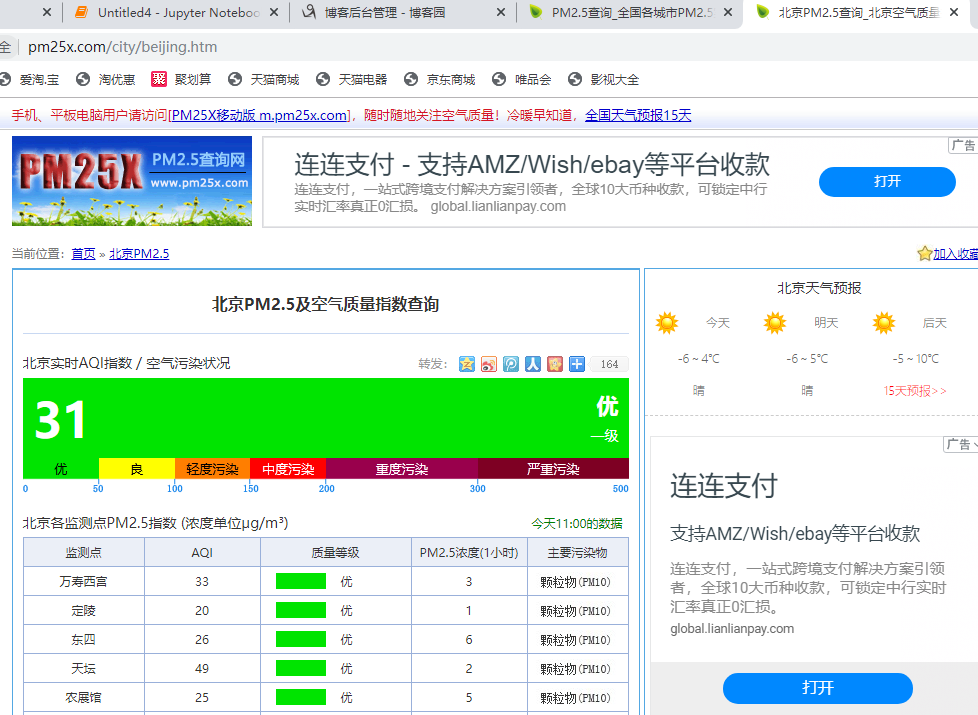
很 多 情况下,我们想要 的数据井不在 网 站一级页 面之 中,从而不 能直接抓取, 要采 用分 步 的方式抓取。 打开 htψ : //www.pm25x.com/ 网 站首页 的 源 代 码 , 通过 Ctrl+F 组合键搜索关键词“北京 ”, 发现这个关键宇位于 title 值为 ”北 京 PM2 . 5 ”的 <a> 标签 中 。
通过下面语句就能很容易地把这个标签的内容抓下来:


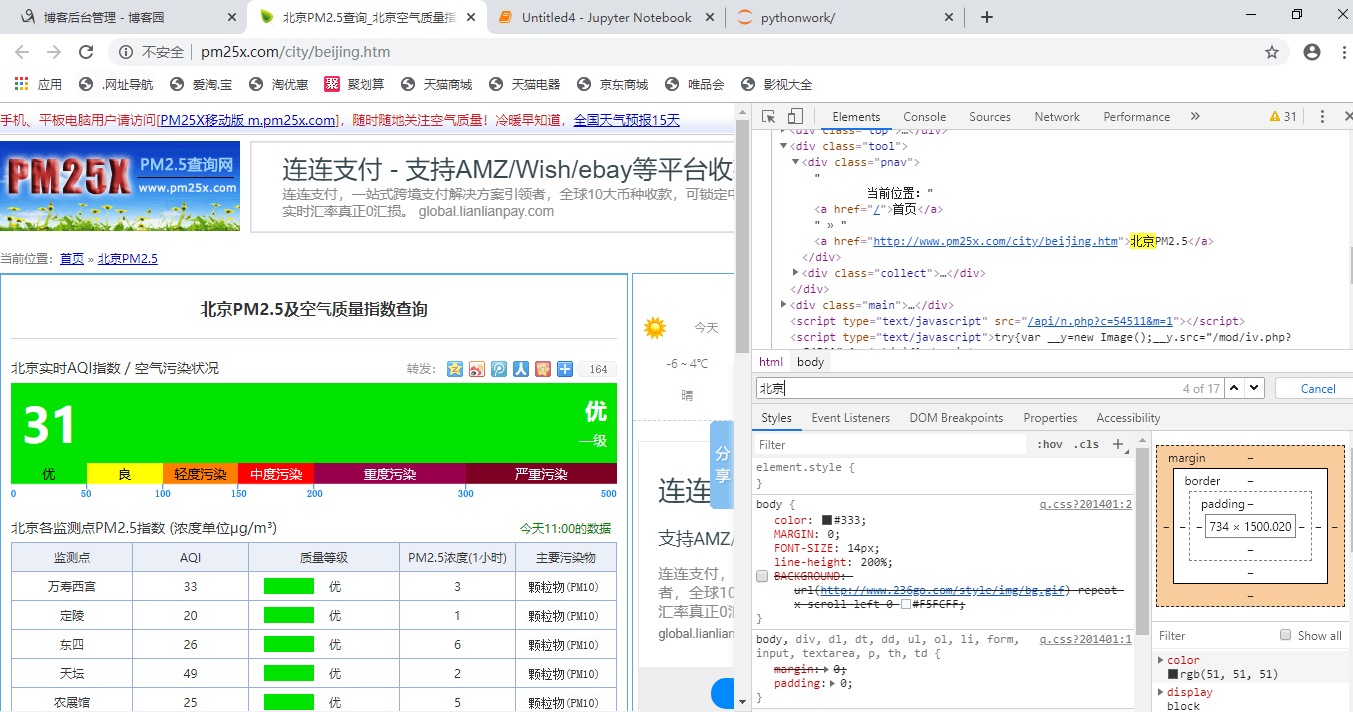
我们从该网页的页面看到,北京市现在的 PM2.5 值为 31 , 然后 打开 二 级 页 面的源代码,搜索“ 31 ”(你做练习时不要也查 31 ,要看看该 网站实时的 PM2 . 5 是多少你就搜多少〉。很容易发现,这个值位于 class 名为“ aqivalue ”的 <div> 标 签中(如下图),这下就好办了 。 我们通过下面两个语句,把问题搞定 : datal=sp2 . select (” .aqivalue”) #通过类 名 aqivalue 抓取包含北京市 pm2.S 数值的标签 pm25=datal[OJ .text #获取标签中的 pm2.5 数据


抓取北京PM2.5的实时的数据
import requests from bs4 import BeautifulSoup url1 = 'http://www.pm25x.com/' #获得主页面链接 html = requests.get(url1) #抓取主页面数据 sp1 = BeautifulSoup(html.text, 'html.parser') #把抓取的数据进行解析
city = sp1.find("a",{"title":"北京PM2.5"}) #从解析结果中找出title属性值为"北京PM2.5"的标签 print(city)

citylink=city.get("href") #从找到的标签中取href属性值 print(citylink)

url2=url1+citylink #生成二级页面完整的链接地址 print(url2)

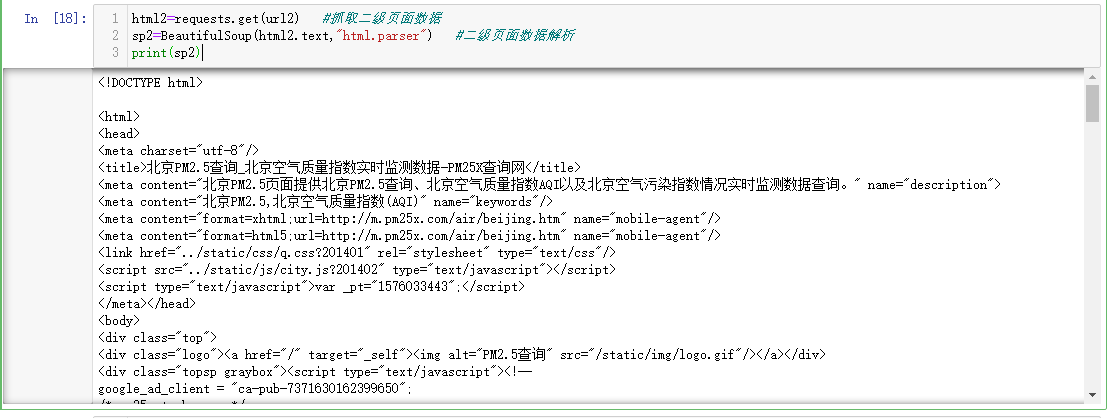
html2=requests.get(url2) #抓取二级页面数据 sp2=BeautifulSoup(html2.text,"html.parser") #二级页面数据解析 print(sp2)
data1=sp2.select(".aqivalue") #通过类名aqivalue抓取包含北京市pm2.5数值的标签 pm25=data1[0].text #获取标签中的pm2.5数据 print("北京市此时的PM2.5值为:"+pm25) #显示pm2.5值
