array--国定类型数据序列
array模块定义一个序列数据结构,看起来和list非常相似,只不过所有成员都必须是相同的基本类型。
1、初始化
array实例化时可以提高一个参数来描述允许哪个种数据类型,还可以有一个初始的数据序列存储在数组中。
1 import array 2 import binascii 3 s = 'This is the array.' 4 a = array.array('c',s) 5 6 print 'As string:', s 7 print 'As array :', a 8 print 'As hex :', binascii.hexlify(a)
运行结果:

这个例子总,数组配置为包含一个字节序列,用一个简单的字符串初始化,array.array('c','xxxx') 中的‘c’代表是字符串的意思。
其中binascii模块的作用是:其中包含很多在二进制和ASCII编码的二进制表示转换的方法。hexlify(data) 作用是返回的二进制数据的十六进制表示。
2、处理数组
类似于其他的Python序列,可以采用同样的方式扩展和处理array
1 import array 2 3 4 a = array.array('i',xrange(3)) 5 print 'Initial :', a 6 7 a.extend(xrange(3)) 8 print 'Extended:',a 9 10 print 'Slice :',a[2:5] 11 12 print 'Iterator' 13 print list(enumerate(a))
执行结果:
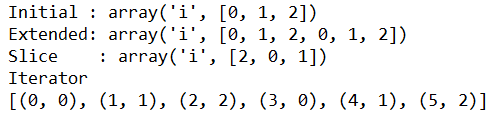
目前支持的操作包括分片、迭代以及向末尾增加元素。
使用enumerate(data)迭代数据,返回的是序列的每条记录的序号和内容组成的元组
3、数组与文件
可以使用高效读写文件的专用内置方法将数组的内容写入文件或者从文件读入数组。
1 import array 2 import binascii 3 import tempfile 4 5 a = array.array('i',xrange(5)) 6 print 'A1:',a 7 8 output = tempfile.NamedTemporaryFile() 9 a.tofile(output.file) 10 output.flush() 11 12 with open(output.name,'rb') as input: 13 raw_data = input.read() 14 print 'Raw Contents:',binascii.hexlify(raw_data) 15 16 input.seek(0) 17 a2 = array.array('i') 18 a2.fromfile(input, len(a)) 19 print 'A2:',a2
执行结果:
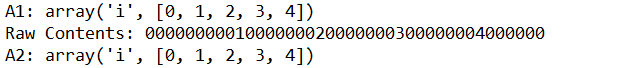
这个例子展示了直接从二进制文件读取原始数据,将它读入一个新的数组,并吧字节转换为适当的类型。
with 用法(可以增加代码的友好度,它自身可以关闭文件无需调用close()方法):
with open('a.txt') as f:
print f.readlines()
4、候选字节顺序
如果数组中的数据没有采用固有的字节顺序,或者在发送到一个采用不同字节顺序的系统之前需要交换顺序,可以由Python转换整个数组而无需迭代处理每一个元素。
1 import array 2 import binascii 3 4 def to_hex(a): 5 chars_per_item = a.itemsize * 2 6 hex_version = binascii.hexlify(a) 7 num_chunks = len(hex_version) / chars_per_item 8 for i in xrange(num_chunks): 9 start = i * chars_per_item 10 end = start + chars_per_item 11 yield hex_version[start:end] 12 13 a1 = array.array('i',xrange(5)) 14 a2 = array.array('i',xrange(5)) 15 a2.byteswap() 16 17 fmt = '%10s %10s %10s %10s' 18 print fmt % ('A1 hex','A1','A2 hex','A2') 19 print fmt % (('-'*10,) * 4) 20 for values in zip(to_hex(a1),a1,to_hex(a2),a2): 21 print fmt % values
处理结果:

其中byteswap()方法会交换C数组中元素的字节顺序,比在Python中循环处理数据高效的多。
如果 yield 存在在一个函数中那么整个函数就是 一个Generator 具体用法请参照:http://blog.csdn.net/scelong/article/details/6969276
zip()函数 可以接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表