14.1 设备专用文件
设备专用文件与系统的某个设备相对应。在内核中,每种设备类型都有与之相对应的设备驱动程序,用来处理设备的所有 I/O 请求。
设备驱动程序属内核代码单元,可执行一系列操作,(通常)与相关硬件的输入/输出动作相对应。由设备驱动程序提供的 API 是固定的,包含的操作对应于系统调用 open()、 close()、 read()、 write()、 mmap()以及 ioctl()。每个设备驱动程序所提供的接口一致, 这隐藏了每个设备在操作方面的差异, 从而满足了 I/O 操作的通用性。 某些设备是实际存在的,比如鼠标、磁盘和磁带设备。而另一些设备则是虚拟的,亦即并不存在相应硬件,但内核会(通过设备驱动程序)提供一种抽象设备,其所携带的 API 与真实设备一般无异。 可将设备划分为以下两种类型。 1.字符型设备基于每个字符来处理数据。终端和键盘都属于字符型设备。
2.块设备则每次处理一块数据。块的大小取决于设备类型,但通常为 512 字节的倍数。磁盘和磁带设备都属于块设备。 与其他类型的文件一样,设备文件总会出现在文件系统中,通常位于/dev 目录下。超级用户可使用 mknod 命令创建设备文件,特权级程序( CAP_MKNOD)执行 mknod()系统调用亦可完成相同任务
设备 ID
每个设备文件都有主、辅 ID 号各一。主 ID 号标识一般的设备等级,内核会使用主 ID 号查找与该类设备相应的驱动程序。辅 ID 号能够在一般等级中唯一标识特定设备。命令 ls –l可显示出设备文件的主、辅 ID。 设备文件的 i 节点中记录了设备文件的主、辅 ID。每个设备驱动程序都会将自己与特定主设备号的关联关系向内核注册,藉此建立设备专用文件和设备驱动程序之间的关系。内核是不会使用设备文件名来查找驱动程序的。
14.2 磁盘和分区
常规文件和目录通常都存放在硬盘设备里。 下面几节会介绍磁盘的组织方式,以及如何对其分区。
磁盘驱动器
硬盘驱动器是一种机械装置,由一个或多个高速旋转(每分钟旋转数以千计)的盘片组成。通过在磁盘上快速移动的读/写磁头,便可获取/修改磁盘表面的磁性编码信息。磁盘表面信息物理上存储于称为磁道( track)的一组同心圆上。磁道自身又被划分为若干扇区,每个 扇区则包含一系列物理块。物理块的容量一般为 512 字节(或 512 的倍数),代表了驱动器可读/写的最小信息单元。 尽管现代磁盘速度很快,但读写磁盘信息耗时依然不菲。
首先,磁头要移动到相应磁道(寻道时间);
然后,在相应扇区旋转到磁头下之前,驱动器必须一直等待(旋转延迟);
最后,还要从所请求的块上传输数据(传输时间)。执行上述操作所耗费的时间总量通常以毫秒为单位。相形之下,同样的时间可供现代 CPU 执行数百万条指令。
磁盘分区
可将每块磁盘划分为一个或多个(不重叠的)分区。内核则将每个分区视为位于/dev 路径下的单独设备。
系统管理员可使用 fdisk 命令来决定磁盘分区的编号、大小和类型。命令 fdisk –l 会列出磁盘上的所有分区。 Linux 专有文件/proc/partitions 记录了系统中每个磁盘分区的主辅设备编号、大小和名称。 磁盘分区可容纳任何类型的信息,但通常只会包含以下之一。
文件系统:用来存放常规文件
数据区域:可做为裸设备对其进行访问,一些数据库管理系统会使用该技术。
交换区域:供内核的内存管理之用。
可通过 mkswap(8)命令来创建交换区域。特权级进程(CAP_SYS_ADMIN)可利用 swapon()系统调用向内核报告将磁盘分区用作交换区域。 swapoff()系统调用则会执行反向功能—告之内核,停止将磁盘分区用作交换区域。
14.3 文件系统
文件系统是对常规文件和目录的组织集合。用于创建文件系统的命令是 mkfs。 Linux 的强项之一便是支持种类繁多的文件系统,如下所示。 1.传统的 ext2 文件系统。
2.各种原生( native) UNIX 文件系统,比如, Minix、 System V 以及 BSD 文件系统。
3.微软的 FAT、 FAT32 以及 NTFS 文件系统。
4.ISO 9660 CD-ROM 文件系统。
5.Apple Macintosh 的 HFS。
6.一系列网络文件系统,包括广为使用的 SUN NFS、 IBM 和微软的 SMB、 Novell NCP 以及 Carnegie Mellon 大 学开发的 Coda 文件系统。
7.一系列日志文件系统,包括 ext3、 ext4、 Reiserfs、 JFS、 XFS 以及 Btrfs。 从 Linux 的专有文件/proc/filesystems 中可以查看当前为内核所知的文件系统类型
ext2 文件系统
多年来, ext2是 Linux 上使用最为广泛的文件系统,也是原始 Linux文件系统——ext 的继任者。 近来, 随着各种日志文件系统的兴起, 对 ext2 的使用也日趋减少。有时,在介绍通用文件系统概念时,以一款特定的文件系统实现为例会容易一些,出于这一目的,本章将以 ext2 为例来介绍文件系统
文件系统结构
在文件系统中,用来分配空间的基本单位是逻辑块,亦即文件系统所在磁盘设备上若干连续的物理块。例如,在 ext2 文件系统上,逻辑块的大小为 1024、 2048 或 4096 字节。(使用mkfs(8)命令创建文件系统时,可指定逻辑块的大小作为命令行参数。 )
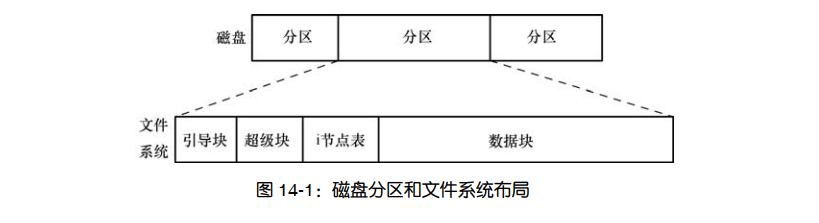
文件系统由以下几部分组成。 1.引导块:总是作为文件系统的首块。引导块不为文件系统所用,只是包含用来引导操作系统的信息。操作系统虽然只需一个引导块,但所有文件系统都设有引导块。
2.超级块:紧随引导块之后的一个独立块,包含与文件系统有关的参数信息,其中包括: - i 节点表容量; - 文件系统中逻辑块的大小; - 以逻辑块计,文件系统的大小; 驻留于同一物理设备上的不同文件系统,其类型、大小以及参数设置(比如,块大小)都可以有所不同。这也是将一块磁盘划分为多个分区的原因之一。
3.i 节点表:文件系统中的每个文件或目录在 i 节点表中都对应着唯一一条记录。这条记录登记了关乎文件的各种信息。有时也将 i 节点表称为 i-list。
4.数据块:文件系统的大部分空间都用于存放数据,以构成驻留于文件系统之上的文件和目录。
14.4 i 节点
针对驻留于文件系统上的每个文件,文件系统的 i 节点表会包含一个 i 节点(索引节点)。对 i 节点的标识,采用的是 i 节点表中的顺续位置,以数字表示。文件的 i 节点号是 ls –li 命令所显示的第一列。 i 节点所维护的信息如下所示。 1.文件类型(比如,常规文件、目录、符号链接,以及字符设备等)。
2.文件属主(亦称用户 ID 或 UID)。
3.文件属组(亦称为组 ID 或 GID)。
4.3类用户的访问权限:属主、属组以及其他用户。
5.3 个时间戳:对文件的最后访问时间( ls –lu )、对文件的最后修改时间( ls –l ),以及文件状态的最后改变时间( ls –lc )。值得注意的是,与其他 UNIX 实现一样,大多数 Linux 文件系统不会记录文件的创建时间。
6.指向文件的硬链接数量。
7.文件的大小,以字节为单位。
实际分配给文件的块数量,以 512 字节块为单位。这一数字可能不会简单等同于文件的字节大小,因为考虑文件中包含空洞的情形,分配给文件的块数可能会低于根据文件正常大小(以字节为单位)所计算出的块数。
8.指向文件数据块的指针
ext2 中的 i 节点和数据块指针
类似于大多数 UNIX 文件系统, ext2 文件系统在存储文件时,数据块不一定连续,甚至不一定按顺序存放(尽管 ext2 会尝试将数据块彼此靠近存储)。为了定位文件数据块,内核在 i 节点内维护有一组指针。图 14-2 所示为在 ext2 文件系统上完成上述任务的情况。
无需连续存储文件块,使得文件系统对磁盘空间的利用更为高效。特别是,还能降低空闲磁盘空间的碎片化程度,即因众多不连续空闲磁盘碎片(因其空间太小而无法使用)而导致的磁盘空间浪费。换言之,对空闲磁盘空间的高效利用,是以已分配磁盘空间中文件的碎片化为代价的。
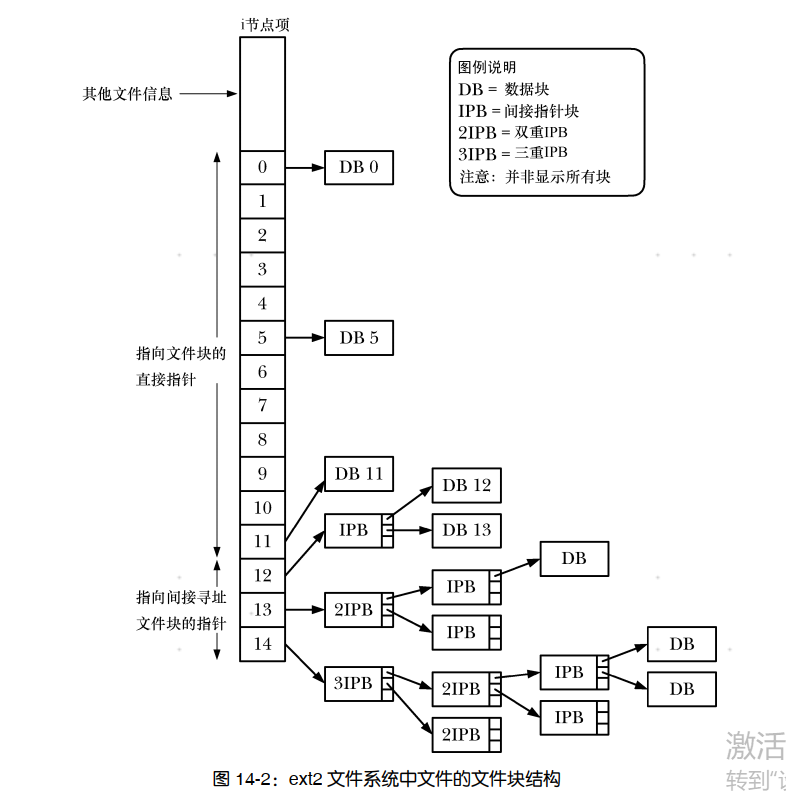
在 ext2 中,每个 i 节点包含 15 个指针。
其中的前 12 个指针(图 14-2 中编号为 0~11 的指针)指向文件前 12 个块在文件系统中的位置。
接下来,是一个指向指针块的指针,提供了文件的第 13 个以及后续数据块的位置。指针块中指针的数量取决于文件系统中块的大小。每个指针需占用 4 字节,因此指针的数量可能在 256(块容量为 1024 字节)~1024(块容量为4096 字节)之间。
这样就考虑了大型文件的情况。即便是对于巨型文件,第 14 个指针(图中编号为 13)是一个双重间接指针—指向指针块,其块中指针进而指向指针块,此块中指针最终才指向文件的数据块。只要有体量巨大的文件,就会随之产生更深一层的递进:图中 i节点的最后一个指针属于三重间接指针。
这一貌似复杂的系统,其设计意图是为了满足多重需求。首先,该系统在维持 i 节点结构大小固定的同时,支持任意大小的文件。
其次,文件系统既可以以不连续方式来存储文件块,又可通过 lseek()随机访问文件,而内核只需计算所要遵循的指针。最后,对于在大多数系统中占绝对多数的小文件而言,这种设计满足了对文件数据块的快速访问:通过 i 节点的直接指针访问,一击必中。
上述设计同样考虑了巨型文件的处理,对于大小为 4096 字节的块而言,理论上,文件大小可略高于 1024×1024×1024×4096 字节,或 4TB( 4096 GB)。 (之所以说“略高于”,是因为指针指向块的方式可以为直接、间接或双重间接。与三重间接指针所指向的范围相比,多出来的那些空间实在是微不足道。 ) 该设计的另一优点在于文件可以有黑洞(如 4.7 节所述)。文件系统只需将 i 节点和间接指针块中的相应指针打上标记(值 0),表明这些指针并未指向实际的磁盘块即可,而无需为文件黑洞分配空字节数据块
14.5 虚拟文件系统
Linux 所支持的各种文件系统,其实现细节均不相同。举例来说,这些差异包括文件块的分配方式,以及目录的组织方式。如果每个与文件打交道的程序都需要理解各种文件系统的具体细节,那么编写与各类文件系统交互的程序将近乎于不可能完成的任务。虚拟文件系统( VFS,有时也称为虚拟文件交换)是一种内核特性,通过为文件系统操作创建抽象层来解决上述问题(参见图 14-3)。
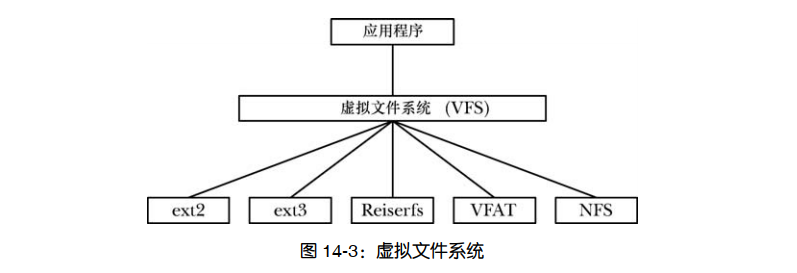
VFS 背后的原理其实很直白
1.VFS 针对文件系统定义了一套通用接口。所有与文件交互的程序都会按照这一接口来进行操作。 2.每种文件系统都会提供 VFS 接口的实现。 这样一来,程序只需理解 VFS 接口,而无需过问具体文件系统的实现细节。VFS 接口的操作与涉及文件系统和目录的所有常规系统调用相对应,这些系统调用有open()、 read()、 write()、 lseek()、 close()、 truncate()、 stat()、 mount()、 umount()、 mmap()、 mkdir()、link()、 unlink()、 symlink()以及 rename()。 VFS 的抽象层建模精确仿照传统的 UNIX 文件系统模型。当然,还有一些文件系统,尤其是非 UNIX 文件系统, 并不支持所有的 VFS 操作。对于这种情况,底层文件系统会将错误代码传回 VFS 层,表明不支持相应操作,而 VFS 随之会将错误代码传递给应用程序
14.6 日志文件系统
ext2 文件系统是传统 UNIX 文件系统的优秀典范,自然也受制于其短板:系统崩溃之后,为确保文件系统的完整性,重启时必须对文件系统的一致性进行检查( fcsk)。由于系统每次崩溃时,对文件的更新可能只完成了一部分,而文件系统元数据(目录项、 i 节点信息以及文件数据块指针)也将处于不一致状态,一旦这一问题得不到修复,那么文件系统会遭到进一步破坏,因此上述举措实属必要。如有可能,就必须进行修复,否则,将会丢弃那些无法获取的信息(可能会包含文件数据)。
问题在于,一致性检查需要遍历整个文件系统。如果文件系统较小,只需几秒或几分钟便可完成。而在大型文件系统上,上述操作可能会历时数小时,这对于需要保持高可用性的系统来说(比如,网络服务器),情况就非常严重。
采用日志文件系统,则无需在系统崩溃后对文件进行漫长的一致性检查。在实际更新元数据之前,日志文件系统会将这些更新操作记录于专用的磁盘日志文件中。对元数据更新的记录是按其相关性分组(以事务的方式记录)进行的。在事务处理过程中,一旦系统崩溃,系统重启时便可利用日志重做( redo)任何不完整的更新,同时为文件系统恢复一致性状态。
借用数据库的说法,日志文件系统能够确保总是将文件元数据事务作为一个完整单元来提交。 系统崩溃之后,即便是超大型的日志文件系统,通常也会在几秒之内复原,因而对于有高可用性需求的系统极具吸引力。
日志文件系统最为昭著的臭名在于增加了文件更新的时间,当然,良好的设计可以降低这方面的开销。
某些日志文件系统只会确保文件元数据的一致性。由于不记录文件数据,因此一旦系统崩溃,可能会造成数据丢失。 ext3、 ext4 和 Reiserfs 文件系统提供了记录数据更新的选项,但若记录的东西过多,则会降低文件 I/O 的性能。
以下列出了 Linux 所支持的日志文件系统。 Reiserfs 是首个被集成进内核(版本号为 2.4.1)的日志文件系统。 Reiserfs 提供了一种名为 tail packing (或 tail merging)的特性:可将小文件(以及较大文件的最后一片)与文件元数据装入相同的磁盘块。而许多系统都拥有(或由应用程序创建了)众多小文件,因此这会节省大量的磁盘空间。
ext3 文件系统,源于一个旨在以最小改动为 ext2 追加日志功能的项目。从 ext2 升级到 ext3 非常简单(无需备份和恢复操作),还支持反向降级。内核版本 2.4.15 集成了ext3。
JFS 由 IBM 开发,内核版本 2.4.20 对其进行了集成。
XFS 最初是由 SGI( Silicon Graphics)于 20 世纪 90 年代初期开发, 所针对的是自己的私有 UNIX 实现: Irix。2001 年, XFS 被移植到了 Linux平台,并成为自由软件项目。 2.4.24 内核对其进行了集成。配置内核时,可在“ File systems”菜单下激活对不同文件系统支持的内核设置选项。
写作本书之际,还有两种提供了日志功能,且支持多种其他高级特性的文件系统尚在开发之中。
ext4 文件系统是 ext3 文件系统的“接班人”。 内核的后续版本中又陆续添加了各种特性。 ext4 的规划(或已实现的)特性包括 extents(预留连续存储块)、旨在降低文件碎片化的其他分配特性、在线文件系统的磁盘碎片整理、更为快捷的文件系统检查以及对纳秒级时间戳的支持。
Btrfs( B-树 FS,一般读作“butter FS”)是一种自下而上进行设计的新型文件系统,意在提供一系列现代化特性,其中包括 extents、可写快照(等价于对元数据和数据的日志功能)、 对数据和元数据的校验和、 在线文件系统检查、在线文件系统的磁盘碎片整理、高效利用空间的小文件打包存放和可检索目录。内核版本 2.6.29 中集成了该文件系统