本节开始线性分类器的另一种模型:模型斯特回归(logistic regression)。
在之前介绍的线性分类器中,h(x)=ΘTx+Θ0,如果h(x)>0,则样本x属于正类,否定x属于负类。直观上的认识,如何h(x)越大,我们更加确信样本属于正类,相应的,h(x)越小,我们更加确信样本属于负类,而h(x)在0之间徘徊,很难确信属于某一类。为了与概率统计知识想结合,可以将h(x)这种“值"上的特性映射到[0,1]之间,logistic 函数(又成sigmoid)函数,就是一个非常优越的选择,logistic 函数定义如下:

函数图象如下:

于是,我们的模型假设为:
![]()
p(ci|x)=hΘ(x) ,模型一旦确定后,我们需要样本去学习模型参数(最大似然估计,最大后验概率估计)。
对于给定样本xi,样本标签yi服从Bernoulli分布:

注意这里与生成式模型的区别,生成式模型我们是对p(x|ci)建模,而在判别式模型我们直接对yi|x建模,样本的似然函数:
![]()
对数似然函数:
![]()
此外,如果将对数似然函数取相反数:
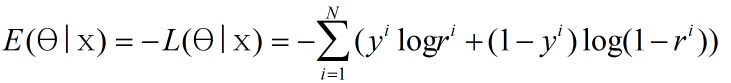
上面的公式样本的互信息定义(Cross Entropy),我们的算法实际上就是求样本集的互信息最小(模型与之样本不确定性最小)
采用随机梯度下降算法即可获得模型参数:
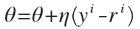
我们得到一个漂亮而又似曾相识的解(与最小二乘回归解的形式),然而这里不同的是hΘ(x)是一个sigmoid函数(非线性的)。
多分类的情况下,logitsitc regression模型每一类均训练出一个预测函数,然后选择后验概率最大的一类。多类logistic regression模型的假设为:
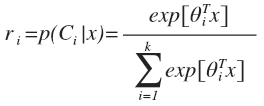
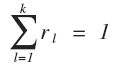
上式被成为软最大(softmax)。每个样本点对应一次多项式取值,即有:
![]()
则样本集的似然函数可以写成:
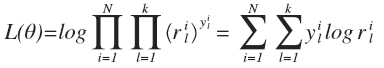
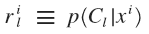
采用随机梯度下降算法,第j类的更新算法如下:
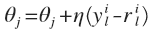
逻辑斯特回归模型的一个强大的地方是,对样本类别的标签给出了自然的置信度(后验概率),其他的判别式线性分类器模型如SVM没有提供,如果想要得到样本后验概率,需要经过特殊的学习算法计算(libsvm支持SVM后验概率形式输出)。