hive执行计划解析
Hive wiki - LanguageManual Explain
1.hive执行流程的重要性
1)当sql任务非常慢时,就需要分析它的执行流程
2)常见的面试中,问对hive的理解?回答只是写sql,这个是很片面的。要从表面的sql,在脑海中映射出MR流程,在哪儿进行map,combiner,shuffle,reduce
2.解析sql执行计划流程
2.1 大数据两类sql框架
单表分析:select a,聚合函数 from XXX group by b
多表join分析:select a.,b. from a join b on a.id=b.id
这两种sql框架,概括了所有的大数据sql,几乎不可能有第三种写法,区别可能是业务复杂,写的复杂点儿而已。
2.2 解析sql执行计划流程详解

1)parser:将sql解析为AST(抽象语法树),会进行语法校验,AST本质* * 还是字符串
2)Analyzer:语法分析,生成QB(query block)
3)Logicl Plan:逻辑执行计划解析,生成一堆Opertator Tree
4)Logicl Optimizer:进行逻辑执行计划优化,生成一堆Opertator Tree
5)Phsical plan:物理执行计划解析,生成 tasktree
6)Phsical Optimizer:进行物理执行计划优化,生成 t优化后tasktree,该任务即是在集群上执行的作业 任务
六步将普通的sql映射成了作业任务。重点是 逻辑执行计划优化和物理执行计划优化
3.sql执行计划映射MR流程
3.1过滤类查询sql
select a.id,a,city, a.cate form access a where a.day=’20190414’ and a.cate= ‘奔驰’

整个job是没有reduce的,类似etl作业。其中map数是由文件分片数决定。分区条件直接在数据读取时过滤
3.2分组聚合类查询sql
select city, count(1) form access a where a.day=’20190414’ and a.cate= ‘奔驰’ group by city
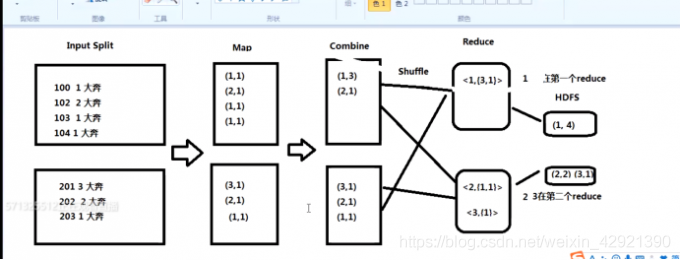
和WC的流程没有本质区别,如上图combiner是本地局部的redece,好处是减少shuffle的数据量,但不是任何场景都会发生combiner,如求平均数。
3.3join类查询sql
待补充
4. 执行计划优化
待补充
扩展1: reducebykey和groupbykey的区别,前者会发生combiner 局部聚合,而后者不会,前者获得的是相同key对应的一个元素,后者是获取元素集合。reducebykey更加适合大数据,少用groupbykey(全数据shuffle)
扩展2: map task数是由数据文件分片数决定的分片数即是map任务数,程序员只能给个期望值
扩展3: reduce task数是由输入reduce的数据的分区(partitions)数决定的即分区数为map任务数,默认是1,程序员可直接设置reduce个数来改变reduce task数,reduce task数决定来 生成的文件数。
扩展4: MR数据shuffle确定数据发往哪一个reduce分区的规则是:取key的hashcode值对分区数模。
扩展5: explain sql ;查看某sql语句的执行计划
来源于:https://blog.csdn.net/weixin_42921390/article/details/115289415?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
===========================================================================================================================================================================================================================================================================
explain
select s0.sno,count(distinct s0.sname)
from
student s0
left outer join student1 s1 on (s0.sno=s1.sno)
group by s0.sno;
这里有两张表,一个student表,一个student1表。两个表的sno,做一个join操作。并且对 sno进行分组,然后将分组完成之后的表达式中的sname不同的条数统计出来。
下面我们执行这个解释语句,执行的结果如下:
STAGE DEPENDENCIES:
Stage-5 is a root stage
Stage-2 depends on stages: Stage-5
Stage-0 depends on stages: Stage-2
--这里将整个的语句划分为三个阶段,Stage-5作为根目录,然后Stage-2是对Stage-5的依赖。最后Stage-0将结果显示出来
STAGE PLANS:
Stage: Stage-5
Map Reduce Local Work
Alias -> Map Local Tables:
s1 --这里先进行第一次的map,然后这里将第二张表的表名加载进来,标记别名。这里进行的Fetch 操作。
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree: --这里是本地的map 操作加载数据。
s1
TableScan
alias: s1
Statistics: Num rows: 40 Data size: 160 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator --这里进行的hash操作。下面是条件表达式。
condition expressions:
0 {sno} {sname}
1
keys:
0 sno (type: int)
1 sno (type: int)
Stage: Stage-2 --然后进入到第二阶段。在这个阶段才是真正的map reduce阶段。
Map Reduce
Map Operator Tree: --这里进行的map操作。
TableScan --首先扫描坐标的表。
alias: s0
Statistics: Num rows: 3 Data size: 320 Basic stats: COMPLETE Column stats: NONE
Map Join Operator --这里采用的hive吧这条sql解释为了map join。
condition map:
Left Outer Join0 to 1 --这里进行连接。将左表和右表进行连接。
condition expressions:
0 {sno} {sname}
1
keys:
0 sno (type: int)
1 sno (type: int)
outputColumnNames: _col0, _col1 --这里输出两列。分别是sno,sname。
Statistics: Num rows: 44 Data size: 176 Basic stats: COMPLETE Column stats: NONE
Select Operator --在这里执行了一次select操作。
expressions: _col0 (type: int), _col1 (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 44 Data size: 176 Basic stats: COMPLETE Column stats: NONE
Group By Operator --在hive当中,为了优化sql,在数据进入到reduce端之前,会对数据进行简单的分组。在这里将分组的sno和sname,作为健,输出的三个列的数据。
aggregations: count(DISTINCT _col1)
keys: _col0 (type: int), _col1 (type: string)
mode: hash
outputColumnNames: _col0, _col1, _col2 --这里进行三个列的输出对于这 _col2,我的理解是两个列组成的和。
Statistics: Num rows: 44 Data size: 176 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator --在这里我们可以看到在进入到reduce之前,需要进行一些操作。
key expressions: _col0 (type: int), _col1 (type: string)
sort order: ++ --这里对数据进行分组排序,也是shuffle过程的前期准备。对同一个map task端的数据进行排序。
Map-reduce partition columns: _col0 (type: int) --这里将对map出的数据进行分组,这里是将数据按照group by的列名称进行分作输送到不同的partition当中。
Statistics: Num rows: 44 Data size: 176 Basic stats: COMPLETE Column stats: NONE
Local Work:
Map Reduce Local Work
Reduce Operator Tree: --在这里我们的数据进入到reduce阶段的处理。
Group By Operator --在这里才是正真的分组。
aggregations: count(DISTINCT KEY._col1:0._col0) --然后我们将各个组当中的数据按照我们分好的组,然后统计这个组当中不同的sname的数量。
keys: KEY._col0 (type: int)
mode: mergepartial
outputColumnNames: _col0, _col1 --这里将统计的好书进行输出。
Statistics: Num rows: 22 Data size: 88 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: bigint)
outputColumnNames: _col0, _col1
Statistics: Num rows: 22 Data size: 88 Basic stats: COMPLETE Column stats: NONE
File Output Operator --这里是文件的数据操作,也是落地到磁盘的操作。
compressed: false
Statistics: Num rows: 22 Data size: 88 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat --这个是读入数据的操作。
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat --这个是输出数据的格式。
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0 --在这个阶段我们对刚才处理的数据进行展示处理。
Fetch Operator
limit: -1
Processor Tree:
ListSink
其实这里我们看到数据写磁盘的操作。在map完了之后的阶段。可能是因为数据量不够大的缘故吧。
另外这里采用的是map jion的操作也没有看到在join的时候,出现shuffle的过程。我觉得可能也是数据量太小了吧。直接加载进了分布式缓存当中。才造成现在的现象。
转自:https://www.cnblogs.com/gxgd/p/9463129.html
==================================================================================================================================================================================
数据倾斜时学习hive sql执行计划 Hive sql的一段执行计划 STAGE DEPENDENCIES: Stage-1 is a root stage Stage-6 depends on stages: Stage-1, Stage-3 , consists of Stage-7, Stage-8, Stage-2 Stage-7 has a backup stage: Stage-2 Stage-4 depends on stages: Stage-7 Stage-8 has a backup stage: Stage-2 Stage-5 depends on stages: Stage-8 Stage-2 Stage-3 is a root stage Stage-0 depends on stages: Stage-4, Stage-5, Stage-2 一个stage对应一个mapreduce的作业 is a root stage 表示不依赖任何的stage,多个root stage的sql可以开启并行执行 depends on stages 表示依赖的stages必须执行完成之后才能执行 consists of Stage-7, Stage-8, Stage-2 表示的是其中一个stage满足即可。 Stage-7 has a backup stage: Stage-2 表示优先执行stage-7,如果stage-7不满足执行的要求,将会执行stage-2。比如map join的情况,如果小表的大小小于hive.mapjoin.smalltable.filesize小表阈值, 默认为25M,单位byte。就会执行stage-7,如果小表的大小大于小表阈值,将会执行stage-2的mapreduce。结果一样,但是性能会差很多。 join的一些调优参数 --是否自动转换为mapjoin,发生map join可以看到执行的stage对应的执行计划是map local task。而不是mapreduce。map join是将小表加载到内存,然后序列化到磁盘放到hdfs,然后放到所有的节点进行join set hive.auto.convert.join = true; --小表的最大文件大小,默认为25000000,即25M set hive.mapjoin.smalltable.filesize = 25000000; --是否将多个mapjoin合并为一个,针对的是连续多个join。多个join的小表都满足map join的时候可以合并,通过阈值判断合并哪几个还是全部map join合并。 set hive.auto.convert.join.noconditionaltask = true; --多个mapjoin转换为1个时,所有小表的文件大小总和的最大值。如果有两个的和小于阈值,就合并两个,灵活合并map jion set hive.auto.convert.join.noconditionaltask.size = 10000000; 问题: 20210310遇到的数据倾斜问题,3个left join耗时1小时, 事实表数据量70G。 搜索点击数据事实表(数据量比较大)join 搜索关键字的分词维度表 using 搜索关键字 使用搜索关键字当做key在map-reduce进行hash分区,热门的搜索词搜索的记录比较多,这样就会导致数据倾斜。 处理方式 先统计搜索点击事实表中的搜索词有没有为null和''的,统计数量,避免空值导致的数据倾斜。 结果:没有空值的搜索词 判断join的分词维度表是不是小表,查看后发现大小为140M,设置hive.mapjoin.smalltable.filesize大于140M, 结果:执行任务,查看stage的执行情况,发现执行了map local task。而不是mapreduce任务。(查看方法:对比日志中执行的stage和执行计划中的stage就能发现执行的是map local task,而不是mapreduce)。3个left join的sql耗时缩短为30分钟。 继续优化 将多个map join进行合并(也就是将3个left join的map join进行合并)。待补充。
转自:https://www.cnblogs.com/jeasonchen001/p/14514782.html