1、multiprocessing模块
(1)介绍
python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu\_count()查看),在python中大部分情况需要使用多进程。 Python提供了multiprocessing。 multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。 multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,>提供了Process、Queue、Pipe、Lock等组件。 需要再次强调的一点是:与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内。
(2)代码实现方式1


# 开启进程方式1:multiprocessing import time from multiprocessing import Process def task(name): print('%s is running' % name) time.sleep(2) print('%s is done' % name) if __name__ == '__main__': p = Process(target=task, args=('子进程1',)) p.start() # 仅仅给os发送了一个信号,我准备要开启一个进程 print('主进程执行结束...')
注意:在windows中Process()必须放到# if __name__ == '__main__':下


2、 Process类
(1)创建进程的类:
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,可用来开启一个子进程 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
(2)参数介绍:
group参数未使用,值始终为None target表示调用对象,即子进程要执行的任务 args表示调用对象的位置参数元组,args=(1,2,'egon',) kwargs表示调用对象的字典,kwargs={'name':'egon','age':18} name为子进程的名称
(3)方法介绍:
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
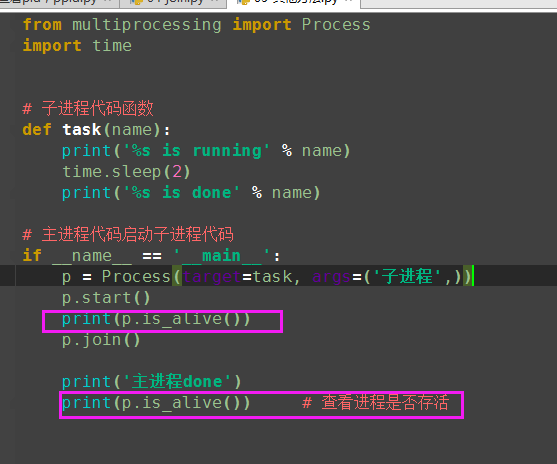
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间。
(4)属性介绍:
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
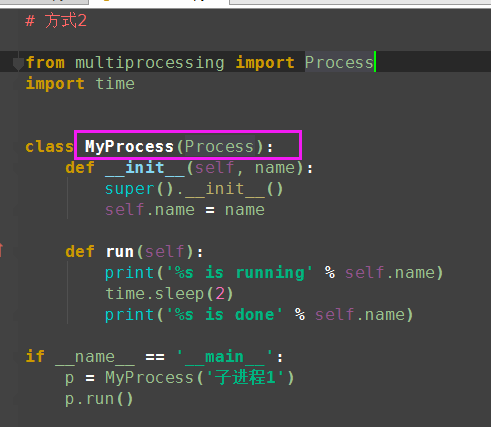
(5)代码实现方式2
3、查看进程的id和父id
from multiprocessing import Process import time import os # 定义子进程的函数 def task(name): print('%s is running' % name, os.getpid()) # 取出子进程的id print('父进程id:', os.getppid()) # 取出父进程的id time.sleep(2) print('%s is done' % name) # 执行父进程,开启子进程 if __name__ == '__main__': p = Process(target=task, args=('子进程1',)) p.start() print('父进程done', os.getpid()) # 该进程的id



4、join方法
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间。


-
(1)和串行执行的区别
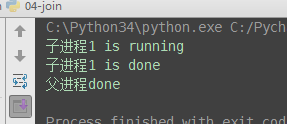
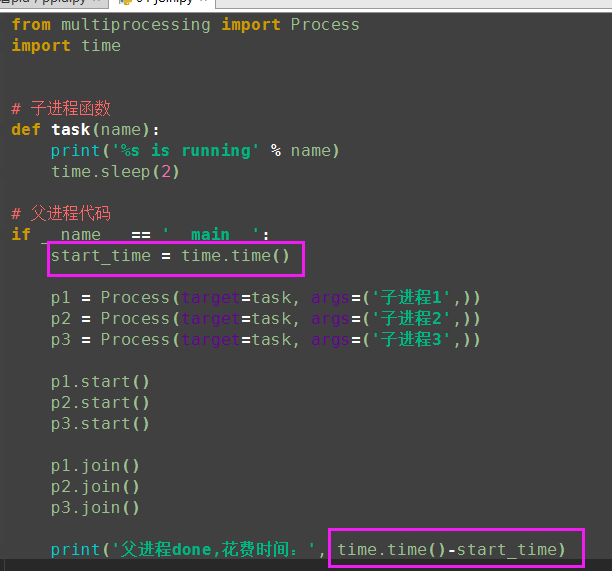
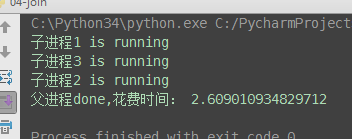
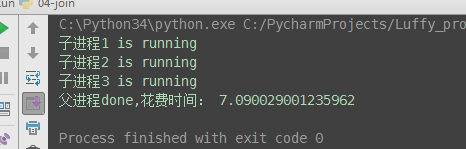
from multiprocessing import Process import time # 子进程函数 def task(name): print('%s is running' % name) time.sleep(2) # 父进程代码 if __name__ == '__main__': p1 = Process(target=task, args=('子进程1',)) p2 = Process(target=task, args=('子进程2',)) p3 = Process(target=task, args=('子进程3',)) p1.start() p2.start() p3.start() # 有的同学会有疑问: 既然join是等待进程结束, 那么我像下面这样写, 进程不就又变成串行的了吗? # 当然不是了, 必须明确:p.join()是让谁等? # 很明显p.join()是让主线程等待p的结束,卡住的是主进程而绝非子进程p, p1.join() p2.join() p3.join() print('父进程done')
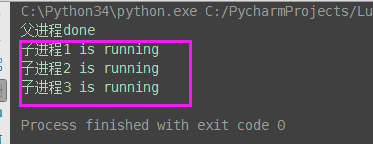


上述启动进程与join进程可以简写为
p_l=[p1,p2,p3,p4]
for p in p_l:
p.start()
for p in p_l:
p.join()
-
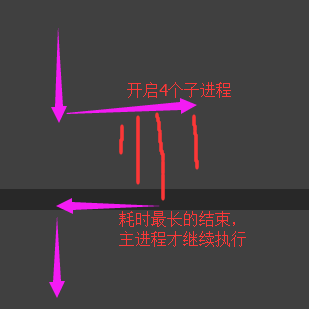
(2)与串行的时间比较
5、Process的其他方法
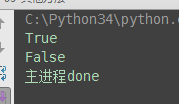
(1)p.is_alive():查看进程是否存活

(2)p1.terminate()#关闭进程,不会立即关闭,所以is_alive立刻查看的结果可能还是存活

(3)name='子进程1':可以用关键参数来指定进程名,系统的系统名

(4)p1.pid:查看进程的ip
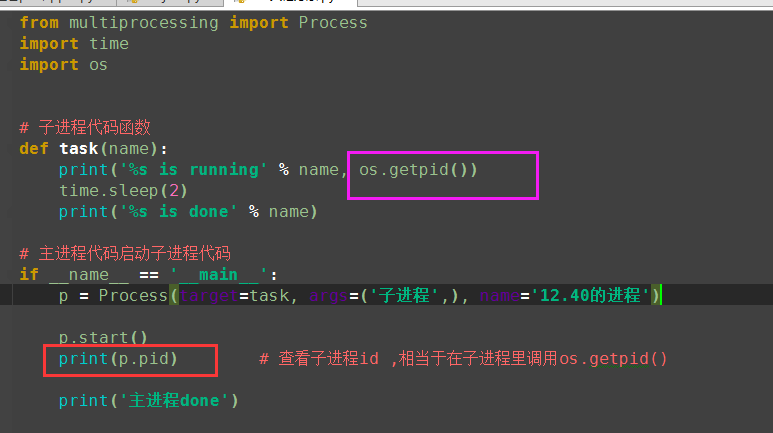
6、僵尸进程、孤儿进程、守护进程
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵尸进程。 (创建了,但是没有获取状态的子进程)

孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
守护进程:在后台运行,不与任何终端关联的进程,通常情况下守护进程在系统启动时就在运行,它们以root用户或者其他特殊用户(apache和postfix)运行,并能处理一些系统级的任务. 习惯上守护进程的名字通常以d结尾(sshd),但这些不是必须的. 例如,syslogd就是指管理系统日志的守护进程。
7.守护进程
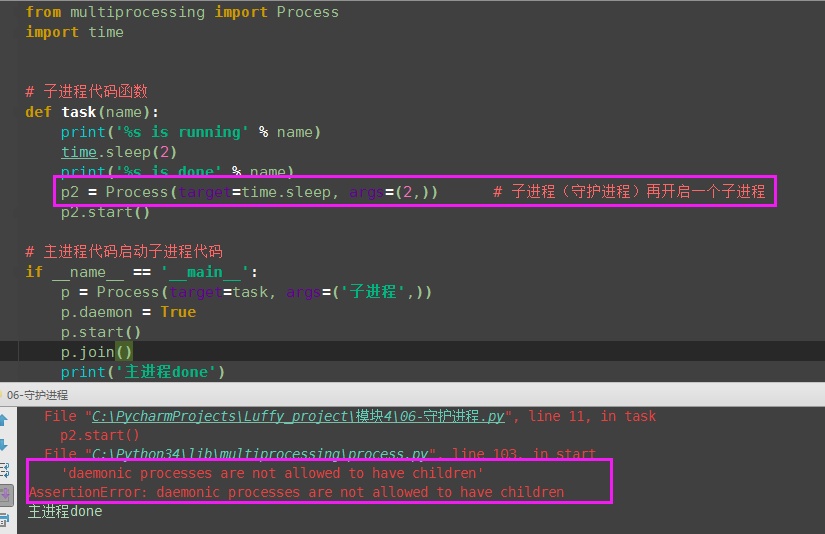
如果我们有两个任务需要并发执行,那么开一个主进程和一个子进程分别去执行就ok了, 如果子进程的任务在主进程任务结束后就没有存在的必要了,那么该子进程应该在开启前就被设置成守护进程。 主进程代码运行结束,守护进程随即终止


(1)守护进程已经start了
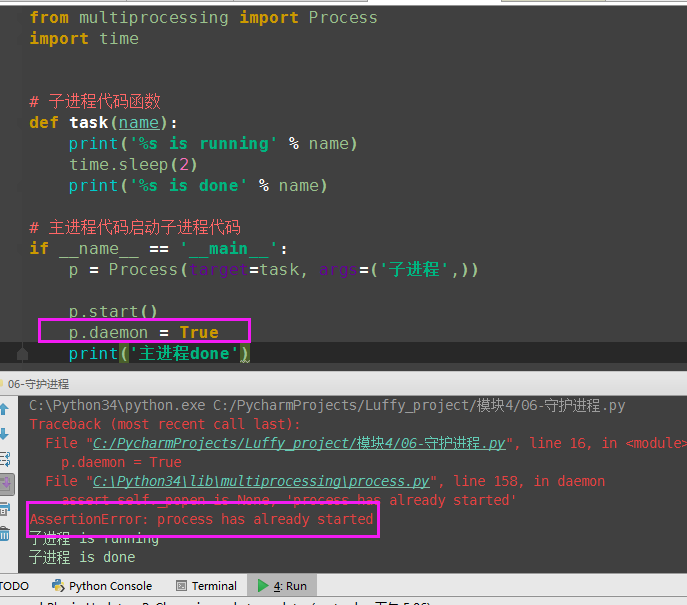
(2)守护进程开启
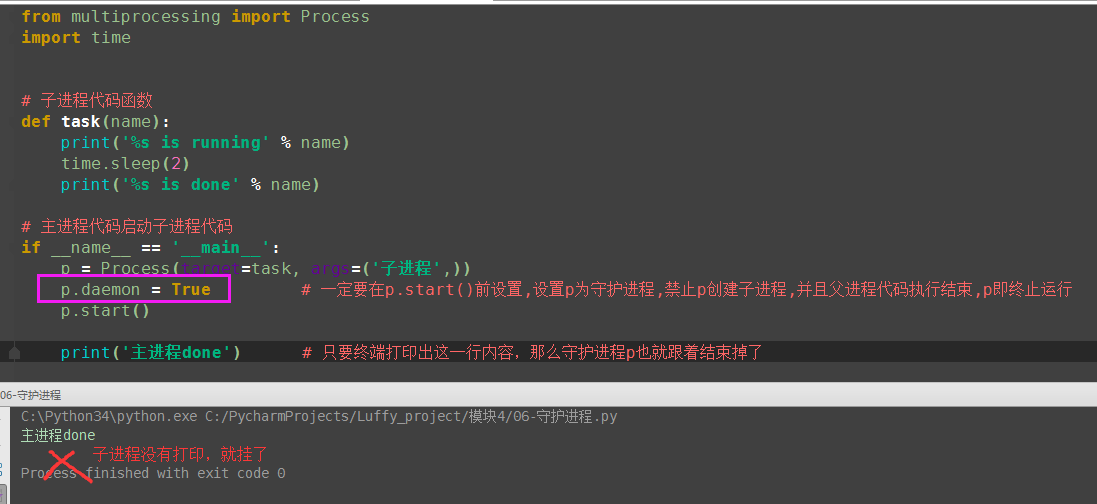
(3)守护进程不允许开启子进程