这只是部分题,答案为个人观点如有错误欢迎指出,感觉考点都挺基础,但是很注重考细节方面,通过整理也知道自己在CSS3和HTML5,网络知识等方面的不足还是得多学多练多思考。攒rp,希望自己在明天360笔试中能轻松答过~
css
1.多选
//HTML <p>很长的一段文字,很长的一段文字,很长的一段文字,特别长的文字</p> //CSS p{ 100px; white-space:nowrap; }
添加以下哪些样式可以使超出部分文字变为"..."。
A.white-space:normal B.overflow:hidden C.overflow:auto D.text-overflow:ellipsis
解析:考察white-space,overflow,text-overflow。选择B和C和D
white-space:描述如何处理元素中空格。初始值normal,适用于所有元素,有继承性。
取值为normal | nowrap | pre | pre-wrap | pre-line
normal 默认,连续的空白符会被合并,换行符会被当作空白符来处理,填充line盒子时,必要的话会换行。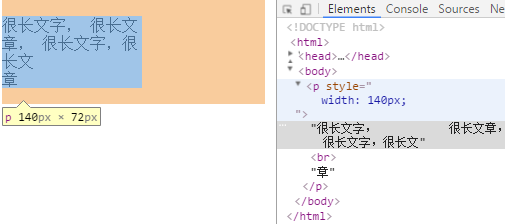
nowrap 翻译过来意思是"不包裹",连续的空白符和换行符会被合并,但文本触碰到边界自动的换行无效,不包裹就体现出了,文本超出给定长度不会换行。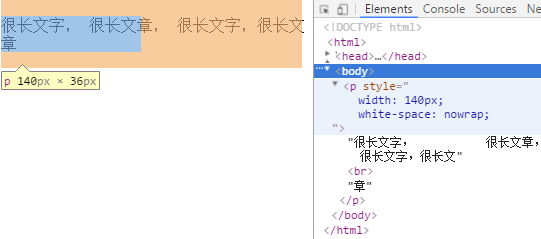
pre 连续的空白符会被保留,在遇到换行符或者<br>元素时才会换行。相当于HTML中的<pre>标签,可预定义格式化的文本。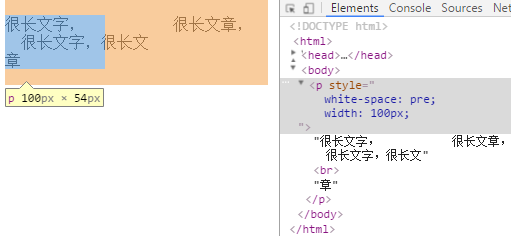
pre-wrap 上面的pre很死板,超出盒子就超出,而pre-wrap意为格式化包裹,既能格式化又能让盒子包裹,所以是连续的空白符会被保留,在遇到换行符或者<br>元素或者需要为了填充line盒子时才会换行。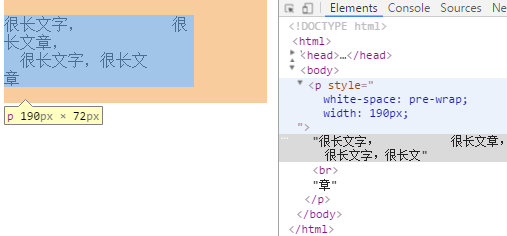
pre-line 连续的空格符会被合并,在遇到换行符或者<br>元素或者需要为了填充line盒子时才会换行。这个更人性化了,注重格式化但更注重换行。
下面表格总结了white-space行为
| 换行符 | 空格和制表符 | 文字换行 | |
| normal | 合并 | 合并 | 转行 |
| nowrap | 合并 | 合并 | 不转行 |
| pre | 不合并 | 不合并 | 不转行 |
| pre-wrap | 不合并 | 不合并 | 转行 |
| pre-line | 不合并 | 合并 | 转行 |
overflow:该属性用于block型元素上,规定当内容元素溢出元素框时要发生的事(即是否设置可修剪并以什么方式修剪):可裁剪内容(隐藏,滚动条),不修剪(直接显示超出部分)。默认值为visible,该属性不继承。使用overflow默认值以外的值将创建一个新的块级格式上下文(BFC)。想了解BFC的同学请戳深入理解BFC和Margin Collapse。
取值 visible | hidden | scroll | auto | inherit
visible 默认值,内容不会被修剪,会呈现在元素框之外。
hidden 内容会被修剪且其余内容是不可见的
scroll 内容会被修剪并且浏览器使用滚动条以便查看其内容,但打印机会打印溢出的内容。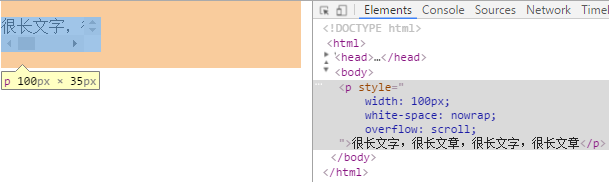
auto 取决于用户代理,必要时显示那个方向的滚动条,FF和chrome会提供滚动条。

text-overflow:决定溢出的内容怎么修剪即以何种形式提示用户,使用该属性的前提是溢出的内容已被设置为可修剪(溢出和修剪是两个概念,溢出后先要设置可被修剪才能设置怎么修剪,否则只设置怎么修剪是不起作用的)。它可以直接剪切(clipped),也可以显示一个省略号,或者显示一个自定义的符号。默认值是clip,适用所有块级元素,没有继承性。
取值 clip | ellipsis | string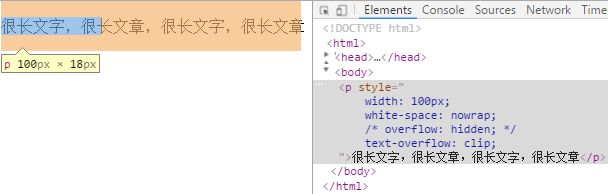
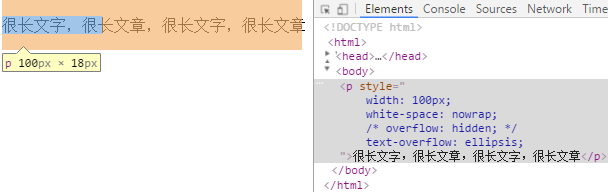
此时怎么设置text-overflow都不起作用,因为当前的overflow值为visible意为不可修剪的( window.getComputedStyle($('p')).overflow;// "visible" )。
设置overflow为可修剪后(取值hidden,scroll,auto均可),这里以overflow:hidden为例
clip 默认值,修剪文本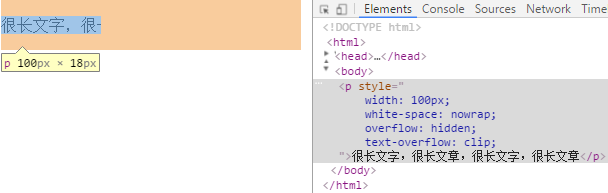
ellipsis 显示省略符合代替被修剪的文本
string 使用给定的字符串来代替被修剪的文本。Chrome浏览器不支持无法演示。
2.红色区域的宽度多大?
//HTML <div>文本</div> //CSS div{ box-sizing:border-box; width:100px; padding:10px; background-color:red; background-clip:content-box; }
解析:考察盒模型,css3box-sizing,background-clip。答案为80px。
盒模型:文档中每个元素被描绘成矩形盒子,确定其大小,属性(颜色背景边框等),以及位置是渲染引擎的目标。
css下这些盒子由标准盒模型描述,这个模型描述元素内容占用空间,盒子有四个边界(外边距边界margin edge,边框边界border edge,内边距边界padding edge,内容边界content edge)
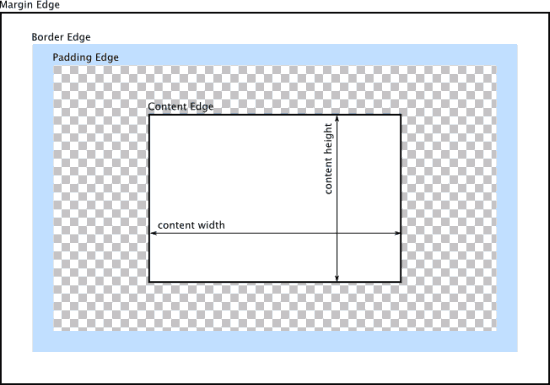
content内容区域 是真正包含元素内容的区域,它的大小为内容宽度/高度或content-box宽/高。如果box-sizing是默认值(content-box),则由width/height,min-width/min-height,max-width/max-height确定其大小。
padding内边距区域 是内容及可能有的边框之间的空白域,用来扩展内容区域。它位于内边距边界内部,背景为颜色或图片(不透明的图片会盖住颜色)。它的大小为padding-box宽和padding-box高。
border边框区域 是包含边框的区域,扩展了内边距区域,大小为border-box宽/高。由border-width及简写属性border控制。
margin外边距区域 用空白区域扩展边框区域,以分开相邻的元素。大小为margin-box的高宽。在外边距合并的情况下盒之间会共享外边距(margin重叠问题可参考css margin重叠的问题)。
注意对于行内非替换元素,其占据高度由line-height决定,与margin和padding无关,为什么?这就要说起em框,内容区,行间距,行内框,行框等概念了想深入的同学可戳一些常用css技巧的为什么(二)我所理解的line-height。
反正你就记住行内非替换元素占据高度(应该说是该行与上一行或下一行之间关系)与margin和padding怎么设置都无关。
box-sizing:用来改变css盒模型对于宽高的计算方式,默认值为content-box,适用于所有元素,没有继承性。
取值 content-box | border-box
content-box 默认值,标准盒模型。width和height只包括内容的宽高,不包括padding+border+margin。比如如果设置350px;border:10px solid black;那么在浏览器中渲染的实际宽度为370px。
border-box width和height包括padding和border,不包括margin。这是IE怪异模式使用的盒模型(在IE5可查看)。比如设置350px;border:10px solid black;浏览器渲染出来的宽度将是350px,真正的内容宽度为330px,如果计算后最内部的内容宽度为负值,都会被计算成0,因为内容还在不可能通过border-box来隐藏。
background-clip: 设置元素的背景(背景图片或颜色)是否延伸到边框下面。默认值为border-box,适用于所有元素,没有继承性。
取值 border-box | padding-box | content-box
border-box 背景延伸到边框外沿但是在边框之下。
padding-box 边框下面没有背景,即延伸到padding的外沿。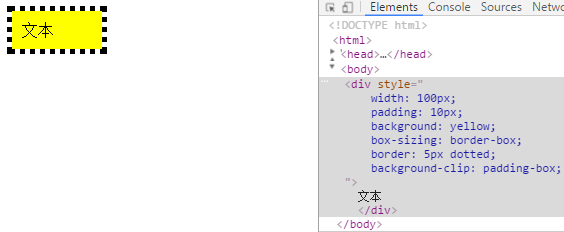
content-box 背景裁剪到内容区content-box外沿。
JavaScript
1.alert分别输出什么值?
var a=2; var func=(function(){ var a=3; return function(){ a++; alert(a); } })(); func(); func();
A.3,4 B.4,4 C.4,5 D.undefiend undefined
解析:考察函数表达式,立即执行函数,闭包,作用域,引用类型等。具体相关知识点就不扩展说了,我觉得既然答案给了D选项这里还应该再考个变量提升多好~正确答案选C。
前两句是赋值语句,全局变量a=2,经立即执行的匿名函数表达式执行后初始化了括号里面那个函数的活动对象AO和作用域链同时确定了this对象,增加了内部变量a=3,返回了一个函数引用。全局变量func指向返回的这个函数的引用(这就是闭包)。第一次执行func(),func指向的内存堆中某个函数对象,经过执行a++,在本函数的作用域中的AO中寻找a变量未果沿着作用域链查找外层作用域的AO,找到a=3,执行a++后a=4,alert(4)。再执行func(),还是执行的是内存堆中的那个函数对象,又一次初始化内存堆中的这个函数的作用域链和AO等,寻找a未果沿着作用域链找外层AO找到a=4,执行a++后a=5,alert(5),完毕!
2.下面代码执行后,arr的值是
var arr=[{a:1},{}]; arr.forEach(function(item,idx){ item.b=idx; });
A.[{a:1},{}] B.[{a:1,b:0},{b:1}] C.[{a:1,b:1},{b:1}] D.[{a:1,b:0},{b:0}]
解析:考察数组的forEach方法,对象添加属性操作,挺基础的题。答案是B
Array.prototype.forEach(callback[,args]) 属于数组迭代方法中的一个,该方法没有返回值。让数组按升序每一项去执行一次callback函数(可接收三个参数:item当前项,idx当前索引,arr数组本身),args可选参数,用来当作callback函数内this值的对象。数组中那些已删除(delete等方式)或从未赋值过的项被跳过(但不包括值被显示赋为undefiend的项)。
3.cookie,sessionStorage,localStorage描述正确的是
A.cookie.setItem()用来设置一个cookie
B.sessionStorage是存储在服务器端的
C.通过localStorage.setItem()可以存储对象类型
D.浏览器重新打开时,localStorage里存储的数据依然存在。
解析:考察HTML5的sessionStorage,localStorage。C错误setItem参数是字符串的键值对。答案为D
document.cookie:保存登陆信息,比如登陆网站时可以看到"记住密码"选项,这通常就是通过在cookie中存入一段辨别用户身份的数据来实现的。
localStorage:本地存储。
sessionStorage:保存数据的生命周期和localStorage不同,它只是可以将一部分数据在当前会话中保存下来,关闭后sessionStorage中的数据会清空。
| 特性 | cookie | localStorage | sessionStorage |
| 生命周期 | 一般由服务器生成可设置失效时间。 如果在浏览器端生成cookie默认是关闭浏览器后失效 |
除非被清除否则永久保存 | 仅在当前会话下有效,关闭页面 或浏览器后被清除 |
| 存放数据大小 | 4k左右 | 5MB左右 | 5MB左右 |
| 与服务器通信 | 每次都会携带在HTTP头中 | 仅在客户端保存不参与通信 | 仅在客户端保存不参与通信 |
4.给Object扩展一个方法clone,实现深度克隆对象。
解析:之前想的太尼玛简单了,以为用for-in遍历赋值就能完成复制,当时也是考虑不全面,代码写的够天真!最后回想起来连对象类型都没考虑到万一还有数组,函数之类的对象,更别说这种写法for-in会把原型上的一些属性也遍历得到这样就把原型上的属性添加到newobj了,越来越不严密...
Object.prototype.clone=function(){ var newobj={}; for(var i in this){ newobj[i]=this[i]; } retrun newobj; }
所以底下这才是大神级别的写法,直接Object.create()一句就压根不用考虑要克隆对象的类型。你说着学也学过用也用过吧,为啥当时就想不到用这个屌炸天的方法,一句话还是不熟练还需努力呀!!
Object.prototype.clone=function(){ //原型指向保持一致 var newobj=Object.create(Object.getPrototypeOf(this)); //自身属性保持一样 var propNames=Object.getOwnPropertyNames(this); propNames.forEach(function(item){ //保持每个属性的特性也一样 var des=Object.getOwnPropertyDescriptor(this,item); Object.defineProperty(newobj,item,des); },this); return newobj; }
5.有这样一个URL,http://mail.163.com/?a=1&b=2&c=3&d=xxx&e。输出函数QuerySearch(),其有一个参数name,输出其对应的value。
解析:主要就是进行两次分割。
function QuerySearch(name){ var url="http://mail.163.com/?a=1&b=2&c=3&d=xxx&e", arr=url.split('?')[1].split('&'), str=name+'=',index,start;for(var i=0;i<arr.length;){ index=arr[i].indexOf(str); if(index<0){ //如果str不在该项中,进入下一项 i++; }else{ start=index+str.length; return arr[i].slice(start); } } //如果都循环完了还没找到,则返回"" return ""; }
通用编程题(不限于编程语言)
1.输入两个数字,输出这两个数字的最大公约数。如16,4输出4。
解析:纯考基础感觉。最大公约数就是<=最小的那个数,那就从最小的那个数开始一个一个试呗,这是最笨的方法但是好理解。
function maxDivisor(num1,num2){ var max=num1>num2?num1:num2, min=num1>num2?num2:num1; for(var i=min;i>=1;i--){ if(max%i==0&&min%i==0){ return i; } } }
顺带也写下最小公倍数就是>=最大的那个数,那就从最大的那个数开始一个一个试呗。
function minDivisor(num1,num2){ var max=num1>num2?num1:num2, min=num1>num2?num2:num1; for(var i=max;i>=max;i++){ if(i%max==0&&i%min==0){ return i; } } }
方法挺多,还有辗转相除法,用递归做。
function maxDivisor(num1,num2){ if(num2==0){ return num1; }else{ return maxDivisor(num2,num1%num2); } }
2.已知一般app版本为1.0.0/1.0.1/1.2.3,其符合a.b.c的规则,将排序不规则约为100w个版本号进行从小到大排序。
解析:算法不精暂时还没啥思路。肯定不是啥冒泡快排吧...想着应该是先按a取值为1,2,3...排序这样分成很多个大组,在在每组里按第二位取值1,2,3排序再分组...好像有点分治还是动态规划的感觉了。
网络和Http
1.ping基于下面哪个协议?
A.ICMP B.TCP C.IP D.UDP
解析:选A
维基百科介绍:ping是一种电脑网络工具,用来测试数据包能否通过IP协议到达特定主机,ping的运作原理是向目标主机传出一个ICMP echo@要求的数据包,并等待接收echo回应的数据包。程序按时间和成功响应的次数估算丢失的数据包率(丢包率)和数据包往返时间(网络时延)。
ICMP:网际控制报文协议,是IP层的一个组成部分,它传递差错报文以及其他需要注意的信息。ICMP报文通常被IP层或更高层协议(TCP/UDP)使用。由图看出它是IP的一部分,而且必须在每个IP模块中实现。
干脆学习一下TCP/IP协议族吧:
互联网协议族(IPS)是一个网络通信模型+一整个网络传输协议家族,它是互联网通信的基础架构。也被成为TCP/IP协议族,简称TCP/IP,这个协议家族的两个核心协议包括TCP(传输控制协议)和IP(网际协议)。在网络通讯协议普遍采用分层的结构,当多个层次协议共同工作时,类似于计算机中堆栈。TCP/IP提供点对点链接机制,将数据应该如何封装,定址,传输,路由以及在目的地如何接收都加以标准化。它将软件通讯过程抽象化为四个抽象层,采用协议堆栈的方式,分别实现不同通讯协议。
七层OSI模型
物理层:通过媒介传输比特Bit。
数据链路层:将比特组装成帧和点到点的传递,在两个网络实体间提供数据链路连接的创建,维持和释放管理。
网络层:提供路由和寻址功能,负责数据包从源到宿的传递和网际互连。
传输层:提供端到端的可靠报文传递和错误恢复。负责总体数据的传输和数据控制,对其上面三层提供可靠的传输服务。(段)
会话层:建立,管理和终止会话,会话用户之间的数据传送过程是将SSDU(用户数据单元)转变为SPDU(会话协议数据单元)。
表示层:对数据进行翻译,加密和压缩。为不同终端的上层用户提供数据和信息的正确语法表示转换方法。(表示协议数据单元PPDU)
应用层:直接和应用程序接口并提供常见的网络应用服务。(应用协议数据单元APDU)
TCP/IP四层模型
2.以下HTTP头信息中,跟缓存有关的有?
A.cache-control B.Expires C.Last-Modified D.ETag
解析:答案全选
cache-control:最重要的规则,这个字段用于指定所有缓存机制在整个请求/响应链中必须服从的指令。常见取值为private(默认),no-cache,max-age,must-revalidate等
Expires:翻译为"到期",允许客户端在这个时间之前不去发送请求。给出的日期和时间后,被响应认为是过时,需要和Last-Modified结合使用,用于控制请求文件的有效时间,当请求数据在有效期内时客户端从缓存请求数据而不是服务器端,当缓存数据失效或过期才从服务器更新数据。Last-Modified是能节省一点宽带,但还是逃不掉发一个HTTP请求出去,而且要和Expires一起用。而Expires标识却使得浏览器连HTTP请求都不用发,比如当用户按F5或点击刷新按钮时就算对于只有Expires的URI一样也会发请求,所以Last-Modified和Expires一起用。
Last-Modified:当浏览器第一次请求某个URL时,服务端返回状态码为200,内容是你请求的资源,同时有个Last-Modified的属性标记(HttpResponse Header)此文件在服务器端最后被修改的时间,格式类似Last-Modified:Thu, 08 Nov 2012 09:29:25 GMT。当客户第二次请求此URL时,根据HTTP协议规定,浏览器会向服务器传送If-Modified-Since报头(HttpRequest Header)询问该时间之后文件是否被更改过,If-Modified-Since:Thu, 08 Nov 2012 09:29:25 GMT,如果服务器端资源没有变化则自动返回304状态码,内容为空,这样就节省了数据传输量。当服务器端代码发生改变或重启服务器时,则重新发送资源,返回和第一次请求类似。
ETag:被请求变量的实体标记,即服务器响应时给请求URL标记,并在HTTP响应头中将其传送到客户端,格式为ETag:"f65e34b472a13e773a65109614ea9be8",告诉客户端你拿到的这个资源有表示ID:f65e34b472a13e773a65109614ea9be8。当下次需要索取同一个URI时候,客户端发出一个格式为If-None-Match:"f65e34b472a13e773a65109614ea9be8"的报头,如果Etag没改变,返回状态304
3.HTTP状态码
1xx:请求已被接收,需要继续处理。这类响应是临时响应只包含状态行和某些可选的响应头信息。
2xx:请求已成功被服务器接收,理解并接受。
206:服务器已成功处理了部分GET请求,应用为断点续传或将一个大文件分解为多个下载段同时下载。
3xx:重定向,客户端需要采取进一步的操作才能完成请求,
302:临时重定向,请求的资源临时从不同的URI响应
4xx:客户端看起来可能发生错误妨碍了服务器的处理。
403:没有权限访问此站。服务器理解了本次请求但拒绝执行该任务。
5xx:服务器在处理请求过程中有错误或异常状态发生。
500:服务器遇到一个未曾预料的状况导致它无法完成对请求处理。
503:临时的服务器维护或过载,无法处理当前请求。
其他计算机相关
1.关系型数据库与非关系型数据库
关系型数据库:采用关系模型来组织数据的数据库
非关系型数据库:数据结构化存储方法的集合,数据的持久存储以及海量存储需要
2.代码以非递归的方式实现一个深度优先搜索,借助
A.队列 B.栈 C.散列 D.堆
解析:选B栈
深度优先遍历的执行过程如下,设计一个栈来模拟递归实现中系统设置的工作栈,
(1)栈初始化;
(2)输出起始顶点,起始顶点改为"已访问"标志,将起始顶点进栈,重复下列操作直至栈顶为空
- 取栈顶元素顶点(不是出栈,只是取出来)
- 栈顶元素顶点若存在未被访问过的邻接点w,则
输出顶点w
将顶点w改为"已访问"标志
将顶点w进栈 - 否则当前顶点退栈
参考:
MDN white-space
MDN overlow
CSS3 text-overflow属性
MDN 盒模型
MDN box-sizing
MDN background-clip
MDN Array.prototype.forEach()
简单了解ICMP协议
TCP/IP 协议族
浏览器缓存详解:expires,cache-control,last-modified,etag详细说明
翻译:web制作,开发人员需知的web缓存知识
HTTP状态码
详说Cookie,LocalStorage与SessionStorage
关系型数据库和非关系型数据库
深度优先遍历算法的非递归实现