hadoop hive 高级查询
Hive聚合运算 - Group by
(基本内置聚合函数)nmax, min, count, sum, avg
1)Hive基本内置聚合函数与group by 一起使用
2)支持按位置编号分组
set hive.groupby.orderby.position.alias=true;
select name,sum(score) from table_name group by name;——>使用表达式
Hive聚合运算-hiving
1)对group by聚合结果的条件过滤
2)可以避免在Group by 之后使用子查询(where )
select name from table_name group by name having count(*)<1——>having使用
select name from table_name group by name where count(*)<1——>where使用
产生的问题:having 和 where有什么不同?
having是先分组在进行筛选
where是可以先帅选在进行分组
Hive聚合运算-基础聚合
1)与group by 一起使用,应用于列或者表达式
| max | 寻找最大的一个数 |
|---|---|
| min | 寻找最小的一个数 |
| count | 整个列的个数 |
| sum | 统计总数 |
| avg | 计算某个列的平均数 |
| collect_set | 将某个列数据形成数组(可以去重) |
| collect_list | 将某个列数据形成数组(不可以去重) |
Hive聚合运算-高级聚合
1)grouping sets:
SELECT a, b, SUM( c ) FROM tab1
GROUP BY a, b
GROUPING SETS ( (a, b), a, b, ( ) )(相当于将a,b出现的所有情况都显示出来)
2)GROUP BY WITH CUBE|ROLLUP
CUBE:对分组列进行所有可能组合的聚合
ROLLUP:计算维度层次级别上的聚合
SELECT a, b, SUM( c ) FROM tab1
GROUP BY a, b, c WITH CUBE
//相当于将(a,b,c),(null,b,c)(a,null,c),(null,bull,c)出现的所有情况都显示出来
SELECT
a, b, SUM( c )
FROM tab1
GROUP BY a, b, c WITH ROLLUP
//相当于将(a,b,c),(a,null,c),(null,null,c)
出现的所有情况都显示出来
窗口函数-概述
语法:
Function (arg1,..., arg n) OVER (PARTITION BY <...> [<window_clause>])
over关键字 指出我们作用在什么范围
通过更细节的的window clause把窗口函数更细节的映射
窗口函数-排序
row_number() over
实例一:
1)row_number()
将一个分好组里面的一个分区的所有数据进行排序;
select userid,username,dept,score,
row_number() over(partition by username order by score)
from ccc;
2)rank()
对于相同的分区里面的数据显示一样的排名
select userid,username,dept,score,
rank() over(partition by username order by score)
from ccc;
3)dense_rank()
相当于在分区里面有排名一样的,接下来的排序接着排
select userid,username,dept,score,
dense_rank() over(partition by username order by score)
from ccc;
4)percent_rank()
select userid,username,dept,score,
percent_rank() over(partition by username order by score)
from ccc;(得出的数值比列)
计算方式:当前(行号-1)除以(总行数-1)
窗口函数-聚合
| sum: | 分组以后在按照总成绩进行排序 |
|---|---|
| min() | 分组以后在按照最小成绩进行排序 |
| avg() | 分组以后在按照平均成绩进行排序 |
| count | 分组以后在按照个数成绩进行排序 |
实例:
select userid,username,dept,score,
sum(score) over(partition by dept order by score)
from userinfos group by dept;
窗口函数-分析
| lead(score,1) | 根据给出数,生成从后面开始数第几个数的值 |
|---|---|
| lag(score,1) | 根据给出数,生成从前开始数第几个数的值 |
| first_value(salary) | 根据给出的列值,都将生成第一个数值 |
| last_value(salary) | 根据给出的列值,都将生成最后一个数值 |
实例:
select username,dept,score,
first_value(score) over(partition by username order by score)
from ccc;
窗口函数-窗口定义-2
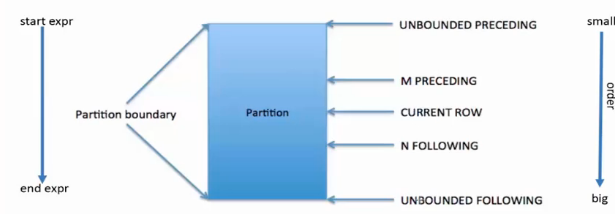
| 2 preceding | 前两行 |
|---|---|
| current row | 当前行 |
| 2 following | 最后两行 |
| unbounded | 无限 |
作用:用于进一步细分结果并应用分析函数
支持两类窗口定义
1)行类型窗口
2)范围类型窗口
当前指针的所在行,
select username,dept,score,
max(score)over(partition by dept order by username rows
between 1 preceding and current row)//设定当前行和当前前一行的数据做对比,取最大的
from userinfos;
取得是分区里面的最大的数
范围类型窗口实例:
select username,dept,score,
max(score)over(partition by dept order by username rows
between 1000 preceding and current row)//设定当前行和当前前一行的数据做对比,取最大的
from userinfos;
取得是分区里面的最大的数
Hive UDf
当数据为map list 继承UDF /数据为string 继承GennericUDF
实例一:
首先我们打开idea
导入如下架包
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.5</version>
</dependency>
新建一个类并继承UDF
编写一个方法打包并储存到hdfs
执行下面语句,即可使用自定义函数
create function hello as 'com.njbd.tools.SayHello' using jar 'hdfs:///myfun/fcu.jar';