https://github.com/youzhonghui/gate-decorator-pruning
1.utils.py
class dotdict(dict): """dot.notation access to dictionary attributes""" __getattr__ = dict.get __setattr__ = dict.__setitem__ __delattr__ = dict.__delitem__
继承dict字典,实际上还是dict
2.loader/__init__.py
import torchvision from torch.utils.data import DataLoader from torchvision import transforms from PIL import Image from config import cfg from loader.cifar10 import get_cifar10 from loader.cifar100 import get_cifar100 from loader.imagenet import get_imagenet def get_loader(): pair = { # 根据设置的参数的数据集名字来选择使用哪个数据集 'cifar10': get_cifar10, 'cifar100': get_cifar100, 'imagenet': get_imagenet } return pair[cfg.data.type]()
选择使用那个数据集,对应的config设置为:
from config import parse_from_dict parse_from_dict({ ... "data": { "type": "cifar10", #这个即使用的数据集名字 "shuffle": True, "batch_size": 128, "test_batch_size": 128, "num_workers": 4 ...
3.models/__init__.py
import torch from config import cfg def get_vgg16_for_cifar(): from models.cifar.vgg import VGG return VGG('VGG16', cfg.model.num_class) def get_resnet50_for_imagenet(): from models.imagenet.resnet50 import Resnet50 return Resnet50(cfg.model.num_class) def get_resnet56(): from models.cifar.resnet56 import resnet56 return resnet56(cfg.model.num_class) def get_model(): pair = {# 根据设置的参数的模型名字来选择使用哪个模型 'cifar.vgg16': get_vgg16_for_cifar, 'resnet50': get_resnet50_for_imagenet, 'cifar.resnet56': get_resnet56 } model = pair[cfg.model.name]() if cfg.base.checkpoint_path != '': #是否有训练好的预训练模型 print('restore checkpoint: ' + cfg.base.checkpoint_path) model.load_state_dict(torch.load(cfg.base.checkpoint_path, map_location='cpu' if not cfg.base.cuda else 'cuda')) if cfg.base.cuda: #单个GPU model = model.cuda() if cfg.base.multi_gpus: #多个GPU model = torch.nn.DataParallel(model) return model
选择使用哪个模型进行分类,并设置是使用cpu还是GPU,有预训练模型就加载预训练模型
对应的config设置为:
from config import parse_from_dict parse_from_dict({ ... "model": { "name": "cifar.resnet56", "num_class": 10, "pretrained": False },
4.loss.py
import torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable import numpy as np from config import cfg def get_criterion(): pair = { #设置使用的损失函数 'softmax': nn.CrossEntropyLoss() } assert (cfg.loss.criterion in pair) criterion = pair[cfg.loss.criterion] return criterion
使用交叉熵损失函数
对应的config设置为:
from config import parse_from_dict parse_from_dict({ ... "loss": { "criterion": "softmax"
5. config.py
import argparse import json from utils import dotdict def make_as_dotdict(obj): #从dict改成dotdict格式 if type(obj) is dict: obj = dotdict(obj) for key in obj: if type(obj[key]) is dict: obj[key] = make_as_dotdict(obj[key]) return obj def parse(): print('Parsing config file...') parser = argparse.ArgumentParser(description="config") parser.add_argument( "--config", type=str, default="configs/base.json", help="Configuration file to use" ) cli_args = parser.parse_args() with open(cli_args.config) as fp: config = make_as_dotdict(json.loads(fp.read())) print(json.dumps(config, indent=4, sort_keys=True)) return config class Singleton(object): _instance = None def __new__(cls, *args, **kw): if not cls._instance: cls._instance = super(Singleton, cls).__new__(cls, *args, **kw) return cls._instance class Config(Singleton): def __init__(self): self._cfg = dotdict({}) try: self._cfg = parse() except: pass def __getattr__(self, name): if name == '_cfg': super().__setattr__(name) else: return self._cfg.__getattr__(name) def __setattr__(self, name, val): if name == '_cfg': super().__setattr__(name, val) else: self._cfg.__setattr__(name, val) def __delattr__(self, name): #del删除元素时调用 return self._cfg.__delitem__(name) def copy(self, new_config): self._cfg = make_as_dotdict(new_config) cfg = Config() def parse_from_dict(d): #将dict换成dotdict global cfg assert type(d) == dict cfg.copy(d)
设置参数
但是不太明白为什么要弄成dotdict格式
这个函数在后面进行prune和finetune的时候会调用来设置参数信息,如:
from config import parse_from_dict parse_from_dict({ "base": { "task_name": "resnet56_cifar10_ticktock", "cuda": True, "seed": 0, "checkpoint_path": "", "epoch": 0, "multi_gpus": True, "fp16": False }, "model": { "name": "cifar.resnet56", "num_class": 10, "pretrained": False }, "train": { "trainer": "normal", "max_epoch": 160, "optim": "sgd", "steplr": [ [80, 0.1], #step>=80时,学习率都设置为0.1 [120, 0.01], [160, 0.001] # 120<step<=160时将学习率设置为0.001 ], "weight_decay": 5e-4, "momentum": 0.9, "nesterov": False }, "data": { "type": "cifar10", "shuffle": True, "batch_size": 128, "test_batch_size": 128, "num_workers": 4 }, "loss": { "criterion": "softmax" }, "gbn": { "sparse_lambda": 1e-3, "flops_eta": 0, "lr_min": 1e-3, "lr_max": 1e-2, "tock_epoch": 10, "T": 10, "p": 0.002 } }) from config import cfg
6.
trainer/__init__.py
from trainer.normal import NormalTrainer
from config import cfg
def get_trainer():
pair = {
'normal': NormalTrainer
}
assert (cfg.train.trainer in pair)
return pair[cfg.train.trainer]()
设置使用的训练train()、测试test()函数所在位置
扩展:
#coding:utf-8 import torch if __name__ == '__main__': a = torch.FloatTensor([[3, 14, 15, 13], [5,4,15,7]]).t() b = torch.FloatTensor([[3, 3, 3, 3], [5,5,5,5]]).t() correct = a.eq(b) print(correct) print(correct[:1]) print(correct[:1].view(-1)) print(correct[:1].view(-1).float()) correct_k = correct[:1].view(-1).float().sum(0, keepdim=True) print(correct_k)
返回:
tensor([[ True, True], [False, False], [False, False], [False, False]]) tensor([[True, True]]) tensor([True, True]) tensor([1., 1.]) tensor([2.])
trainer/normal.py:
from time import time import torch import torch.nn as nn from torch.autograd import Variable import torch.nn.functional as F from tqdm import tqdm import numpy as np from config import cfg FINISH_SIGNAL = 'finish' def accuracy(output, target, topk=(1,)): #计算分类的准确度 """Computes the accuracy over the k top predictions for the specified values of k""" with torch.no_grad(): maxk = max(topk) #看是top-1还是top-5 batch_size = target.size(0) _, pred = output.topk(maxk, 1, True, True) # 从输出中得到前maxk个大的预测结果的索引值,大小为(batch_size, maxk) pred = pred.t() # 转置成(maxk, batch_size) # target从(batch_size, 1) -> (1, batch_size) -> (maxk, batch_size) # 然后与pred对比看是否相等,每个batch_size最多只有一个相等,所以correct中true的个数最大值为batch_size # correct为(maxk, batch_size),值为 correct = pred.eq(target.view(1, -1).expand_as(pred)) res = [] for k in topk: correct_k = correct[:k].view(-1).float().sum(0, keepdim=True) res.append(correct_k.mul_(100.0 / batch_size)) # 得到百分比的正确率 return res class NormalTrainer(): def __init__(self): self.use_cuda = cfg.base.cuda def test(self, pack, topk=(1,)): # 测试 pack.net.eval() loss_acc, correct, total = 0.0, 0.0, 0.0 hub = [[] for i in range(len(topk))] for data, target in pack.test_loader: if self.use_cuda: data, target = data.cuda(), target.cuda() with torch.no_grad(): #不后向传播 output = pack.net(data) loss_acc += pack.criterion(output, target).data.item() #计算损失 acc = accuracy(output, target, topk) # 准确率 for acc_idx, score in enumerate(acc): hub[acc_idx].append(score[0].item()) loss_acc /= len(pack.test_loader) # 最后得到的平均损失 info = { 'test_loss': loss_acc } for acc_idx, k in enumerate(topk): info['acc@%d' % k] = np.mean(hub[acc_idx]) #top-1,top-5等准确率 return info def train(self, pack, loss_hook=None, iter_hook=None, update=True, mute=False, acc_step=1): #训练,mute即是否打印info pack.net.train() loss_acc, correct_acc, total = 0.0, 0.0, 0.0 begin = time() pack.optimizer.zero_grad() with tqdm(total=len(pack.train_loader), disable=mute) as pbar: total_iter = len(pack.train_loader) #总迭代次数 for cur_iter, (data, label) in enumerate(pack.train_loader): if iter_hook is not None: signal = iter_hook(cur_iter, total_iter) if signal == FINISH_SIGNAL: #结束标志 break if self.use_cuda: data, label = data.cuda(), label.cuda() data = Variable(data, requires_grad=False) label = Variable(label) logits = pack.net(data) loss = pack.criterion(logits, label) if loss_hook is not None: additional = loss_hook(data, label, logits) loss += additional loss = loss / acc_step loss.backward() if (cur_iter + 1) % acc_step == 0: if update: pack.optimizer.step() pack.optimizer.zero_grad() loss_acc += loss.item() pbar.update(1) info = { 'train_loss': loss_acc / len(pack.train_loader), 'epoch_time': time() - begin } return info
一个train()即跑完一次所有数据就结束了,即enumerate(pack.train_loader)完就完了
7.main.py
""" * Copyright (C) 2019 Zhonghui You * If you are using this code in your research, please cite the paper: * Gate Decorator: Global Filter Pruning Method for Accelerating Deep Convolutional Neural Networks, in NeurIPS 2019. """ import torch import torch.nn as nn import torch.optim as optim import numpy as np import random import math from loader import get_loader from models import get_model from trainer import get_trainer from loss import get_criterion from utils import dotdict from config import cfg from logger import logger def _sgdr(epoch): lr_min, lr_max = cfg.train.sgdr.lr_min, cfg.train.sgdr.lr_max restart_period = cfg.train.sgdr.restart_period _epoch = epoch - cfg.train.sgdr.warm_up while _epoch/restart_period > 1.: _epoch = _epoch - restart_period restart_period = restart_period * 2. radians = math.pi*(_epoch/restart_period) return lr_min + (lr_max - lr_min) * 0.5*(1.0 + math.cos(radians)) def _step_lr(epoch): v = 0.0 for max_e, lr_v in cfg.train.steplr: #max_e是到这个step的学习率都是lr_v v = lr_v if epoch <= max_e: break return v def get_lr_func(): if cfg.train.steplr is not None: return _step_lr elif cfg.train.sgdr is not None: return _sgdr else: assert False def adjust_learning_rate(epoch, pack): #设置使用的优化器,并设置学习率调节函数,以及更新学习率 if pack.optimizer is None: if cfg.train.optim == 'sgd' or cfg.train.optim is None: pack.optimizer = optim.SGD( pack.net.parameters(), lr=1, momentum=cfg.train.momentum, weight_decay=cfg.train.weight_decay, nesterov=cfg.train.nesterov ) else: print('WRONG OPTIM SETTING!') assert False pack.lr_scheduler = optim.lr_scheduler.LambdaLR(pack.optimizer, get_lr_func()) pack.lr_scheduler.step(epoch) return pack.lr_scheduler.get_lr() def recover_pack(): train_loader, test_loader = get_loader() pack = dotdict({ 'net': get_model(), 'train_loader': train_loader, 'test_loader': test_loader, 'trainer': get_trainer(), 'criterion': get_criterion(), 'optimizer': None, 'lr_scheduler': None }) adjust_learning_rate(cfg.base.epoch, pack) return pack def set_seeds(): #用来保证代码中随机数每次都一样 torch.manual_seed(cfg.base.seed) if cfg.base.cuda: torch.cuda.manual_seed_all(cfg.base.seed) torch.backends.cudnn.deterministic = True if cfg.base.fp16: torch.backends.cudnn.enabled = True # torch.backends.cudnn.benchmark = True np.random.seed(cfg.base.seed) random.seed(cfg.base.seed) def main(): set_seeds() #设置中设置的"seed": 0,就是用在这的 pack = recover_pack() #设置各个参数和使用的模型、数据等 for epoch in range(cfg.base.epoch + 1, cfg.train.max_epoch + 1): lr = adjust_learning_rate(epoch, pack) # 更新lr info = pack.trainer.train(pack) #训练模型,得到损失和准确率等信息 info.update(pack.trainer.test(pack)) #加入测试时的损失和准确率等信息 info.update({'LR': lr}) #记录此时的lr print(epoch, info) logger.save_record(epoch, info) #写入日志 if epoch % cfg.base.model_saving_interval == 0: logger.save_network(epoch, pack.net) # 保存网络 if __name__ == '__main__': main()
8.logger.py
import torch from config import cfg import os import json import numpy as np class MetricsRecorder(): def __init__(self): self.rec = {} def add(self, pairs): for key, val in pairs.items(): if key not in self.rec: self.rec[key] = [] self.rec[key].append(val) def mean(self): r = {} for key, val in self.rec.items(): r[key] = np.mean(val) return r class Logger(): def __init__(self): self.base_path = './logs/' + cfg.base.task_name self.logfile = self.base_path + '/log.json' self.cfgfile = self.base_path + '/cfg.json' if not os.path.isdir(self.base_path): os.makedirs(self.base_path, exist_ok=True) with open(self.logfile, 'w') as fp: json.dump({}, fp) #初始化时日志信息为空 with open(self.cfgfile, 'w') as fp: json.dump(cfg, fp) #初始化时配置信息即config信息 def save_record(self, epoch, record): #保存运行过程中训练和测试的损失和准确率等信息,以当前的epoch为索引 with open(self.logfile) as fp: log = json.load(fp) log[str(epoch)] = record with open(self.logfile, 'w') as fp: json.dump(log, fp) def save_network(self, epoch, network): saving_path = self.base_path + '/ckp.%d.torch' % epoch print('saving model ...') if type(network) is torch.nn.DataParallel: torch.save(network.module.state_dict(), saving_path) else: torch.save(network.state_dict(), saving_path) cfg.base.epoch = epoch cfg.base.checkpoint_path = saving_path with open(self.cfgfile, 'w') as fp: # 保存新的配置信息 json.dump(cfg, fp) logger = None if logger is None: logger = Logger()
相应的文件将会根据任务名字,即设置:
from config import parse_from_dict parse_from_dict({ "base": { "task_name": "resnet18", #任务名字
在./logs文件夹下创建同名文件夹存储log.json和cfg.json文件,save_record()就是将中间信息保存在这,调用save_network()也会将模型保存在该文件夹中
user@jiayuan:/opt/.../gate-decorator-pruning/logs/resnet18$ ls
cfg.json log.json
接下来就是prune和finetune了,重要
9.prune/utils.py
#coding:utf-8 import os if __name__ == '__main__': print(os.devnull) #/dev/null
代码:
import torch import torch.nn as nn import os, contextlib from thop import profile def analyse_model(net, inputs): # silence with open(os.devnull, 'w') as devnull: #os.devnull对于Linux为/dev/null with contextlib.redirect_stdout(devnull):#标准输出已经重定向到了 /dev/null flops, params = profile(net, (inputs, )) #估算PyTorch模型的FLOPs模块 return flops, params def finetune(pack, lr_min, lr_max, T, mute=False): #T即finetune_epoch,即40轮迭代 logs = [] epoch = 0 def iter_hook(curr_iter, total_iter): #作为train的iter_hook参数传入 total = T * total_iter #total_iter即dataloader中有多少批batch_size,所以整个finetune跑total个batch_size half = total / 2 itered = epoch * total_iter + curr_iter #curr_iter即一个epoch中,数据跑到了第curr_iter个batch_size,现在的总batch_size数为itered if itered < half: #当小于一半时,学习率这么算 _iter = epoch * total_iter + curr_iter _lr = (1- _iter / half) * lr_min + (_iter / half) * lr_max else: # 当大于或等于一半时,学习率这么算,这两个的差别就是lr_max和lr_min的前后位置不同,大概意思是相同的 _iter = (epoch - T/2) * total_iter + curr_iter _lr = (1- _iter / half) * lr_max + (_iter / half) * lr_min for g in pack.optimizer.param_groups: g['lr'] = max(_lr, 0) g['momentum'] = 0.0 for i in range(T): #训练40个epoch info = pack.trainer.train(pack, iter_hook = iter_hook) info.update(pack.trainer.test(pack)) info.update({'LR': pack.optimizer.param_groups[0]['lr']}) epoch += 1 if not mute: #是否打印损失和精确度等信息 print(info) logs.append(info) return logs
这里的微调操作其实就是论文中的:
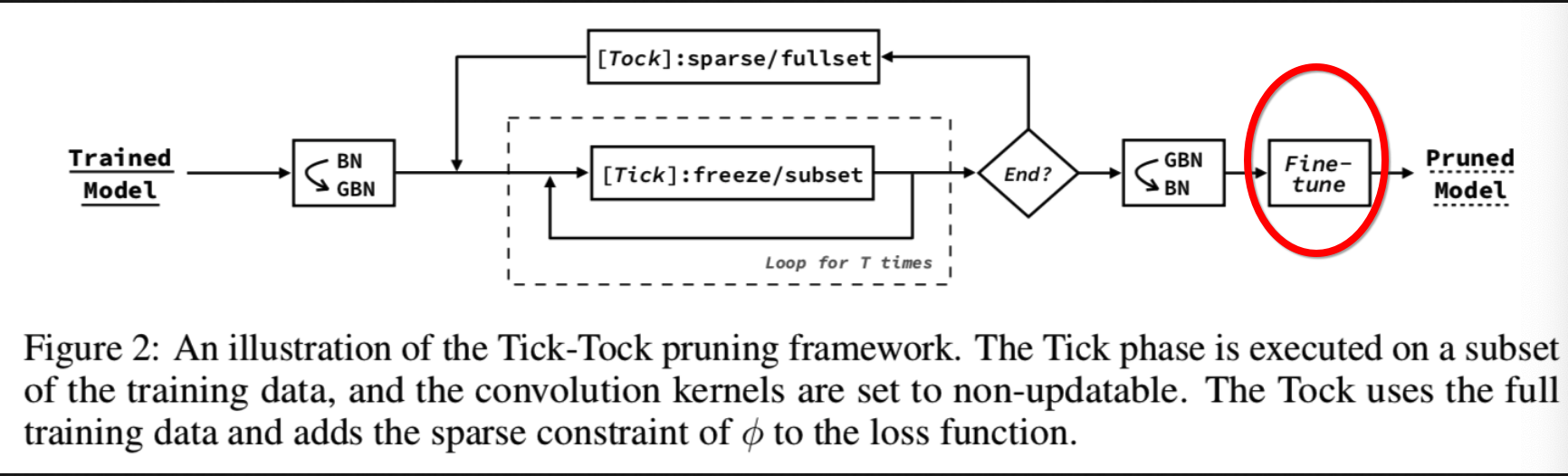
它跟tick-tock中的tock的差别在于tock中使用的还是GBN,且训练次数比较少,一半就10次;而finetune操作是在整个模型都prune后的小模型中训练,GBN都换回BN,且训练次数也比较多
10.prune/universal.py
扩展
1)uuid库:
UUID: 通用唯一标识符 ( Universally Unique Identifier ), 对于所有的UUID它可以保证在空间和时间上的唯一性. 它是通过MAC地址, 时间戳, 命名空间, 随机数, 伪随机数来保证生成ID的唯一性, 有着固定的大小( 128 bit ). 它的唯一性和一致性特点使得可以无需注册过程就能够产生一个新的UUID. UUID可以被用作多种用途, 既可以用来短时间内标记一个对象, 也可以可靠的辨别网络中的持久性对象.
为什么要使用UUID?
很多应用场景需要一个id, 但是又不要求这个id 有具体的意义, 仅仅用来标识一个对象. 常见的例子有数据库表的id 字段. 另一个例子是前端的各种UI库, 因为它们通常需要动态创建各种UI元素, 这些元素需要唯一的id , 这时候就需要使用UUID了.
#coding:utf-8 import uuid if __name__ == '__main__': print(uuid.uuid1()) #7b24099a-27ae-11ea-b076-00e04c6841ff
其实这个库主要是用于像resnet这样的网络中有侧枝shortcut的情况,是分组使用的,即同一个Group的ID是相同的。像VGG这样的网络每个GBN层的ID是不同的
2)nn.Parameter
#coding:utf-8 import torch.nn as nn import torch if __name__ == '__main__': g = nn.Parameter(torch.ones(1, 3, 1, 1), requires_grad=True) print(g)
返回:
Parameter containing: tensor([[[[1.]], [[1.]], [[1.]]]], requires_grad=True)
使用nn.Parameter的目的是将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个值就变成了模型的一部分,成为了模型中根据训练可以改动的参数了
模型中的bias和weight都是nn.Parameter,可用于训练,并实现优化;Variable则是作为模型的输入
buffers()返回一个模块缓冲区的迭代器,其保存的是模型中每次前向传播需用到上一次前向传播的结果,作为持久状态的值,如BatchNorm2d()中使用的均值和方差值,其随着BatchNorm2d()中参数的变化而变化
3)

所以GatedBatchNorm2d代码中初始化中有设置参数:
def extract_from_bn(self):
# freeze bn weight
with torch.no_grad():
self.bn.bias.set_(torch.clamp(self.bn.bias / self.bn.weight, -10, 10)) #将self.bn.bias / self.bn.weight的值保持在[-10, 10],小于-10的即改为-10,大于10的即改为10
self.g.set_(self.g * self.bn.weight.view(1, -1, 1, 1))
self.bn.weight.set_(torch.ones_like(self.bn.weight)) #torch.ones_like(input)相当于torch.ones(input.size())
self.bn.weight.requires_grad = False
Φ就是g,β就是bn.bias,γ就是self.bn.weight
prune后,得到应该截取掉的filter,变回来的代码:
def melt(self): with torch.no_grad(): mask = self.bn_mask.view(-1) #转成列表, mask中有channels个值,值为0说明该channel被prune了 replacer = nn.BatchNorm2d(int(self.bn_mask.sum())).to(self.bn.weight.device) replacer.running_var.set_(self.bn.running_var[mask != 0]) #BatchNorm2d中的方差 replacer.running_mean.set_(self.bn.running_mean[mask != 0]) #BatchNorm2d中的均值 replacer.weight.set_((self.bn.weight * self.g.view(-1))[mask != 0]) replacer.bias.set_((self.bn.bias * self.g.view(-1))[mask != 0]) return replacer
整个代码:
import torch import torch.nn as nn import numpy as np import uuid OBSERVE_TIMES = 5 FINISH_SIGNAL = 'finish' class Meltable(nn.Module): def __init__(self): super(Meltable, self).__init__() @classmethod def melt_all(cls, net): def _melt(modules): keys = modules.keys() for k in keys: if len(modules[k]._modules) > 0: _melt(modules[k]._modules) if isinstance(modules[k], Meltable): modules[k] = modules[k].melt() _melt(net._modules) @classmethod def observe(cls, pack, lr): tmp = pack.train_loader if pack.tick_trainset is not None: pack.train_loader = pack.tick_trainset #数据集 for m in pack.net.modules(): if isinstance(m, nn.BatchNorm2d): m.weight.data.abs_().add_(1e-3) def replace_relu(modules): #将relu函数换成LeakyReLU函数 keys = modules.keys() for k in keys: if len(modules[k]._modules) > 0: replace_relu(modules[k]._modules) if isinstance(modules[k], nn.ReLU): modules[k] = nn.LeakyReLU(inplace=True) replace_relu(pack.net._modules) count = 0 def _freeze_bn(curr_iter, total_iter): for m in pack.net.modules(): if isinstance(m, nn.BatchNorm2d): m.eval() nonlocal count count += 1 if count == OBSERVE_TIMES: return FINISH_SIGNAL info = pack.trainer.train(pack, iter_hook=_freeze_bn, update=False, mute=True) #优化器不优化了 def recover_relu(modules): #将LeakyReLU函数换成relu函数 keys = modules.keys() for k in keys: if len(modules[k]._modules) > 0: recover_relu(modules[k]._modules) if isinstance(modules[k], nn.LeakyReLU): modules[k] = nn.ReLU(inplace=True) recover_relu(pack.net._modules) for m in pack.net.modules(): if isinstance(m, nn.BatchNorm2d): m.weight.data.abs_().add_(-1e-3) # 变回来 pack.train_loader = tmp class GatedBatchNorm2d(Meltable): def __init__(self, bn, minimal_ratio = 0.1): super(GatedBatchNorm2d, self).__init__() assert isinstance(bn, nn.BatchNorm2d) self.bn = bn self.group_id = uuid.uuid1() self.channel_size = bn.weight.shape[0] self.minimal_filter = max(1, int(self.channel_size * minimal_ratio)) #最小的通道数 self.device = bn.weight.device self._hook = None self.g = nn.Parameter(torch.ones(1, self.channel_size, 1, 1).to(self.device), requires_grad=True)#一个可以用于训练的参数 # 这样后就会生成三个参数self.areaself.scoreself.bn_mask self.register_buffer('area', torch.zeros(1).to(self.device)) #即nn.Module.register_buffer,保存一些前向传播会用到的上一次前向传播的结果 self.register_buffer('score', torch.zeros(1, self.channel_size, 1, 1).to(self.device)) self.register_buffer('bn_mask', torch.ones(1, self.channel_size, 1, 1).to(self.device)) #bn_mask就是用来记录该bn的channels层是否被prune了,为0则被prune了,初始化为1 self.extract_from_bn() #将本身的bn的weight、bias和g三个参数重新设置一下 def set_groupid(self, new_id): self.group_id = new_id def extra_repr(self): #即prune后channel数从channel_size变为了bn_mask.sum() return '%d -> %d | ID: %s' % (self.channel_size, int(self.bn_mask.sum()), self.group_id) def extract_from_bn(self): # freeze bn weight with torch.no_grad(): self.bn.bias.set_(torch.clamp(self.bn.bias / self.bn.weight, -10, 10)) #将self.bn.bias / self.bn.weight的值保持在[-10, 10],小于-10的即改为-10,大于10的即改为10 self.g.set_(self.g * self.bn.weight.view(1, -1, 1, 1)) self.bn.weight.set_(torch.ones_like(self.bn.weight)) #torch.ones_like(input)相当于torch.ones(input.size()) self.bn.weight.requires_grad = False def reset_score(self): self.score.zero_() def cal_score(self, grad): # used for hook self.score += (grad * self.g).abs() #论文中公式6的计算,计算分数,即变成prune后的网络和以前网络的损失差计算,得到此时设置的每个参数g的分数,分数越小直至0说明该g的channels能删除 def start_collecting_scores(self): if self._hook is not None: self._hook.remove() self._hook = self.g.register_hook(self.cal_score) #后向传播计算出关于这个参数g的gradient后将会调用cal_score计算此时的self.score分数值,排序使用 def stop_collecting_scores(self): if self._hook is not None: self._hook.remove() # 移除register_hook得到的hook self._hook = None def get_score(self, eta=0.0): # use self.bn_mask.sum() to calculate the number of input channel. eta should had been normed # 因为self.bn_mask中的值都是1,大小为torch.ones(1, self.channel_size, 1, 1),所以sum()后的结果为self.channel_size flops_reg = eta * int(self.area[0]) * self.bn_mask.sum() return ((self.score - flops_reg) * self.bn_mask).view(-1) def forward(self, x): x = self.bn(x) * self.g # self.g就是用来排重要性的参数 self.area[0] = x.shape[-1] * x.shape[-2] #长*宽=面积area if self.bn_mask is not None: return x * self.bn_mask return x def melt(self): with torch.no_grad(): mask = self.bn_mask.view(-1) #得到当前prune后的channels数 replacer = nn.BatchNorm2d(int(self.bn_mask.sum())).to(self.bn.weight.device) replacer.running_var.set_(self.bn.running_var[mask != 0]) #BatchNorm2d中的方差 replacer.running_mean.set_(self.bn.running_mean[mask != 0]) #BatchNorm2d中的均值 replacer.weight.set_((self.bn.weight * self.g.view(-1))[mask != 0]) replacer.bias.set_((self.bn.bias * self.g.view(-1))[mask != 0]) return replacer @classmethod def transform(cls, net, minimal_ratio=0.1): r = [] def _inject(modules): keys = modules.keys() for k in keys: if len(modules[k]._modules) > 0: _inject(modules[k]._modules) if isinstance(modules[k], nn.BatchNorm2d): # 将模型中的nn.BatchNorm2d换成GatedBatchNorm2d,截取后的filter数量>= max(1, int(self.channel_size * minimal_ratio)) modules[k] = GatedBatchNorm2d(modules[k], minimal_ratio) r.append(modules[k]) _inject(net._modules) return r
4)

卷积层的prune:
class Conv2dObserver(Meltable): def __init__(self, conv): super(Conv2dObserver, self).__init__() assert isinstance(conv, nn.Conv2d) self.conv = conv self.in_mask = torch.zeros(conv.in_channels).to('cpu') self.out_mask = torch.zeros(conv.out_channels).to('cpu') self.f_hook = conv.register_forward_hook(self._forward_hook) #该层卷机前向传播是进行的操作 def extra_repr(self): return '(%d, %d) -> (%d, %d)' % (self.conv.in_channels, self.conv.out_channels, int((self.in_mask != 0).sum()), int((self.out_mask != 0).sum())) def _forward_hook(self, m, _in, _out): x = _in[0] #self.in_mask就是用来记录该channels层是否被prune了,为0则被prune了 self.in_mask += x.data.abs().sum(2, keepdim=True).sum(3, keepdim=True).cpu().sum(0, keepdim=True).view(-1) # 留下channels层,总和为0说明该channels被prune了 def _backward_hook(self, grad): #后向传播计算出gradient后执行的操作 self.out_mask += grad.data.abs().sum(2, keepdim=True).sum(3, keepdim=True).cpu().sum(0, keepdim=True).view(-1) # 留下channels层,总和为0说明该channels被prune了 new_grad = torch.ones_like(grad) return new_grad def forward(self, x): output = self.conv(x) noise = torch.zeros_like(output).normal_() output = output + noise #? if self.training: output.register_hook(self._backward_hook) return output def melt(self): if self.conv.groups == 1: groups = 1 elif self.conv.groups == self.conv.out_channels: groups = int((self.out_mask != 0).sum()) else: assert False replacer = nn.Conv2d( in_channels = int((self.in_mask != 0).sum()), out_channels = int((self.out_mask != 0).sum()), kernel_size = self.conv.kernel_size, stride = self.conv.stride, padding = self.conv.padding, dilation = self.conv.dilation, groups = groups, bias = (self.conv.bias is not None) ).to(self.conv.weight.device) with torch.no_grad(): if self.conv.groups == 1: replacer.weight.set_(self.conv.weight[self.out_mask != 0][:, self.in_mask != 0]) else: replacer.weight.set_(self.conv.weight[self.out_mask != 0]) if self.conv.bias is not None: replacer.bias.set_(self.conv.bias[self.out_mask != 0]) return replacer @classmethod def transform(cls, net): r = [] def _inject(modules): keys = modules.keys() for k in keys: if len(modules[k]._modules) > 0: _inject(modules[k]._modules) if isinstance(modules[k], nn.Conv2d): modules[k] = Conv2dObserver(modules[k]) r.append(modules[k]) _inject(net._modules) return r
5)分类最后一层的全连接层怎么变:
class FinalLinearObserver(Meltable): ''' assert was in the last layer. only input was masked ''' def __init__(self, linear): super(FinalLinearObserver, self).__init__() assert isinstance(linear, nn.Linear) self.linear = linear self.in_mask = torch.zeros(linear.weight.shape[1]).to('cpu') self.f_hook = linear.register_forward_hook(self._forward_hook) #该linear层前向传播是进行的函数操作 def extra_repr(self): return '(%d, %d) -> (%d, %d)' % ( int(self.linear.weight.shape[1]), int(self.linear.weight.shape[0]), int((self.in_mask != 0).sum()), int(self.linear.weight.shape[0])) def _forward_hook(self, m, _in, _out): x = _in[0] self.in_mask += x.data.abs().cpu().sum(0, keepdim=True).view(-1) #列相加,每一列求和,输入的data中为0的列是因为那个channels被prune了, def forward(self, x): return self.linear(x) def melt(self): # 换成prune后的channels数 with torch.no_grad(): replacer = nn.Linear(int((self.in_mask != 0).sum()), self.linear.weight.shape[0]).to(self.linear.weight.device) replacer.weight.set_(self.linear.weight[:, self.in_mask != 0]) replacer.bias.set_(self.linear.bias) return replacer
这两个函数的作用在于将卷积层和全连接层分别封装成Conv2dObserver和FinalLinearObserver
如Conv2dObserver中就会有in_mask和out_mask两个参数,就是分别在训练的前向传播和后向传播中计算channels轴的和,最后为0则说明该轴已经被prune了,即:
def _forward_hook(self, m, _in, _out): x = _in[0] #self.in_mask就是用来记录该channels层是否被prune了,为0则被prune了 self.in_mask += x.data.abs().sum(2, keepdim=True).sum(3, keepdim=True).cpu().sum(0, keepdim=True).view(-1) # 留下channels层,总和为0说明该channels被prune了 def _backward_hook(self, grad): #后向传播计算出gradient后执行的操作 self.out_mask += grad.data.abs().sum(2, keepdim=True).sum(3, keepdim=True).cpu().sum(0, keepdim=True).view(-1) # 留下channels层,总和为0说明该channels被prune了 new_grad = torch.ones_like(grad) return new_grad
主要是用在下图标红部分:

即GBN变成剪枝后的BN的同时,卷积层和全连接层根据相邻的GBN层计算得到的in_mask和out_mask两个参数去剪枝对应的filter,令整个网络channels数是能链接起来的
6)gate的loss函数:
def get_gate_sparse_loss(masks, sparse_lambda): def _loss_hook(data, label, logits): loss = 0.0 for gbn in masks: if isinstance(gbn, GatedBatchNorm2d): loss += gbn.g.abs().sum() return sparse_lambda * loss return _loss_hook
这个是计算tock的损失的后半部分,后面看代码它是作为loss_hook的,的确是额外的loss
对应论文中的:
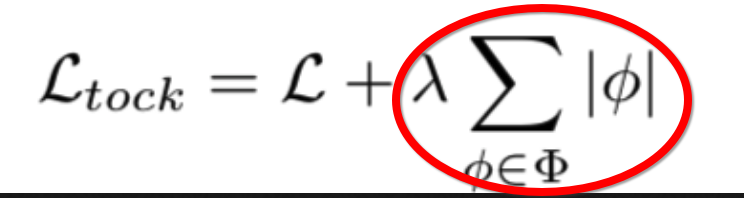
查看resnet56_prune中使用的resnet56的网络结构:
for name, module in pack.net.named_modules(): print(name) print(module)
返回:
DataParallel( (module): ResNet( (conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) (1): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) (2): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) (3): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) (4): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) (5): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) (6): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) (7): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) (8): BasicBlock( (conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential() ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (shortcut): Sequential( (0): Conv2d(16, 32, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) ...
7)
剩下的Tick-Tock部分可能结合例子来讲比较好讲Gate Decorator: Global Filter Pruning Method for Accelerating Deep Convolutional Neural Networks - 模型压缩 - 3 - 代码学习,VGG16,Resnet