使用的网络结构VarGNet可见VarGNet: Variable Group Convolutional Neural Network for Efficient Embedded Computing - 1 -论文学习
2019
VarGFaceNet: An Efficient Variable Group Convolutional Neural Network for Lightweight Face Recognition
Abstract
为了提高轻量级人脸识别网络的识别能力和泛化能力,我们提出了一种高效的可变分组卷积网络VarGFaceNet。VarGNet引入了可变分组卷积,解决了计算量小与块内计算强度不平衡的矛盾。我们使用可变分组卷积来设计我们的网络,它可以支持大规模的人脸识别,同时降低了计算成本和参数。具体来说,我们在网络开始时使用head设置来保留必要的信息,并提出了一种特殊的嵌入设置来减少全连接层的嵌入参数。为了提高解释能力,我们使用角蒸馏损失的等价性来指导我们的轻量级网络,并使用递归知识蒸馏来消除教师模型和学生模型之间的差异。在LFR(2019)挑战赛deepglintlight track的冠军结果证明了我们的模型和方法的有效性。VarGFaceNet的实现将很快在https://github.com/z-137/vargfacenet发布。
1. Introduction
虽然MobileNet[12] 、MobileNetV2[21]、ShuffleNet[27]和ShuffleNetV2[18]等网络在推理过程中计算量小,在各种应用中性能良好,但嵌入式系统的优化问题仍然存在于嵌入式硬件和相应的编译器中[26]。为了解决这一矛盾,VarGNet[26]提出了一种可变分组卷积算法,有效地解决了块内计算强度的不平衡问题。同时,我们还发现在相同的kernel大小下,可变分组卷积比深度卷积具有更大的容量,这有助于网络提取更多的本质信息。但是,VarGNet主要用于图像分类和目标检测等一般任务。为了节省内存和计算开销,在头部设置中将空间面积减少了一半,但是这种设置不适合人脸识别任务,因为需要人脸的详细信息。在嵌入的最后一个卷积层和全连接层之间只有一个平均池化层,可能无法提取足够的判别信息。
基于VarGNet,我们提出了一种高效的轻量级人脸识别可变分组卷积网络,简称VarGFaceNet。为了提高VarGNet对大规模人脸识别任务的识别能力,我们首先在VarGNet的块上添加SE块[13]和PReLU块[8]。然后在网络初始阶段删除下采样过程,以保留更多的信息。为了降低网络参数,我们在fc层之前使用可变分组卷积将特征张量缩小到1×1×512。VarGFaceNet的性能表明,该嵌入设置可以在降低网络参数的同时保持网络的鉴别能力。
为了提高轻量级网络的解释能力,我们在训练中采用了知识蒸馏的方法。有几种方法旨在使深层网络更小和更经济有效,如模型剪枝、模型量化和知识提取。其中,知识蒸馏正因其架构的灵活性而受到积极的研究。Hinton[11]引入了知识蒸馏的概念,提出利用教师网络的softmax输出来实现知识蒸馏。为了更好地利用教师网络的信息,FitNets[20]采用特征蒸馏的思想,鼓励学生网络模仿教师网络的隐含特征值。经过FitNets之后,尝试利用教师网络知识的方法有很多种,如传递feature activation map[10], active-based and gradient-based Attention Maps[25]。最近,ShrinkTeaNet[6]引入了一种角度蒸馏损失来专注于教师模型的角度信息。受角度蒸馏损失的启发,我们采用具有更好实现效率的等效损失作为VarGFaceNet的指导。此外,为了解决由于教师模型和学生模型之间的差异而导致的优化问题的复杂性,我们引入了递归知识蒸馏,将第一代训练的学生模型作为下一代的预训练模型。
我们在LFR挑战[4]中评估了我们的模型和方法。LFR挑战是一种轻量级的人脸识别挑战,它需要的网络FLOPs小于1G,内存占用小于20M。VarGFaceNet在这一挑战中实现了最先进的性能,如第3节所示。我们的贡献总结如下:
- 为了提高VarGNet[26]在大规模人脸识别中的识别能力,我们采用了不同的head设置,并提出了一种新的嵌入块。在嵌入块中,我们首先通过1×1卷积层将通道扩展到1024来保留必要的信息,然后使用可变分组卷积和pointwise卷积将空间面积缩小到1×1,同时节省了计算成本。这些设置提高了人脸识别任务的性能,将在第3节中说明。
- 为了提高轻量级模型的泛化能力,我们提出了递归知识蒸馏的方法,从而在一代的时间内消除了教师模型和学生模型之间的泛化差距。
- 我们分析了可变分组卷积的效率,并在训练中应用了角度蒸馏损失的等价性。实验证明了该方法的有效性。
2. Approach
2.1. Variable Group Convolution
分组卷积是在AlexNet[16]中首次引入的,用于在gpu上降低计算成本。然后,在ResNext[23]中,分组卷积的基数性表现出比深度和宽度维度更好的性能。针对移动设备,MobileNet[12]和MobileNetV2[21]提出了depthwise可分卷积,它是在分组卷积的基础上提出的,既节省了计算成本,又保持了卷积的判别能力。然而,depthwise可分离卷积在卷积1×1中花费了95%的计算时间,导致两个连续的层(Conv 1×1和Conv DW 3×3)[12]之间存在较大的MAdds间隙(即两者的MAdds的差距较大)。这个缺口对那些加载所有网络权值来执行卷积[24]的嵌入式系统是不友好的:嵌入式系统需要额外的缓冲区来执行卷积1×1。
为了保持块内计算强度的平衡,VarGNet[26]将组内的信道数设为常数S。可变分组卷积的计算代价为:

该层的输入为hi × wi × ci,输出为hi × wi × ci+1。k是核的大小。当MobileNet[12]中使用可变分组卷积代替depthwise卷积时,pointwise卷积的计算成本为:
![]()
这样可变分组卷积和pointwise卷积的计算开销比例为 k2S / ci+2 ,而depthwise卷积和pointwise卷积的比例为k2 / ci+2。实际上,ci+2 >> k2, S > 1,所以 k2S / ci+2 > k2 / ci+2。因此,在pointwise卷积的基础上使用可变分组卷积而不是depthwise卷积,在块内的计算会更加均衡。
S > 1表示与depthwise卷积(核大小相同时)相比,可变分组卷积具有更高的MAdds和更大的网络容量,能够提取更多的信息。
2.2. Blocks of Variable Group Network
在嵌入式系统[24]上,当一个块被分组并一起计算时,片外存储器和片内存储器之间的通信才会发生在块计算的开始和结束。为了限制通信开销,与normal块中VarGNet将输出通道的数量设置为与输入通道的数量相同。同时,VarGNet使用可变分组卷积将块开始处的C通道扩展为2C通道,以保持块的泛化能力。我们使用的normal块如图1(a)所示,向下采样块如图1(b)所示。不同于VarGNet[26]中的块,我们在normal块中加入SE块,并使用PReLU代替ReLU来提高块的识别能力。

2.3. Lightweight Network for Face Recognition
2.3.1 Head setting
人脸识别的主要挑战是测试/训练阶段涉及的大规模身份识别。它需要尽可能多的辨别能力来支持区分数百万种身份。为了在轻量级网络中保留这种能力,我们在网络开始时使用stride=1的3×3 卷积层,然后在VarGNet中使用stride=2的3×3卷积。它类似于[3]的输入设置。VarGNet中第一个卷积的输出特征大小将在之后进行下采样,如图1(c)所示。
2.3.2 Embedding setting
为了获得人脸嵌入信息,许多工作[3,17]直接在最后一个卷积层的顶部使用一个全连接层。然而,当上一个卷积的输出特征相对较大时,全连接层的参数就会很大。例如,在ResNet 100[3]中,最后一个卷积层的输出为7×7×512,那么fc层的参数(嵌入大小为512)为7×7×512×512。fc层整体嵌入参数为12.25M,内存占用49M(float32)!
为了设计一个轻量级的网络(内存占用小于20M, FLOPs小于1G),我们在最后一个卷积层后使用可变分组卷积将特征映射缩小到fc层之前的1×1×512。因此,fc层用于嵌入的内存占用只有1M。图1(d)为嵌入块设置。在fc层之前将特征张量压缩到1×1×512进行嵌入是有风险的,因为这个特征张量包含的信息是有限的。为了避免重要信息的丢失,我们在上一个conv之后扩展了渠道,尽可能多的保留信息。然后利用可变分组卷积和pointwise卷积来减少参数和计算成本,同时保持信息。
具体来说,我们首先使用1×1的卷积层将通道从320扩展到1024。然后利用7×7可变分组卷积层(一组8个通道)将特征张量从7×7×1024缩小到1×1×1024。最后利用pointwise卷积将通道连接起来,将特征张量输出到1×1×512。新的嵌入块设置仅占用5.78M,而原来的fc层占用磁盘上的30M(7×7×320×512)。
第3.3节中我们的网络与VarGNet的对比实验证明了我们的网络在人脸识别任务上的有效性。
2.3.3 Overall architecture
我们的轻量级网络(VarGFaceNet)的总体架构如表1所示:
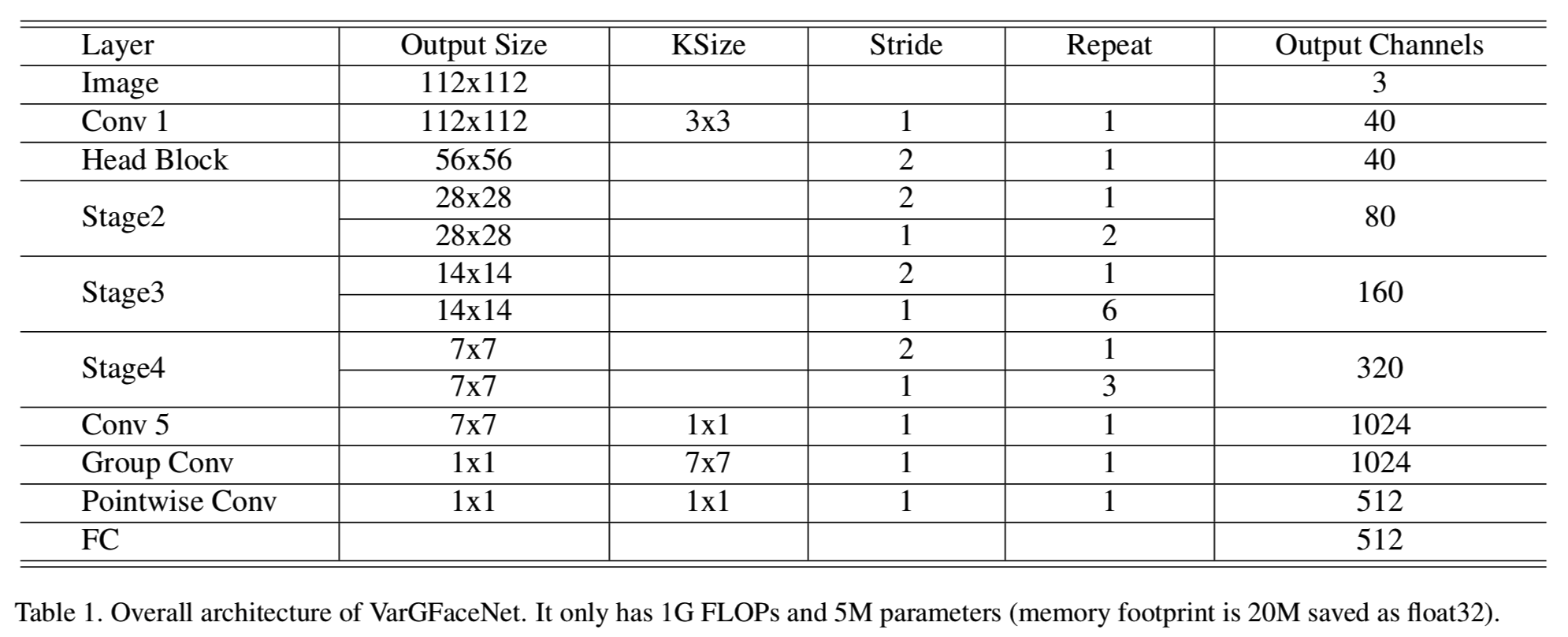
我们的VarGFaceNet的内存占用是20M,而FLOPs是1G。根据经验,我们在一个组中设S = 8。得益于可变分组卷积、Head设置和特定的嵌入设置,VarGFaceNet可以在有限的计算成本和参数下实现良好的人脸识别性能。在第三部分,我们将展示我们的网络在一百万干扰物人脸识别任务上的有效性。
2.4. Angular Distillation Loss
知识蒸馏可以将大网络的解释能力转化为小网络[12],因此在轻量级网络训练中得到了广泛的应用。利用知识蒸馏的大部分任务是封闭数据集任务[20,11]。他们使用分数/logits或嵌入/特征量来计算l2距离或交叉熵作为损失。然而,对于公开数据集任务,训练集的得分/logits中包含的测试集信息有限,在某些情况下特征值的精确匹配可能过于正则化。为了提取有用信息,避免过度正则化,[6]提出了知识蒸馏的角度蒸馏损失(angular distillation loss):

Fti是教师模型的第i个特征,Fsi是学生模型的第i个特征。m是每个batch的样本数量。等式4首先计算教师和学生特征之间的余弦相似度,然后最小化该相似度与1之间的l2距离。受[6]的启发,我们提出使用等式5来提高实现效率。由于余弦相似度小于1,最小化等式4等于最小化等式 5:
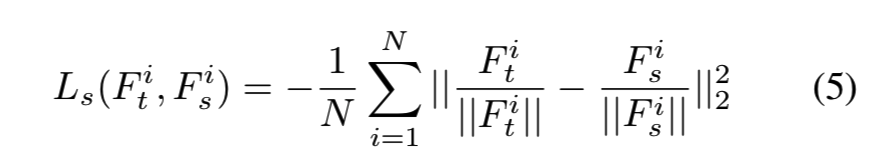
与以往精确切特征的l2损失相比,等式4和等式侧重于角度信息和嵌入分布。
另外,我们使用arcface[3]作为我们的分类损失,同时也注意到了角度的信息:

综上所述,我们在训练中使用的目标函数为:
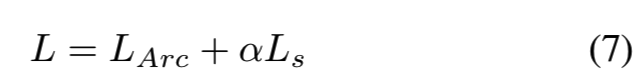
一般实现中设置α=7
2.5. Recursive Knowledge Distillation
当教师模型与学生模型之间存在较大差异时,单代知识蒸馏有时难以传递足够的知识。例如,在我们的实施中,教师模型的FLOPs是24G,而学生模型的FLOPs是1G。教师模型参数数为108M,学生模型参数数为5M。此外,教师模型和学生模型的不同架构和块设置也增加了训练的复杂性。为了提高学生网络的识别和泛化能力,我们提出了递归知识蒸馏,利用第一代学生模型初始化第二代学生,如图2所示:

在递归知识提取过程中,我们在所有代中使用相同的教师模型。这意味着指导学生模型的样本的角度信息是不变的。使用递归知识提取有两个优点:
- 当应用良好的初始化时,更容易接近老师模型的引导方向。
- 第一代的分类损失边际与导向角信息之间的冲突将在下一代中得到缓解。
第3节的实验结果说明了递归知识蒸馏的性能。
3. Experiments
在本节中,我们首先介绍数据集和评估度量。然后,为了证明我们的VarGFaceNet的有效性,我们将我们的网络与y2网络(一个更深层次的mobilefacenet[2,3])进行了比较。在此基础上,研究了不同教师模式对知识提取的影响。最后,我们展示了VarGFaceNet在LFR2019挑战中使用递归知识蒸馏的竞争性能。
3.1. Datasets and Evaluation Metric
使用RetinaFace截取图像中的人脸,并resize到112*112
3.2. VarGFaceNet train from scratch
为了验证VarGFaceNet的效率和有效性,我们首先从头开始训练我们的网络,并与mobilefacenet(y2)进行性能比较[2,3]。在训练过程中,我们使用arcface loss作为分类的目标函数。表2给出了VarGFaceNet和y2的比较结果:

可以看出,在1G FLOPs的限制下,VarGFaceNet能够在验证集上获得更好的人脸识别性能。与y2相比,我们对AgeDB-30、CFP-FP的验证结果分别增加了0.6%和0.2%,对deepglint-light (TPR@FPR=1e-8)的测试结果增加了5%。要获得更好的性能,有两个直觉:
1. 当限制FLOPs时,因为使用了可变分组卷积,我们的网络可以包含比y2更多的参数。在y2中最大的通道数是256,而我们最后的卷积层是320
2. 我们的嵌入设置可以提取更多的基本信息。y2将通道数从256扩展到512,然后使用7×7depthwise卷积得到fc层之前的特征张量。我们将通道数量从320个扩展到1024个,然后使用具有更大网络容量的可变分组卷积和pointwise卷积得到fc层之前的特征张量。
3.3. VarGFaceNet guided by ResNet
为了获得比从头开始训练更高的性能,利用角度蒸馏损失,采用更大的网络进行知识蒸馏。此外,我们还进行了实验来研究不同的教师模型对VarGFaceNet的影响。我们使用带有SE的ResNet 100[9]作为我们的教师模型。教师模型有24G FLOPs和108M参数。结果如表3所示:
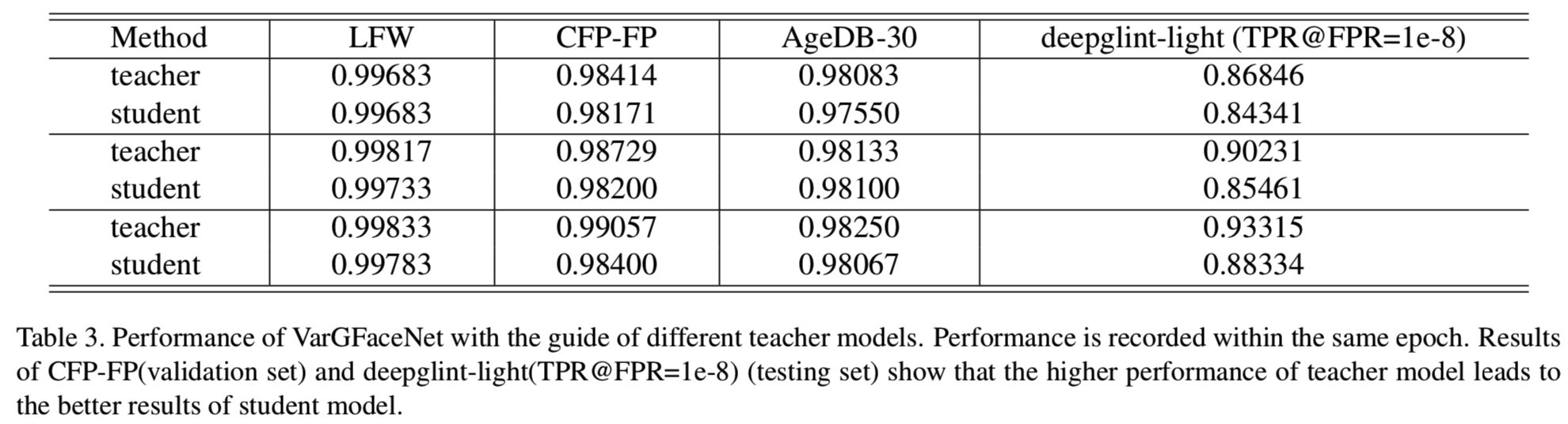
可以观察到:
1. 尽管教师和学生的结构有很大的不同,VarGFaceNet仍然接近ResNet的性能;
2. VarGFaceNet的性能与教师模型的性能高度相关。教师模型性能越高,VarGFaceNet学习的解释能力越强。
为了验证我们的设置层(即Embedding setting,图1(d))的效率,我们在我们的网络和VarGNet之间进行了比较实验。使用相同的教师网络,我们将VarGNet的head设置改为我们的head设置进行公平比较,并使用相同的loss函数。在表4中,普通VarGNet在LFW、CFP-FP、AgeDB-30中的精度较低。在VarGNet中,最后一个卷积层和fc层之间只有一个平均池化层。结果表明,我们的嵌入设置更适合人脸识别任务,因为它可以提取更多的基本信息。
3.4. Recursive Knowledge Distillation
正如我们在第2.5节中所讨论的,当教师模型与学生模型之间存在较大差异时,知识的一代积累可能不足以实现知识的转移。为了验证该模型,我们使用ResNet 100模型作为我们的教师模型,并在VarGFaceNet上进行递归知识提取。我们在下一代中训练模型时的性能改进如表5所示:

LFW和AgeDB-30的结果增加了,而deeplint-linght的测试结果(TPR@FPR=1e-8)比前一代增加了0.4%。此外,我们相信,如果我们在更多代中继续进行训练,将会导致更好的表现。
4. Conclusion
本文提出了一种用于大规模人脸识别的高效轻量级网络VarGFaceNet。得益于可变分组卷积,VarGFaceNet能够在效率和性能之间找到更好的平衡。针对人脸识别的Head设置和嵌入设置(Embedding setting)在减少参数的同时有助于信息的保存。此外,为了提高轻量级网络的解释能力,我们采用角蒸馏损失的等价性作为目标函数,提出了一种递归知识蒸馏策略。在LFR挑战中的最新表现证明了我们方法的优越性。