什么是词云
词云又叫文字云,主要是对文本数据中出现频率较高的“关键词”通过不同颜色、大小的渲染,在视觉上突出表现。形成关键词渲染,从而使用户通过关键词就能了解到文本的主题。因为他形成的图片类似云层,所以称为词云。
先看看效果图:
他还可以是这样的效果:

也可以是这样的效果:
看过效果图后是不是觉得很棒,接下来做属于自己的词云图
先制作一个简单的
1、python 中导入词云库,wordcloud,导入很简单不做多的解释
pip install wordcloud
导入图像库
pip install matplotlib
2、生成词云需要文字。准备词云文字,以英文先做一个小尝试以【美国】罗伯特·弗罗斯特 写的《未选择的路》为例:
heRoad Not Taken -Robert Frost Two roads diverged in a yellow wood, And sorry I could not travel both And be one traveler, long I stood And looked down one as far as I could To where it bent in the undergrowth; Then took the other, as just as fair, And having perhaps the better claim, Because it was grassy and wanted wear; Thoug has for that the passing there Had worn them really about the same, And both that morning equally lay In leaves no step had trodden black. Oh,I kept the first for another day! Yet knowing how way leads on to way, I doubted if I should ever come back. I shall be telling this with a sigh Somewhere ages and ages hence: Two roads diverged in a wood,and I— I took the one less traveled by, And that has made all the difference.
保存以上文件为: word.txt
3、代码如下:
#!/usr/bin/env python from wordcloud import WordCloud import matplotlib.pyplot as plt # 读取词云文件 text = open(r'/Users/ydj/Desktop/word.txt').read() # 生成一张词云图片 wordcloud = WordCloud().generate(text) # 将词云图显示出来 plt.imshow(wordcloud) plt.axis("off") plt.show()
4、运行后效果图:
对 wordcloud 做点加工
通过改变 wordcloud 中属性来达到需要
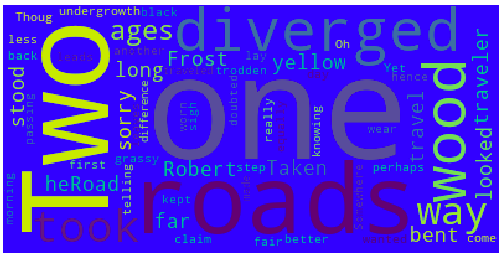
如下代码,添加画布宽度为400像素,背景颜色为蓝色
代码如下:
#!/usr/bin/env python from wordcloud import WordCloud import matplotlib.pyplot as plt # 读取词云文件 text = open(r'/Users/ydj/Desktop/word.txt').read() # WordCloud 中添加属性,如下生成图片宽为400像素,背景颜色为蓝色 wordcloud = WordCloud(width=400,background_color='blue').generate(text) plt.figure() plt.imshow(wordcloud) plt.axis("off") plt.show()
运行后效果如下:
如果要设置更多属性,查看文末的 WordCloud 中常用参数
汉子的制作
因为 wordcloud 无法直接生成中文词云,所以在汉子制作过程中需要使用 jieba 分词将其生成字符串,然后将其输出
jieba 是一种调用了自己的分词算法,将切分好的文本按逗号分隔符分开如:
text="黄色的树林里分出两条路" result=jieba.cut(text) print("切分结果: "+",".join(result))
执行后切出的结果为:切分结果: 黄色,的,树林,里,分出,两条路
首先需要导入 jieba 库:pip install jieba
还是以【美国】罗伯特·弗罗斯特 《未选择的路》 中文为例:
黄色的树林里分出两条路,
可惜我不能同时去涉足,
我在那路口久久伫立,
我向着一条路极目望去,
直到它消失在丛林深处.
但我却选了另外一条路,
它荒草萋萋,十分幽寂,
显得更诱人、更美丽,
虽然在这两条小路上,
都很少留下旅人的足迹,
虽然那天清晨落叶满地,
两条路都未经脚印污染.
呵,留下一条路等改日再见!
但我知道路径延绵无尽头,
恐怕我难以再回返.
也许多少年后在某个地方,
我将轻声叹息把往事回顾,
一片树林里分出两条路,
而我选了人迹更少的一条,
从此决定了我一生的道路.
代码如下:
from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba # 读取词云文件 text = open(r'/Users/ydj/Desktop/word.txt', encoding='utf-8').read() # 使用 jieba 进行分词 text_jieba = "".join(jieba.cut(text)) # 显示 wordcloud = WordCloud( font_path='/Library/Fonts/PingFang.ttc'
).generate(text_jieba) plt.imshow(wordcloud) plt.axis("off") plt.show()
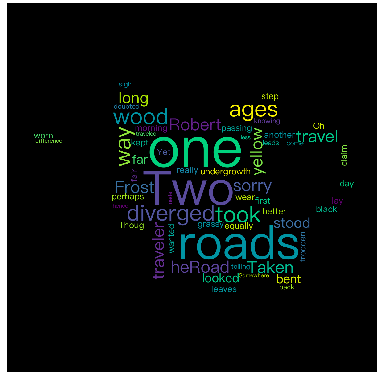
运行后的结果:

设置字体时,字体路径一定要正确,字体也必须存在,如果路径不正确或字体不存在,编译时会报错,编译失败
字体也要设置为中文可以使用的,如果不正确生成的画布中文字就会显示错误
如:将字体设置为 font_path='/Library/Fonts/SFNSTextItalic.ttf' 效果如下:
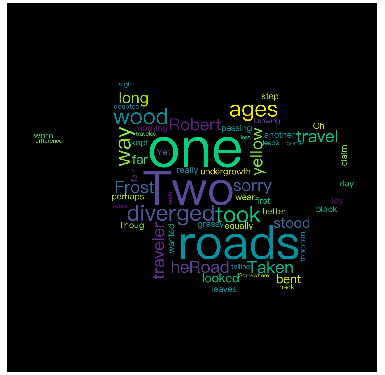
制作图形背景词云图
在绘制云词图的时候,只需要将 WordCloud 中 mask 参数设置为指定图片,则在生成词云图时会根据 mask 指定的图像生成。
但 mask 在使用时会将白色部位剔除
在使用加载图片时需要用的 numpy和PIL库:
pip install numpy
pip install PIL使用 mask 图如下:
代码如下:

from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba import numpy as np from PIL import Image # 读取词云文件 text = open(r'/Users/ydj/Desktop/word.txt',encoding='utf-8').read() mask = np.array(Image.open("/Users/ydj/Desktop/background.jpeg")) # 使用 jieba 进行分词 text_jieba = "".join(jieba.cut(text)) # 显示 wordcloud = WordCloud( font_path='/Library/Fonts/PingFang.ttc', mask = mask ).generate(text_jieba) plt.imshow(wordcloud) plt.axis("off") plt.show()
执行后结果:
WordCloud 中常用参数font_path : string #字体路径
width : int (default=400) # 画布宽度,默认400像素
height : int (default=200) # 画布高度,默认200像素
prefer_horizontal : float (default=0.90) # 词语水平方向排版出现的频率,默认 0.9
mask : nd-array or None (default=None) # 默认为空,使用二维遮罩绘制词云。如果非空,遮罩形状将使用 mask
min_font_size : int (default=4) # 显示的最小字体
max_font_size : int or None (default=None) # 显示的最大字体
max_words : number (default=200) # 显示词的最大个数
background_color : color value (default=”black”) # 背景色
colormap : string or matplotlib colormap, default=”viridis” # 给每个单词随机分配颜色
fit_words(frequencies) # 根据词频生成词云
generate(text) # 根据文本生成词云
原文发布在 软件羊皮卷 微信公众号中,欢迎大家关注
