豆瓣网站:https://movie.douban.com/chart
先上最后的代码:
from bs4 import BeautifulSoup from lxml import html import xml import requests from fake_useragent import UserAgent #ua库 import xlwt #表格模块 n = [] #存放电影名称 p = [] #存放电影评分 def get_url(): url = "https://movie.douban.com/chart" ua = UserAgent() headers={'user-agent':ua.random} f = requests.get(url,headers=headers) #Get该网页从而获取该html内容 soup = BeautifulSoup(f.text,'lxml') #用lxml解析器解析该网页的内容, 好像f.content也是返回的html for k in soup.find_all('div',class_='pl2'): #找到div并且class为pl2的标签 b = k.find('a') #在每个对应div标签下找a标签 n.append(b.get_text()) #取标签 a 下的文字,并添加到 n 列表中 for i in soup.find_all('div',class_='star clearfix'): c = i.find_all('span') #在每个对应div标签下找span标签,会发现,一个a里面有四组span t = c[1].string,c[2].string #取相对应span中的字符串,评分和评价人数 p.append(t) #添加到 p 列表中 get_url() #获取数据 style = xlwt.XFStyle() #初始化样式模板 font = xlwt.Font() #初始化字体模板 pattern = xlwt.Pattern() #初始化背景颜色模板 alignment = xlwt.Alignment() #初始化单元格格式模板 font.name = 'Times New Roman' #指定字体 font.bold = True #加黑 font.height = 20*14 #字体 pattern.pattern = xlwt.Pattern.SOLID_PATTERN # 设置背景颜色的模式 pattern.pattern_fore_colour = 2 # 背景颜色 alignment.horz = 0x02 # 0x01(左端对齐)、0x02(水平方向上居中对齐)、0x03(右端对齐) alignment.vert = 0x01 # 0x00(上端对齐)、 0x01(垂直方向上居中对齐)、0x02(底端对齐) #alignment.wrap = 1 # 设置自动换行 style.font = font #应用到style中 style.pattern = pattern # style.alignment = alignment #应用到style中 workbook = xlwt.Workbook() worksheel = workbook.add_sheet('豆瓣电影排行榜') #创建一个新表格 worksheel.write(0,0,'电影名',style) #填写行、列、值 worksheel.write(0,1,'评分',style) for x in range(1,11): for y in range(0,2): if y == 0: worksheel.write(x,y,label=n[x-1]) elif y == 1: worksheel.write(x,y,label=p[x-1]) workbook.save(r"C:UsersfanDesktop豆瓣影评.xls") #创建excel表
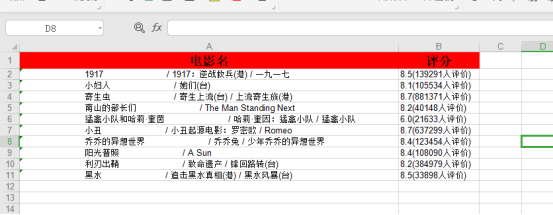
效果图:
思路:
1、进入网页—>F12—>右击影名—>检查—>查看相对应的html代码
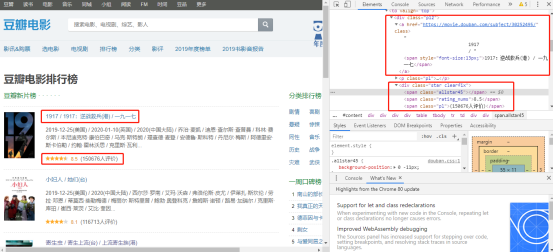
发现影名是存在<div class="pl2">标签下的<a>标签中,使用requests+BeautifulSoup库获取
评分和评价人数存储在<div class="star clearfix">下的<span>标签中。
所涉及到的库,全部是前文《爬虫常用库》中有介绍。