前言
下面的分析基于对spark2.1.0版本的分析,对于1.x的版本可以有区别。
内存配置
|
key |
默认 |
解释 |
|
spark.memory.fraction |
0.6 |
spark可以直接使用的内存大小系数 |
|
spark.memory.storageFraction |
0.5 |
spark存储可以直接使用的内存大小系数 |
|
spark.memory.offHeap.enabled |
false |
是否开启spark使用jvm内存之外的内存 |
|
spark.memory.offHeap.size |
0 |
jvm之外,spark可以用多少内存 |
内存划分策略
如图1,spark在内存上划分出4部分空间,分别为预留空间(默认300M),Spark执行空间(Execution),Spark存储空间(Storage)和用户使用空间。
下面用一个实际案例描述一下这4部分空间:
假设给executor分配1G,也就是1024MB,Spark会留出300MB,这300MB不能作为缓存或者rdd相关操作使用,可以理解成防止OOM的一种策略。当`spark.memory.fraction`为0.6时(默认),(1024 - 300) * 0.6 = 434MB,这434MB就是Spark用于rdd缓存或者rdd执行的内存大小,也就是Spark可以随意使用的max memory。剩下的资源是给用户留下的内存大小。而`spark.memory.storageFraction`则是声明了可以用于存储的大小,默认是0.5,也就是说Spark任务中,存储Storage和执行Execution各占50%内存空间也就是434*0.5=217MB。
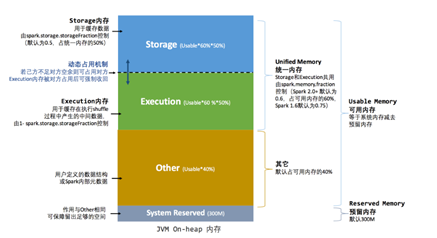
图1
在实际内存申请过程中,Spark为Storage和Execution各自维护了一个内存资源池,用于控制和协调内存资源的使用,在钨丝计划的路线下,Spark支持onHeap和offHeap两种内存分配机制,但是分配流程是一致的。参考图2,在Execution的内存池资源充足的情况下,直接获取需要的Execution资源,而在不足情况下,允许Execution借用Storage的内存资源,首先判断Storage资源池剩余的资源是否满足要去,如果剩余也不足,那么尝试将已经存在的block(block是rdd缓存或者shuflle的存储单元)剔除,直到获取到充足的内存,如果资源依然不够Execution,那么该Execution会阻塞,知道获取到全部资源。 而反过来需要获取Storage的内存资源,也是先检查Execution内存池是否有剩余,如果依旧不足,呢就去尝试将已经存在的block剔除,直到获取到充足的内存(和Execution调用的是一个函数evictBlocksToFreeSpace),最后获取不到足够的资源就直接返回失败。这相比Execution是有区别的,Storage不够可以spill,而Execution资源不够就必须阻塞等待。

图2
内存划分粒度
Spark对于内存的控制的最小粒度是Task,一个executor也就是一个JVM维护一个Execution内存池和Storage内存池,也就是说一个executor能同时执行多少个task除了收到cpu的影响,还受到竞争内存资源的影响,其实上面已经讲了很多了,下面再详细分析一下task如何竞争内存资源。
task获取Execution内存
task获取Execution的内存也是相对公平的控制,将内存控制在task平均使用内存和task平均使用内存一半之间。相关代码如下:
val maxMemoryPerTask = maxPoolSize / numActiveTasks
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
// How much we can grant this task; keep its share within 0 <= X <= 1 /
numActiveTasks
val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem))
// Only give it as much memory as is free, which might be none if it reached 1
/ numTasks
val toGrant = math.min(maxToGrant, memoryFree)
当获取不到内存时,Spark会让请求的task等待,直到有其他task释放资源,然后该task再去抢占资源。
task获取Storage内存
storage内存的获取就相对复杂一点,因为这受到rdd的cache,persist相关操作的影响。因此和BlockManager和MemStore有关
如果申请的内存大于storage内存池剩余的内存,那么获取Execution内存池是否有剩余,如果有的话就释放Math.min(executionPool.memoryFree, numBytes)。在申请内存之前,还做了一件事件,就是去blockManager尝试释放内存,如果缓存的所有内存实例中,某个blockId下的rdd的id是空,并且存储模式相同(都用jvm或者都不用jvm),那么就会将该blockId释放。如果空余资源小于申请的资源,那么就会申请失败。
代码相关类
MemoryManager
UnifiedMemoryManager
MemoryPool
StorageMemoryPool
ExecutionMemoryPool
MemoryStore