参考:https://blog.csdn.net/u013733326/article/details/79847918
希望大家直接到上面的网址去查看代码,下面是本人的笔记
初始化、正则化、梯度校验
1. 初始化参数:
1.1:使用0来初始化参数。
1.2:使用随机数来初始化参数。
1.3:使用抑梯度异常初始化参数(参见视频中的梯度消失和梯度爆炸)。
2. 正则化模型:
2.1:使用二范数对二分类模型正则化——L2正则化方法,尝试避免过拟合。
2.2:使用随机删除节点的方法——dropout正则化方法精简模型,同样是为了尝试避免过拟合。
3. 梯度校验 :对模型使用梯度校验,检测它是否在梯度下降的过程中出现误差过大的情况。
1.导入相关的库
import numpy as np import matplotlib.pyplot as plt import sklearn import sklearn.datasets import init_utils #第一部分,初始化 import reg_utils #第二部分,正则化 import gc_utils #第三部分,梯度校验 #%matplotlib inline #如果你使用的是Jupyter Notebook,请取消注释。 plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray'
警告:
/Users/user/pytorch/jupyter/2-week1/reg_utils.py:61: SyntaxWarning: assertion is always true, perhaps remove parentheses? assert(parameters['W' + str(l)].shape == layer_dims[l], layer_dims[l-1]) /Users/user/pytorch/jupyter/2-week1/reg_utils.py:62: SyntaxWarning: assertion is always true, perhaps remove parentheses? assert(parameters['W' + str(l)].shape == layer_dims[l], 1)
2.导入数据
train_X, train_Y, test_X, test_Y = init_utils.load_dataset(is_plot=True)
执行返回图示:
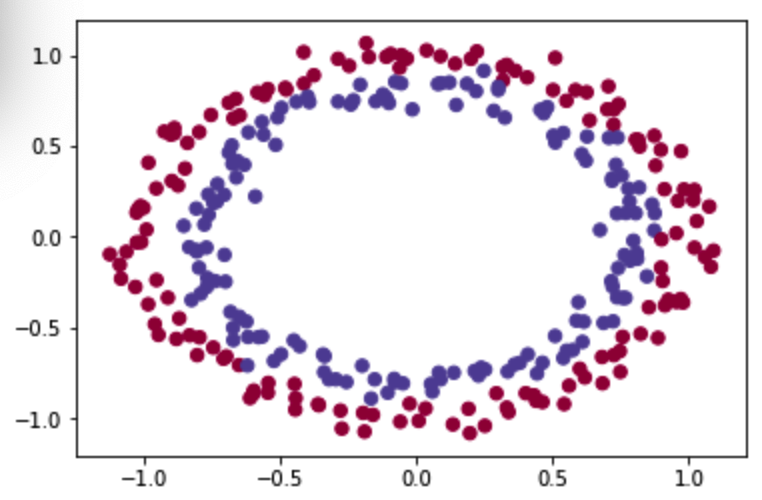
该神经网络目标:建立一个分类器将蓝点和红点分开,建立一个三层网络LINEAR ->RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
3.初始化参数
首先可见神经网络模型为:
def model(X,Y,learning_rate=0.01,num_iterations=15000,print_cost=True,initialization="he",is_polt=True): """ 实现一个三层的神经网络:LINEAR ->RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID 参数: X - 输入的数据,维度为(2, 要训练/测试的数量) Y - 标签,表示输入为红点还是蓝点【0 | 1】,维度为(1,对应的是输入的数据的标签) learning_rate - 学习速率 num_iterations - 迭代的次数 print_cost - 是否打印成本值,每迭代1000次打印一次 initialization - 字符串类型,初始化的类型【"zeros" | "random" | "he"】 is_polt - 是否绘制梯度下降的曲线图 返回 parameters - 学习后的参数 """ grads = {} costs = [] m = X.shape[1] #训练/测试的数量 layers_dims = [X.shape[0],10,5,1] #设置神经网络层数 #选择初始化参数的类型 if initialization == "zeros": parameters = initialize_parameters_zeros(layers_dims) elif initialization == "random": parameters = initialize_parameters_random(layers_dims) elif initialization == "he": parameters = initialize_parameters_he(layers_dims) else : print("错误的初始化参数!程序退出") exit #开始学习 for i in range(0,num_iterations): #前向传播 a3 , cache = init_utils.forward_propagation(X,parameters) #计算成本 cost = init_utils.compute_loss(a3,Y) #反向传播 grads = init_utils.backward_propagation(X,Y,cache) #更新参数 parameters = init_utils.update_parameters(parameters,grads,learning_rate) #记录成本 if i % 1000 == 0: costs.append(cost) #打印成本 if print_cost: print("第" + str(i) + "次迭代,成本值为:" + str(cost)) #学习完毕,绘制成本曲线 if is_polt: plt.plot(costs) plt.ylabel('cost') plt.xlabel('iterations (per hundreds)') plt.title("Learning rate =" + str(learning_rate)) plt.show() #返回学习完毕后的参数 return parameters
1)初始化为0
在输入参数中全部初始化为0,参数名为initialization = “zeros”,核心代码:
parameters['W' + str(l)] = np.zeros((layers_dims[l], layers_dims[l - 1]))
代码为:
def initialize_parameters_zeros(layers_dims): """ 将模型的参数全部设置为0 参数: layers_dims - 列表,模型的层数和对应每一层的节点的数量 返回 parameters - 包含了所有W和b的字典 W1 - 权重矩阵,维度为(layers_dims[1], layers_dims[0]) b1 - 偏置向量,维度为(layers_dims[1],1) ··· WL - 权重矩阵,维度为(layers_dims[L], layers_dims[L -1]) bL - 偏置向量,维度为(layers_dims[L],1) """ parameters = {} L = len(layers_dims) #网络层数 for l in range(1,L): #即每一层的参数w,b都设置为0 parameters["W" + str(l)] = np.zeros((layers_dims[l],layers_dims[l-1])) parameters["b" + str(l)] = np.zeros((layers_dims[l],1)) #使用断言确保我的数据格式是正确的 assert(parameters["W" + str(l)].shape == (layers_dims[l],layers_dims[l-1])) assert(parameters["b" + str(l)].shape == (layers_dims[l],1)) return parameters
测试:
parameters = initialize_parameters_zeros([3,2,1]) #三层神经元数量 print("W1 = " + str(parameters["W1"])) print("b1 = " + str(parameters["b1"])) print("W2 = " + str(parameters["W2"])) print("b2 = " + str(parameters["b2"]))
返回:
W1 = [[0. 0. 0.] [0. 0. 0.]] b1 = [[0.] [0.]] W2 = [[0. 0.]] b2 = [[0.]]
可以看到W和b全部被初始化为0了,那么我们使用这些参数来训练模型,结果会怎样呢?
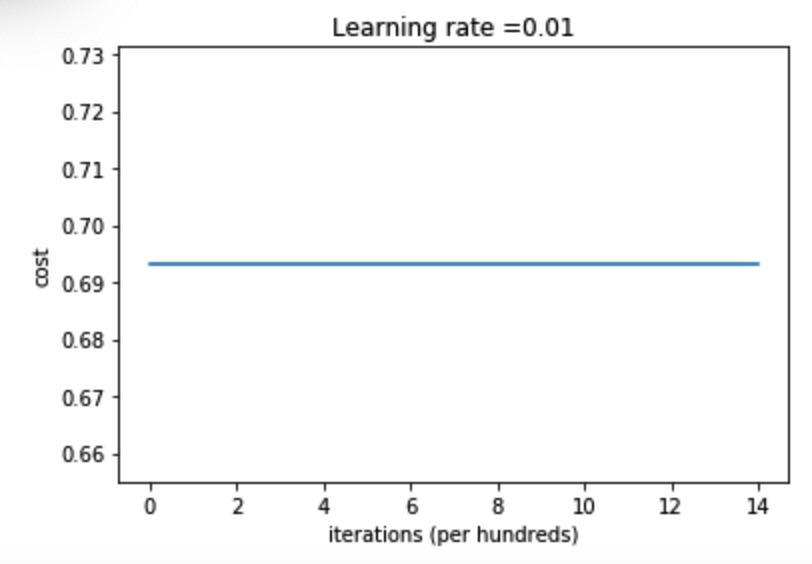
parameters = model(train_X, train_Y, initialization = "zeros",is_polt=True)
返回:
第0次迭代,成本值为:0.6931471805599453 第1000次迭代,成本值为:0.6931471805599453 第2000次迭代,成本值为:0.6931471805599453 第3000次迭代,成本值为:0.6931471805599453 第4000次迭代,成本值为:0.6931471805599453 第5000次迭代,成本值为:0.6931471805599453 第6000次迭代,成本值为:0.6931471805599453 第7000次迭代,成本值为:0.6931471805599453 第8000次迭代,成本值为:0.6931471805599453 第9000次迭代,成本值为:0.6931471805599453 第10000次迭代,成本值为:0.6931471805599455 第11000次迭代,成本值为:0.6931471805599453 第12000次迭代,成本值为:0.6931471805599453 第13000次迭代,成本值为:0.6931471805599453 第14000次迭代,成本值为:0.6931471805599453
可见成本基本没有变化,说明这个模型根本没有学习
图示为:
查看下预测结果:
print ("训练集:") predictions_train = init_utils.predict(train_X, train_Y, parameters) print ("测试集:") predictions_test = init_utils.predict(test_X, test_Y, parameters)
返回:
训练集: Accuracy: 0.5 测试集: Accuracy: 0.5
性能确实很差,而且成本并没有真正降低,算法的性能也比随机猜测要好。为什么?让我们看看预测和决策边界的细节:
这里调用init_utils.plot_decision_boundary()函数的时候还是会遇见问题(运行再jupyter notebook时):
'c' argument has 1 elements, which is not acceptable for use with 'x' with ...
在init_utils.py函数中更改为:
def plot_decision_boundary(model, X, y): # Set min and max values and give it some padding x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1 y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1 h = 0.01 # Generate a grid of points with distance h between them xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # Predict the function value for the whole grid Z = model(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # Plot the contour and training examples plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) plt.ylabel('x2') plt.xlabel('x1') plt.scatter(X[0, :], X[1, :], c=np.squeeze(y), cmap=plt.cm.Spectral) #更改这里的y plt.show()
也没有效果,将该函数直接在jupyter中声明,然后直接调用直接plot_decision_boundary()就不会有问题了
细节检测为:
print("predictions_train = " + str(predictions_train)) print("predictions_test = " + str(predictions_test)) plt.title("Model with Zeros initialization") axes = plt.gca() axes.set_xlim([-1.5, 1.5]) axes.set_ylim([-1.5, 1.5]) plot_decision_boundary(lambda x: init_utils.predict_dec(parameters, x.T), train_X, train_Y)
返回:
predictions_train = [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]] predictions_test = [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
图示:

分类失败,该模型预测每个都为0。通常来说,零初始化都会导致神经网络无法打破对称性,最终导致的结果就是无论网络有多少层,最终只能得到和Logistic函数相同的效果。
2)随机初始化
把输入参数设置为随机值,权重初始化为大的随机值。参数名为initialization = “random”,核心代码:
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10
为了打破对称性,我们可以随机地把参数赋值。在随机初始化之后,每个神经元可以开始学习其输入的不同功能,这里设置比较大的参数值,因为乘于10,看看会发生什么。
代码:
def initialize_parameters_random(layers_dims): """ 参数: layers_dims - 列表,模型的层数和对应每一层的节点的数量 返回 parameters - 包含了所有W和b的字典 W1 - 权重矩阵,维度为(layers_dims[1], layers_dims[0]) b1 - 偏置向量,维度为(layers_dims[1],1) ··· WL - 权重矩阵,维度为(layers_dims[L], layers_dims[L -1]) b1 - 偏置向量,维度为(layers_dims[L],1) """ np.random.seed(3) # 指定随机种子 parameters = {} L = len(layers_dims) # 层数 for l in range(1, L): parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10 #使用10倍缩放 parameters['b' + str(l)] = np.zeros((layers_dims[l], 1)) #b仍初始化为0 #使用断言确保我的数据格式是正确的 assert(parameters["W" + str(l)].shape == (layers_dims[l],layers_dims[l-1])) assert(parameters["b" + str(l)].shape == (layers_dims[l],1)) return parameters
测试:
parameters = initialize_parameters_random([3, 2, 1]) print("W1 = " + str(parameters["W1"])) print("b1 = " + str(parameters["b1"])) print("W2 = " + str(parameters["W2"])) print("b2 = " + str(parameters["b2"]))
返回:
W1 = [[ 17.88628473 4.36509851 0.96497468] [-18.63492703 -2.77388203 -3.54758979]] b1 = [[0.] [0.]] W2 = [[-0.82741481 -6.27000677]] b2 = [[0.]]
看起来这些参数都是比较大的,我们来看看实际运行会怎么样:
parameters = model(train_X, train_Y, initialization = "random",is_polt=True) print("训练集:") predictions_train = init_utils.predict(train_X, train_Y, parameters) print("测试集:") predictions_test = init_utils.predict(test_X, test_Y, parameters) print(predictions_train) print(predictions_test)
警告:
/Users/user/pytorch/jupyter/2-week1/init_utils.py:50: RuntimeWarning: divide by zero encountered in log logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y) /Users/user/pytorch/jupyter/2-week1/init_utils.py:50: RuntimeWarning: invalid value encountered in multiply logprobs = np.multiply(-np.log(a3),Y) + np.multiply(-np.log(1 - a3), 1 - Y)
返回:
第0次迭代,成本值为:inf 第1000次迭代,成本值为:0.6250676215287511 第2000次迭代,成本值为:0.5981418252875961 第3000次迭代,成本值为:0.563858109377261 第4000次迭代,成本值为:0.5501823050061752 第5000次迭代,成本值为:0.5444756668990652 第6000次迭代,成本值为:0.5374638179631746 第7000次迭代,成本值为:0.4770885368883873 第8000次迭代,成本值为:0.397834663330821 第9000次迭代,成本值为:0.3934832163377203 第10000次迭代,成本值为:0.39203323866307854 第11000次迭代,成本值为:0.3892818629893498 第12000次迭代,成本值为:0.3861521882410713 第13000次迭代,成本值为:0.38499297516135134 第14000次迭代,成本值为:0.38280470097181446 训练集: Accuracy: 0.83 测试集: Accuracy: 0.86 [[1 0 1 1 0 0 1 1 1 1 1 0 1 0 0 1 0 1 1 0 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 0 1 0 1 1 1 1 0 0 1 1 1 1 0 1 1 0 1 0 1 1 1 1 0 0 0 0 0 1 0 1 0 1 1 1 0 0 1 1 1 1 1 1 0 0 1 1 1 0 1 1 0 1 0 1 1 0 1 1 0 1 0 1 1 0 0 1 0 0 1 1 0 1 1 1 0 1 0 0 1 0 1 1 1 1 1 1 1 0 1 1 0 0 1 1 0 0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 1 1 0 1 1 0 1 0 1 1 0 1 0 1 1 1 1 0 1 1 1 1 0 1 0 1 0 1 1 1 1 0 1 1 0 1 1 0 1 1 0 1 0 1 1 1 0 1 1 1 0 1 0 1 0 0 1 0 1 1 0 1 1 0 1 1 0 1 1 1 0 1 1 1 1 0 1 0 0 1 1 0 1 1 1 0 0 0 1 1 0 1 1 1 1 0 1 1 0 1 1 1 0 0 1 0 0 0 1 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 0 0 1 1 1 1 1 1 1 0 0 0 1 1 1 1 0]] [[1 1 1 1 0 1 0 1 1 0 1 1 1 0 0 0 0 1 0 1 0 0 1 0 1 0 1 1 1 1 1 0 0 0 0 1 0 1 1 0 0 1 1 1 1 1 0 1 1 1 0 1 0 1 1 0 1 0 1 0 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 0 1 0 0 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 1 0 0]]
图示:
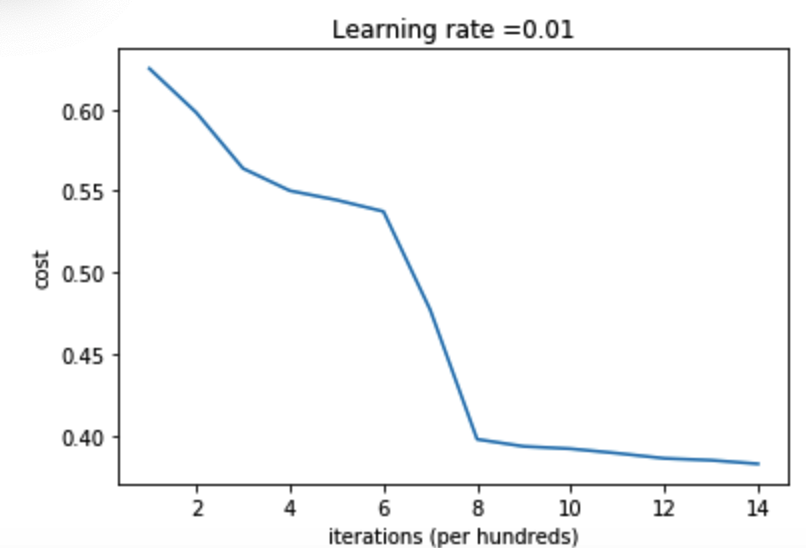
我们来把图绘制出来,看看分类的结果是怎样的。
plt.title("Model with large random initialization") axes = plt.gca() axes.set_xlim([-1.5, 1.5]) axes.set_ylim([-1.5, 1.5]) plot_decision_boundary(lambda x: init_utils.predict_dec(parameters, x.T), train_X, train_Y)
图示:

初始化参数如果没有很好地话会导致梯度消失、爆炸,这也会减慢优化算法。如果我们对这个网络进行更长时间的训练,我们将看到更好的结果,但是使用过大的随机数初始化会减慢优化的速度。
3)抑梯度异常(即梯度爆炸或梯度消失)初始化——最好选择该方法
参见梯度消失和梯度爆炸的那一个视频,参数名为initialization = “he”,核心代码:
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1])
代码:
def initialize_parameters_he(layers_dims): """ 参数: layers_dims - 列表,模型的层数和对应每一层的节点的数量 返回 parameters - 包含了所有W和b的字典 W1 - 权重矩阵,维度为(layers_dims[1], layers_dims[0]) b1 - 偏置向量,维度为(layers_dims[1],1) ··· WL - 权重矩阵,维度为(layers_dims[L], layers_dims[L -1]) b1 - 偏置向量,维度为(layers_dims[L],1) """ np.random.seed(3) # 指定随机种子 parameters = {} L = len(layers_dims) # 层数 for l in range(1, L): parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1]) parameters['b' + str(l)] = np.zeros((layers_dims[l], 1)) #使用断言确保我的数据格式是正确的 assert(parameters["W" + str(l)].shape == (layers_dims[l],layers_dims[l-1])) assert(parameters["b" + str(l)].shape == (layers_dims[l],1)) return parameters
测试:
parameters = initialize_parameters_he([2, 4, 1]) print("W1 = " + str(parameters["W1"])) print("b1 = " + str(parameters["b1"])) print("W2 = " + str(parameters["W2"])) print("b2 = " + str(parameters["b2"]))
返回:
W1 = [[ 1.78862847 0.43650985] [ 0.09649747 -1.8634927 ] [-0.2773882 -0.35475898] [-0.08274148 -0.62700068]] b1 = [[0.] [0.] [0.] [0.]] W2 = [[-0.03098412 -0.33744411 -0.92904268 0.62552248]] b2 = [[0.]]
这样就基本把参数W初始化到了1附近,我们来实际运行一下看看效果:
parameters = model(train_X, train_Y, initialization = "he",is_polt=True) print("训练集:") predictions_train = init_utils.predict(train_X, train_Y, parameters) print("测试集:") init_utils.predictions_test = init_utils.predict(test_X, test_Y, parameters)
返回:
第0次迭代,成本值为:0.8830537463419761 第1000次迭代,成本值为:0.6879825919728063 第2000次迭代,成本值为:0.6751286264523371 第3000次迭代,成本值为:0.6526117768893807 第4000次迭代,成本值为:0.6082958970572938 第5000次迭代,成本值为:0.5304944491717495 第6000次迭代,成本值为:0.4138645817071794 第7000次迭代,成本值为:0.3117803464844441 第8000次迭代,成本值为:0.23696215330322556 第9000次迭代,成本值为:0.18597287209206836 第10000次迭代,成本值为:0.15015556280371817 第11000次迭代,成本值为:0.12325079292273551 第12000次迭代,成本值为:0.09917746546525935 第13000次迭代,成本值为:0.08457055954024278 第14000次迭代,成本值为:0.07357895962677366 训练集: Accuracy: 0.9933333333333333 测试集: Accuracy: 0.96
图示:

可见效果很好,绘制预测情况:
plt.title("Model with He initialization") axes = plt.gca() axes.set_xlim([-1.5, 1.5]) axes.set_ylim([-1.5, 1.5]) plot_decision_boundary(lambda x: init_utils.predict_dec(parameters, x.T), train_X, train_Y)
图示:
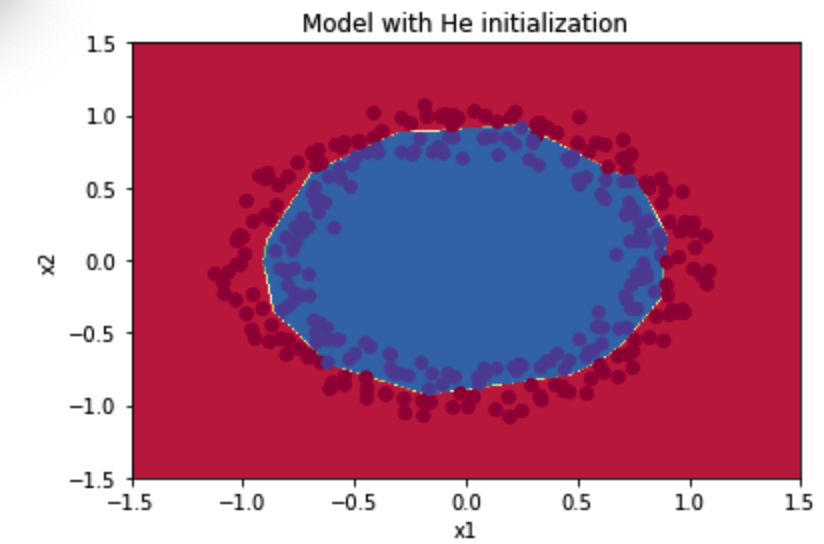
总结:
- 不同的初始化方法可能导致性能最终不同
- 随机初始化有助于打破对称,使得不同隐藏层的单元可以学习到不同的参数。
- 初始化时,初始值不宜过大。
- He初始化搭配ReLU激活函数常常可以得到不错的效果。
在深度学习中,如果数据集没有足够大的话,可能会导致一些过拟合的问题。过拟合导致的结果就是在训练集上有着很高的精确度,但是在遇到新的样本时,精确度下降会很严重。
为了避免过拟合的问题,接下来我们要讲解的方式就是正则化。
接下来可见吴恩达课后作业学习2-week1-2正则化—不发布