最近被KPI考核的事弄得焦头烂额,因为上级领导经常拍脑门决定考核的目标,也不管他人是否有能力实现。目标定得太高,难以实现;太低,又太容易实现,没什么挑战。到底什么样的目标数值是比较靠谱的?想学点数字预测的知识和技能,那如何做数字预测?
数字预测指的是利用相关数据分析和挖掘模型预测出可能的数值,辅助决策,而不是拍脑门决策。产品运营过程中,经常会用到数据的精细化运营,而数字预测将会是精细化运营中非常重要的一项工作。
1.移动均值预测
移动均值预测是最简单的一种数字预测方法,使用移动均值可预测商品销售数据,商品1和2的数据如表7-2所示。
对商品1,采用简单移动平均公式预测5月6日的销售量=(180+165+200+195+240)/5=196;对商品2,权重按照0.1、0.1、0.2、0.3、0.3进行设定,离目标日期越近,权重比一般值越大,采用加权移动平均公式预测5月6日的销售量=168×0.1+128×0.1+140×0.2+180×0.3+184×0.3≈167。一般而言,使用加权移动平均公式预测出的数值比简单移动平均公式预测出的值要靠谱一些。
2.决策树挖掘模型
我们以某SNS网站为例,该网站推出了一个有多个付费道具的应用,经过一段时间的运营,积累了较为丰富的运营数据,现在想利用这些付费数据挖掘出来的结果帮助提高应用的整体收入。
我们进行数据挖掘的目的是提高推广位的利用效率以提高销售收入,找到哪些用户更容易喜欢某一种应用,以提高推广投放的精准性。选用模型决策树,评估方式为提高投放,然后查看广告的转换率。
SNS站点的好处在于我们可以获得很多用户属性,很容易对用户的购买行为和属性进行联合挖掘,以获得某个道具会吸引哪些用户这个问题的答案。这里我们选择决策树,而选取的挖掘数据为用户的属性和从用户交易数据中提取的消费道具信息。
这里要简单说一下选择决策树作为挖掘模型的原因,因为我们要做的事情可以表述为:将用户分成可能消费的用户群和不太可能消费的用户群,实际上是为一个用户集合进行分类,而决策树可以让分类更具有层次性,相比于无层次性的简单判别而言,更加精确,同时还有可以兼容连续变量和离散变量的特性。 关于决策树分层涉及的裂变函数,可参考相关的算法书籍。数据准备过程选取的样本如表7-3所示。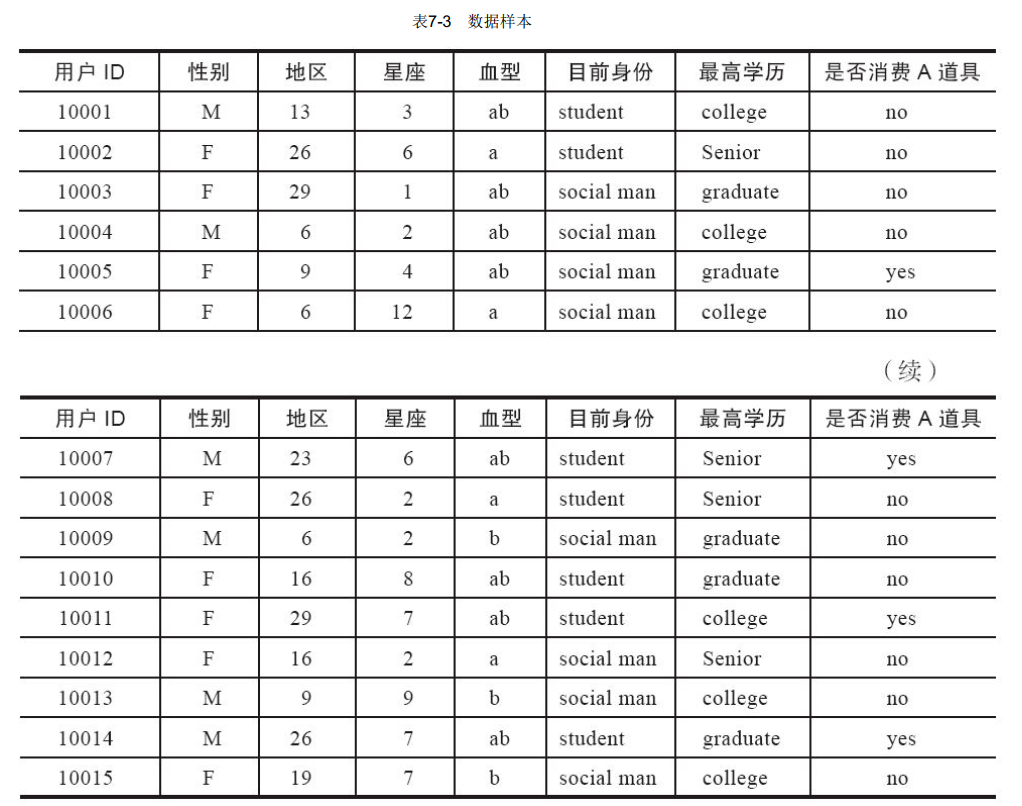
将数据分成训练集和测试集,可按照比例随机抽取,实例的决策过程是将上面样例所述的数据按70%和30%的比例随机抽取为训练集和测试集,其中,训练集用来生产初步决策,测试集用来验证测试决策。
利用Excel 2007的决策树模型创建决策树:使用性别、地区、星座、血型、目前身份、最高学历作为输入,预测用户是否购买道具,得到的结果如图7-9所示。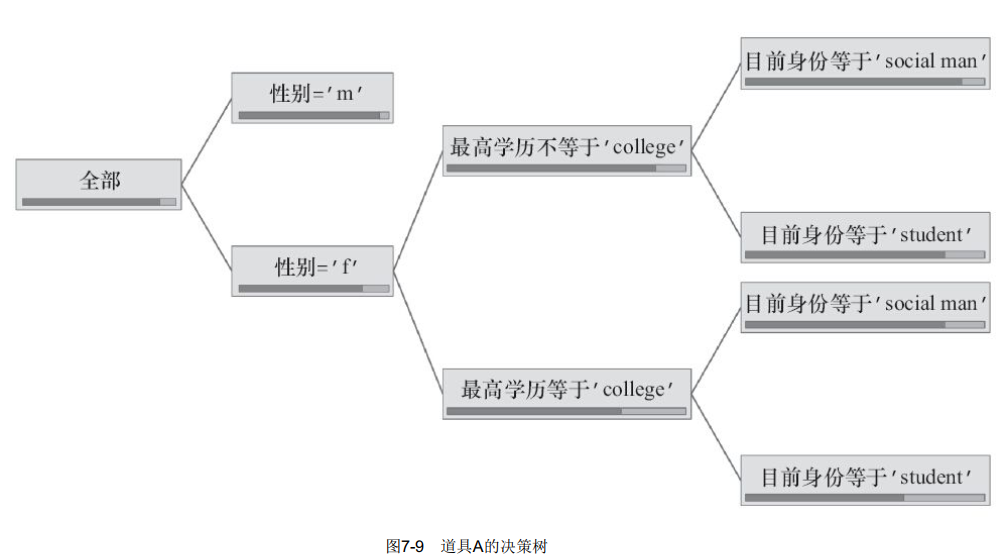
在道具A的决策树中我们可以发现,在读的女性大学生对于道具A的购买意愿更为强烈。对我们生产的决策树模型在测试集中进行准确性检验,测试结果如表7-4所示。表7-4 道具A的正确性检验数据结果(部分数据)
根据道具A的正确性检验数据结果,图形化数据结果,如图7-10所示。道具A的正确性检验结果图中,从左至右,折线分别代表理想模型、定型数据-树和随机推测。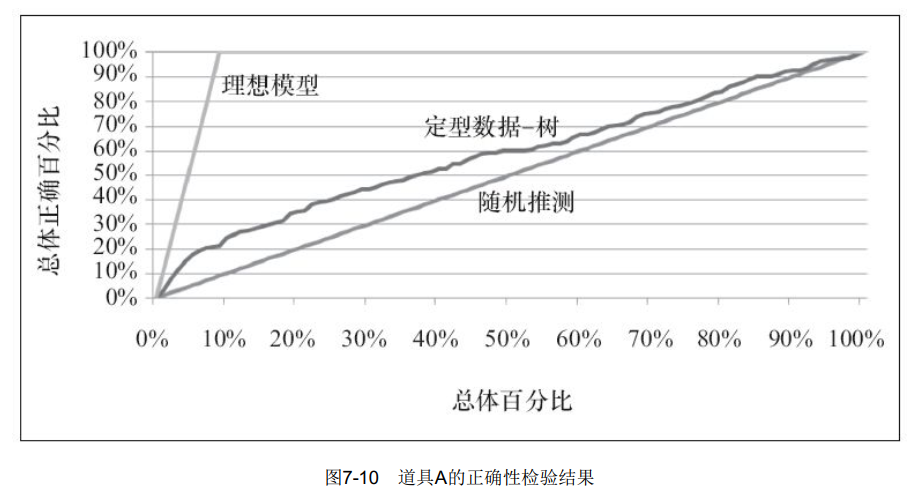
对道具A的正确性检验结果为:“定型数据-树”模型提升117.22%。
当有多个裂变函数进行评测时,定型数据线与理想模型越吻合,预测的准确性就越高。当然,现在的裂变参数和函数还有较大的优化空间,但是与之前的随机推测相比已经有了较大提升。使用同样的方式可以获得道具B的决策树, 如图7-11所示。
与道具A的决策树进行对比,我们发现道具A和道具B所面向的用户群完全不同,因此,对两者的推广行程进行差异化策略比较,通过配置不同的投放方案及女大学生在校学生会的某一推广位,看到道具A的推广,而男性的社会人士在同样的地方看到的是道具B。通过对道具A和道具B的推广位的打开情况和购买情况进行监控,发现策略实施后的效果发生变化明显,如表7-5所示。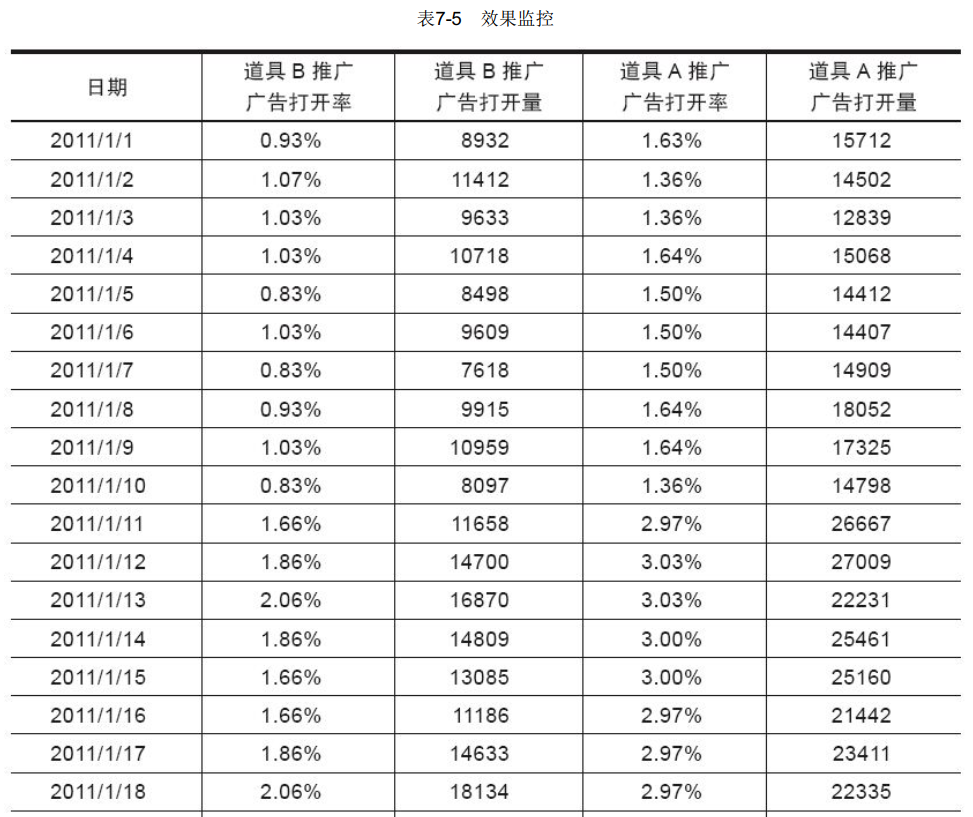
根据效果监控数据,图形化数据结果,打开率变化趋势如图7-12所示。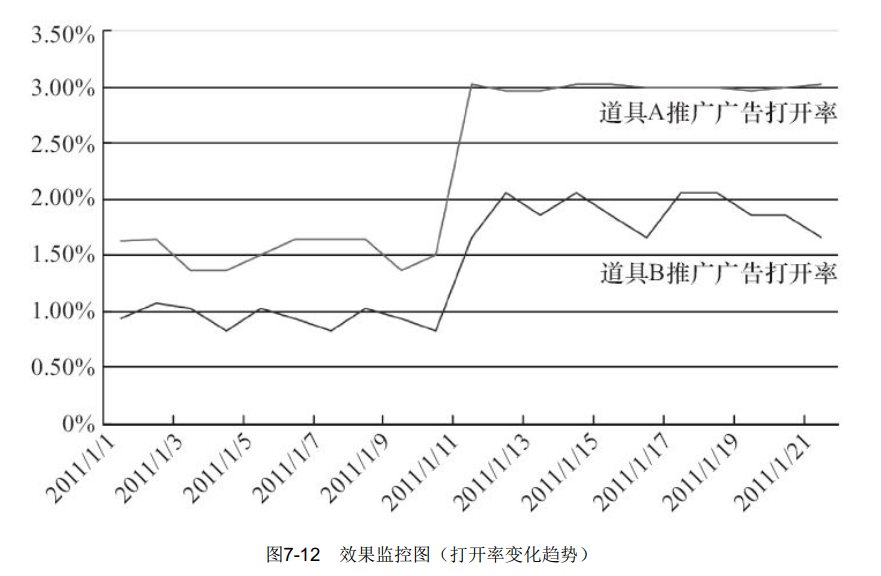
根据效果监控数据,图形化数据结果,打开量变化趋势如图7-13所示。
从效果监控中可以发现,打开量的提升和打开率的提升并不成比例,原因是差异化的投放方案导致广告投放量的降低,而策略实施的道具A和道具B的收入变化也应该得到重点监控。
一贯比较鄙视拍脑门进行目标决策的领导,这样做的领导有可能是他自己本身都不太懂一些数据预测的基本方法。心想,有朝一日,自己当领导的时候,不仅要明确告诉下属做什么,还要明确告诉下属为什么要这么做。要知道,做到这点非常不容易,平时需要更多的沉淀和积累。
纵观还有很多数据模型和算法让你想远离“随机”,更加靠近“理想”,这样的测试往往会出现惊喜,如测试不同的聚类方式和决策分层裂变算法。我们通过数据挖掘生成策略的过程,也完全可以动态化、机器化,通过自动化的数据挖掘到决策的计算过程,我们可以得到更加精确和灵敏的策略。
转载于:https://www.cnblogs.com/SanMaoSpace/p/9384460.html