一、分类精准度的缺陷
1)评论算法的好坏
- 回归问题:MSE、MAE、RMSE、R^2(以为最好的标准);
- 分类问题:分类准确度(score() 函数);
- 分类算法的评价要比回归算法的评价标准复杂的多;
- 评论分类算法好坏的指标,有多种,具体选择评价指标时要根据数据和应用场景而定;
2)分类准确度类评价分类算法的好坏存在问题
-
实例说明
- 任务:搭建一个癌症预测系统,输入一个人体检的信息指标,可以判断此人是否有癌症;
- 思路:收集大量的数据,训练机器学习算法模型,进而完成癌症预测系统;
- 疑问:如果该系统的预测准确度为 99.9% ,该系统是好?是坏?
- 情景1:如果该种癌症在人群中产生的概率只有 0.1%,那么即使随便一个系统,预测所有人都是健康,该系统也可达到 99.9% 的准确率;也就是说,即使该系统什么都不做,也可以达到 99.9% 的准确率;
- 情景2:如果该种癌症在人群中产生的概率只有 0.01%,此时即使系统什么都不做,其预测准确率也能达到 99.99%,则该机器学习算法的模型是失败的;
3)分析
- 原因:对于极度偏斜(Skewed Data)的数据,只使用分类准确度是远远不够的;
- 极度偏斜的数据:不同类型的样本的数量的差距特别大;如该种癌症患者和健康人,比例为 1:1000 或者 1:10000;
- 面对这种极度偏斜的数据,分类准确度非常的高,其实算法是不够好的,甚至有些情况下非常烂的算法也能得到非常高的准确度;
4)方案
- 方案:使用混淆矩阵做进一步的分析;
二、混淆矩阵(Confusion Matrix)
- 混淆矩阵:分类任务中的重要工具,大多应用于二分类问题,通过混淆矩阵可以得到更好的衡量分类算法好坏的指标;
- 精准率和召回率:衡量分类算法坏话的指标,就是通过混淆矩阵所得;
1)二分类问题中混淆矩阵
- 为 2 X 2 的矩阵,只有 4 个数;
-
混淆矩阵的创建
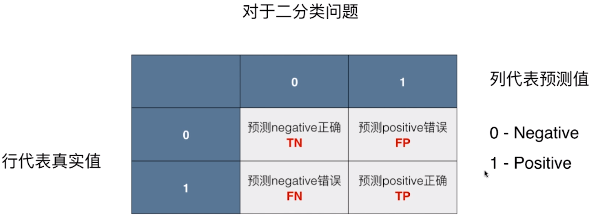
- 矩阵的最上一行代表预测值,最左列为真实值;
- 0 - Negative、1 - Positive;
- TN、FP、FN、TP:表示预测结果的样本数量;
- TN(True Negative):实际值为 Negative,预测值为 Negative,预测 negative 正确;
- FP(False Positive):实际值为 Negative,预测值为 Positive,预测 Positive 错误;
- FN(False Negative):实际值为 Positive,预测值为 Negative,预测 Negative 错误;
- TP(True Positive):实际值为 Positive,预测值为 Positive,预测 Positive 正确;
2)实例解释
- 还是 癌症患者预测:训练样本 10000 人,下面是预测结果的混淆矩阵;
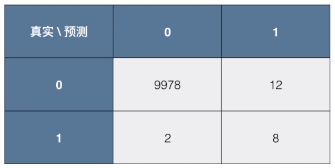
- 9978:9978 个人本身没有换癌症,同时算法预测他们也没有还癌症;
- 12:12个人本身没有患癌症,但算法预测他们患有癌症;
- 2:2个人本身患有癌症,但算法预测他们没有患癌症;
- 8:8个人本身患有癌症,同时算法预测他们也患有癌症;
三、精准率和召回率
- 精准率和召回率:衡量分类算法坏话的指标,就是通过混淆矩阵所得;
- 对于有偏的数据的分类中,通常将 1 作为关注的事件,精准率就是指预测所关注的事件的准确率;
- 所关注的事件:人群中的癌症患者;
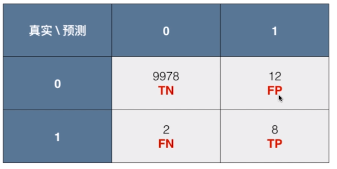
1)精准率(precision)
- 精准率:预测所关注的事件的结果中(共预测了 20 次),预测正确的概率(8 次正确,12 次错误);
- 精准率 = TP / (TP + FP) = 8 / (8 + 12) = 40%
- 含义:每做 100 次患病的预测,平均会有 40 次是正确的;
2)召回率(recall)
- 召回率:对所有所关注的类型(癌症患者,共 10 个),将其预测出的概率(预测出 8 个);
- 召回率 = TP / (TP + FN) = 8 / (8 + 2) = 80%
- 解释:每当有 100 个癌症患者,通过该预测系统,能够成功的找出 80 个癌症患者;
3)精准率和召回率比准确率好的原因
- 结合实际的业务要求:目的是要根据体检信息,更准确和高效的找出癌症病人;准确率并不能反映系统是否找出了全部的癌症病人,或者找出了多大比例的癌症病人;而精准率和召回率更能直接的反应系统能够找出癌症病人的能力;
- 业务的目的也是所关注的事件;