一. 基础语句
1. 数据库操作
数据库连接 mysql -u用户名 -p密码 -h主机名称 -h主机名称如果实在本机则可以省略
执行sql命令时,分号不能省略。
查看数据库(所有的) show databases;
查看指定数据库 show create database db_name;
创建数据库 create database db_name;
修改数据库编码 alter database db_name default character set utf8;
使用数据库 use db_name;
删除数据库 drop database db_name;(不能一次删除多个!)
2. 数据表操作
查看所有表 show tables ;
查看某个表的创建语句 show create table 表名;
查看某个表信息 desc 表名;
创建表 create table 表名(列名 数据类型 [not null] [primary key],列名 数据类型 [not null],..) ;
删除表记录 delete from 表名; delete * from 表名;
删除表 drop table 表名;(删除整个表结构和表记录)
更改表名 rename table 旧表名 to 新表名;
增加一个列 Alter table 表名 add column 列名 数据类型;(column 关键字可省略)
删除一个列 Alter table 表名 drop column 列名; (column 关键字可省略)
修改一个列 Alter table 表名 change column 列名 新列名 数据类型;(可修改 列名 数据类型)
修改一个列 Alter table 表名 modify column 列名 数据类型;(可修改 数据类型)
3. 数据记录操作
查看表的所有记录 select * from 表名 *代表所有列 也可以select `列名`,`列名` from 表名;
增加表内容 插入数据 insert into 表名(列名,列名...)values(值,值...);
修改列中的一条记录 update 表名 set 列=值 where 列=值;
删除列中的一条记录 delete from 表名 where 列=值;
二. 高级查询语句
1. like
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
select 字段名,字段名 from 表名 where 字段名 like pattern
like 匹配/模糊匹配,会与 % 和 _ 结合使用。
- '%a' 以a结尾的数据
- 'a%' 以a开头的数据
- '%a%' 含有a的数据
- '_a_' 三位且中间字母是a的
- '_a' 两位且结尾字母是a的
- 'a_' 两位且开头字母是a的
2. top
TOP 子句用于规定要返回的记录的数目。
select top 2 * from 表名;
TOP 子句用于规定要返回的记录的百分比。
select top 50 percent * from 表名;
3. order by
用于根据指定的列对结果集进行排序。
select * from 表名 order by 字段名 desc/asc;
asc 升序;
desc 降序;
结果集默认以升序排序;
4. group by
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
select name, count(*) from table_name group by name;
分组查询时添加约束条件
select * from table_name group by name having 条件;
5. in
IN 操作符允许我们在 WHERE 子句中规定多个值.
select * from 表名 where 字段名 in (value1,value2,value3);
6. between
会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
select name, count(*) from 表名 where 字段名 between value1 and value2;
7. union
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
select * from 表1 union select * from 表2;
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
select * from 表1 union all select * from 表2;
另外,UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
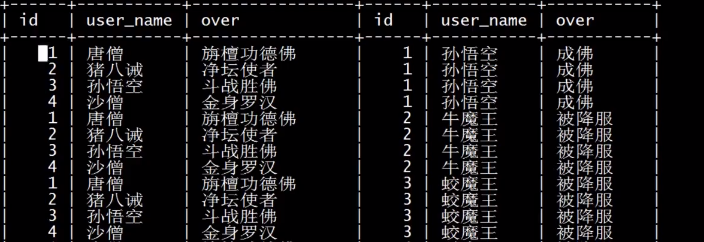
三. 多表联合查询
将两张表的列组合在一起产生新的结果集。
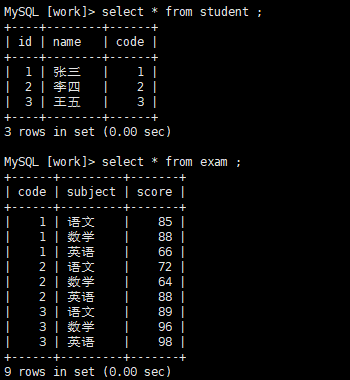
create table student (id int, name varchar(20), code int); insert into student(name,code) values('张三', 1),('李四',2),('王五',3); create table exam (code int, subject varchar(120), score int); insert into exam(code,subject,score) values(1,'语文',85),(1,'数学',88),(1,'英语',66),(2,'语文',72),(2,'数学',64),(2,'英语',88),(3,'语文',89),(3,'数学',96),(3,'英语',98);
1. inner join(内连接)
在表中存在至少一个匹配时,INNER JOIN 关键字返回行。
先在表一中查询出一套记录,再根据后面的条件筛选从表一查询的记录。
select table1.field1,table2.field1 from table1 inner join table2 on table1.field= table2.field;
此处的 inner 可省略;

2. left join(左外连接)
将左表中所有的基础查询出来,再将右表中符合条件的记录查询出来,不符合条件的记录显示为NULL;
先从左表查询出一套记录,再根据条件去匹配右表,如果匹配不到,则结果集中右表对应的字段显示为NULL
select table1.field1,table2.field1 from table1 left join table2 on table1.field= table2.field;

先从左表查询出一套记录,再根据条件去匹配右表,通过 where 子句 进行过滤筛选,此时一般根据右表的字段进行筛选;
select table1.field1,table2.field1 from table1 left join table2 on table1.field= table2.field where table2.field 条件;

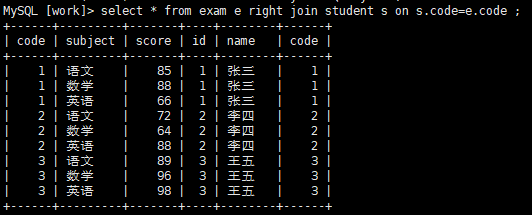
3. right join(右外连接)
将右表中所有的基础查询出来,再将左表中符合条件的记录查询出来,不符合条件的记录显示为NULL;
先从右表查询出一套记录,再根据条件去匹配左表,如果匹配不到,则结果集中左表对应的字段显示为NULL
select table1.field1,table2.field1 from table1 right join table2 on table1.field= table2.field;
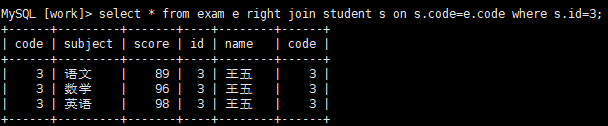
先从左表查询出一套记录,再根据条件去匹配右表,通过 where 子句 进行过滤筛选,此时一般根据左表的字段进行筛选;
select table1.field1,table2.field1 from table1 left join table2 on table1.field= table2.field where table1.field 条件;
4. union(联合查询)
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
select * from table1 union select * from table2;
查询的结果自动去重
select * from table1 union all select * from table2;
不去重
5. full join (全外连接)
mysql本身不支持全外连接,用左右连接可实现全连接效果
通过 union 合并左外连接和右外连接
select table1.field1,table2.field1 from table1 left join table2 on table1.field= table2.field
union all
select table1.field1,table2.field1 from table1 right join table2 on table1.field= table2.field;
6. cross join(交叉连接)
得到两个表的乘积。即笛卡尔积。
select * from table1 cross join tablle2;
用 table1的每一条记录去匹配 table2 的所有记录;
若 table1有4条记录,table2 有5条记录,则结果就有4x5=20 条记录;