Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks
Abstract
最近,深度卷积神经网络的解释引起了越来越多的关注,因为它有助于理解网络的内部机制和网络做出特定决策的原因。在计算机视觉领域,可视化和理解深度网络最流行的方法之一是生成显著性maps(saliency maps),突出显示与网络决策最相关的显著区域。然而,现有方法生成的saliency maps要么只能反映网络预测的微小变化,要么计算saliency maps的过程需要大量的时间。我们提出了一种高效的saliency map生成方法Group score-weighted Class Activation Mapping (Group-CAM),该方法采用“split-transform-merge”策略生成saliency maps。具体来说,对于输入图像,类激活首先被分成组。在每一组中,子激活被求和以及去噪操作后作为一个初始mask。之后,将初始masks用有意义的扰动进行变换,然后应用于保留输入(即masked输入)的子像素,然后将这些子像素输入到网络中计算置信度分数。最后,对初始masks进行加权求和,形成最终的saliency maps,其中的权重是由masked输入产生的置信度分数。Group-CAM既高效又有效,它在生成与目标相关的saliency maps时只需要对网络进行几十次查询。因此,Group-CAM可以作为一种有效的数据增强技巧来微调网络。我们综合评估了Group-CAM在常用基准上的性能,包括在ImageNet-1k上的deletion和insertion 测试,以及在COCO2017上的pointing game测试。大量的实验结果表明,与目前最先进的解释方法相比,Group-CAM取得了更好的视觉性能。代码可见https://github.com/wofmanaf/Group-CAM。
1. Introduction
理解和解释由深度神经网络(DNN)做出的决策对人类来说至关重要,因为它有助于构建DNN模型的信任度[5,2,9,17]。在计算机视觉领域,一项关键技术是生成直观的热图,突出显示与DNN决策最相关的区域。
确定salient区域的一种常见方法是依赖于模型输出中的变化,例如预测分数关于输入图像的变化。例如,RISE[7]通过使用随机masked版本的图像探索模型并获得相应的输出来经验估计重要性。虽然RISE提供了非常引人注目的结果,但是会生成数以千计的随机masked,并应用于查询模型,使其效率低下。
其他方法,如GradCAM[11],通过在网络的目标层中反向传播预测分数来计算梯度,并将其作为权重来合并正向特征maps。这些方法通常比RISE更快,因为它们只需要对网络[8]进行单个或固定数量的查询。但是GradCAM的结果仅仅反映了预测的微小变化,而这些变化并不一定反映了足以改变网络决策的大变化。自然地,一个问题出现了:“是否有一种方法能够以更高效的方式产生真正反映模型决策的结果?”
为了回答这个问题,我们首先回顾一下RISE背后的直觉。让![]() 表示一个分布为
表示一个分布为![]() 的随机二进制mask,输入图像
的随机二进制mask,输入图像![]() 可以通过
可以通过![]() 去对输入mask,来保留像素的子集,其中
去对输入mask,来保留像素的子集,其中![]() 表示元素级乘法。然后应用masked图像产生置信度分数,以衡量这些保留的像素的贡献。最后,可以通过结合大量随机masks和与之相关的分数来生成saliency map。研究发现,最耗时的过程是生成随机masks和对神经网络进行多次查询。
表示元素级乘法。然后应用masked图像产生置信度分数,以衡量这些保留的像素的贡献。最后,可以通过结合大量随机masks和与之相关的分数来生成saliency map。研究发现,最耗时的过程是生成随机masks和对神经网络进行多次查询。
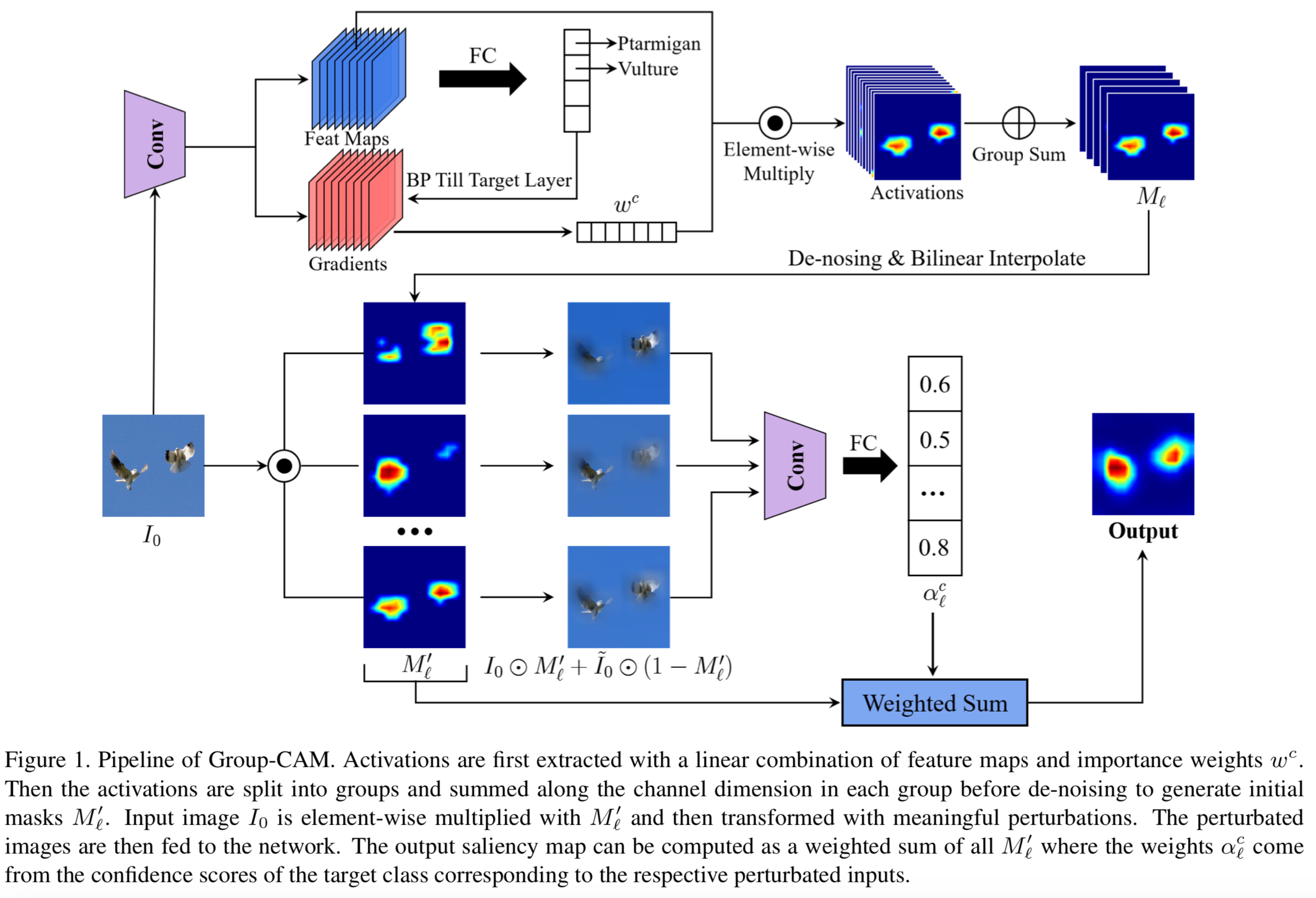
为了解决效率问题,我们提出Group score-weighted Class Activation Mapping (Group-CAM)方法,采用“split-transform-merge”策略生成saliency maps。具体来说,对于输入图像,类激活首先被分成组。在每一组中,沿channels维度将子激活求和,作为初始masks。然而,由于梯度消失,直接应用初始masks来保持输入像素可能会导致噪声视觉。因此,我们设计了一种去噪策略来过滤初始masks中不太重要的像素。此外,为了减轻模糊区域和salient区域之间的尖锐边界的对抗效应,我们利用输入的模糊信息来替换masked图像的无保留区域(像素为0值)。最后,Group-CAM的saliency map可以计算为分组初始masks的加权和,其中的权重是由masked输入产生的置信分数。Group-CAM非常高效,它可以在对网络进行数十次查询后产生引人瞩目的目标相关saliency maps。因此,Group-CAM可以用于训练/微调分类方法。Group-CAM的整体架构如图1所示。
本文的主要贡献总结如下:
(1)引入了Group-CAM这种高效的深度卷积网络解释方法,估计输入图像像素对模型预测的重要性;
(2)提出了一种新的初始masks生产策略,通过简单的分组group sum类激活(class activations)只生成几十个初始masks,使得Group-CAM非常快;
(3)在ImageNet-1k和MS COCO2017上对Group-CAM进行综合评价。结果表明,Group-CAM的计算量更少,但视觉性能更好;
(4)我们扩展了saliency方法的应用,并将Group-CAM作为一种有效的数据补充技巧用于分类网络的微调,大量实验结果表明Group-CAM可以大幅度提高网络的性能。
需要注意的是,如果Group-CAM中的group数设置为1,并且没有采用去噪策略,那么Group-CAM可以简化为Grad-CAM。
2. Related Work
Region-based Saliency Methods. 近年来,人们提出了许多将输入归因于输出预测的saliency方法。一套方法采用masks来保留输入的某些区域,并通过对这些区域执行一个该网络的前向传播来测量这些区域对输出的影响。这些类型的saliency方法称为基于区域的saliency方法。其中,RISE首先生成数千个随机masks,然后使用它们来mask输入。然后将随机masks与对应的masked图像的预测分数进行线性组合,作为最终saliency map。Score-CAM采用目标层(目标层通常包含数千个feature maps)的feature map作为初始masks来计算saliency map,而不是生成随机masks。与RISE和Score-CAM不同,XRAI首先对输入图像进行过分割,然后迭代测试每个区域的重要性,根据属性分数将小区域合并成大区域。基于区域的方法通常产生更好的人类可解释的可视化结果,但效率较低,因为它们需要对神经网络进行大量查询。
Activation-based Saliency Methods. 这些方法结合所选卷积层的激活(通常是反向传播梯度和特征maps的组合)来形成解释。CAM和Grad-CAM采用激活的线性组合,形成有着细粒度细节的热图。Grad-CAMpp扩展了Grad-CAM,并使用目标层中关于特定类别分数的特征maps的正偏导数的加权组合作为权重,为相应的类别标签生成一个视觉解释。基于激活的方法通常比基于区域的方法更快,因为它们只需要对模型进行单个或固定数量的查询。然而,基于激活的方法的结果只反映了预测的无穷小的变化,这些变化不一定反映出足以改变神经网络决策的变化。
Grouped Features. 学习特征分组可以追溯到AlexNet,其动机是将模型分配到更多的GPU资源上。MobileNets和ShuffleNets将每个通道视为一个组,并对这些组内的空间关系进行建模。ResNeXT以可扩展的方式利用split-transform-merge策略,即将特性maps拆分为组,对每个子特征应用相同的转换策略,然后将转换后的子特征连接起来。虽然split-transform-merge策略已广泛应用于学习特征,但在可解释AI领域仍没有采用该策略的工作。
3. Group-CAM
在该节中,我们首先描述了Group-CAM的算法,然后解释其背后的动机。细节可见算法1:

3.1. Initial Masks
让![]() 表示输入图像,
表示输入图像,![]() 表示一个使用输入
表示一个使用输入![]() 预测类
预测类![]() 的分数
的分数![]() 的深度神经网络。为了得到目标卷积层的类可区分的初始组masks,我们首先计算第k个特征map
的深度神经网络。为了得到目标卷积层的类可区分的初始组masks,我们首先计算第k个特征map ![]() 的
的![]() 分数的梯度。然后对这些梯度的长宽维度(分别用i,j表示)进行全局平均池化来得到神经元重要性权重:
分数的梯度。然后对这些梯度的长宽维度(分别用i,j表示)进行全局平均池化来得到神经元重要性权重:
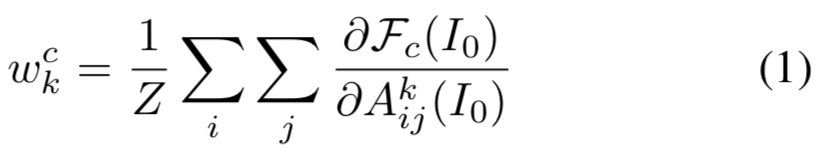
其中![]() 表示特征map
表示特征map ![]() 的像素数量。
的像素数量。
假设![]() 是目标层特征maps的channels数量,我们首先拆分所有特征maps和神经元重要性权重成
是目标层特征maps的channels数量,我们首先拆分所有特征maps和神经元重要性权重成![]() 个组,然后每个组中的初始mask可计算为:
个组,然后每个组中的初始mask可计算为:

![]() 是特征maps和梯度的组合,意味着当DNN的梯度因为ReLU的flat zero-gradient区域而趋向于消失时,
是特征maps和梯度的组合,意味着当DNN的梯度因为ReLU的flat zero-gradient区域而趋向于消失时,![]() 在视觉上是有噪音的。因此直接将
在视觉上是有噪音的。因此直接将![]() 作为初始mask是不合适的
作为初始mask是不合适的
为了修复这个问题,我们实现一个去噪音函数(de-noising function)去过滤![]() 中小于
中小于![]() 的像素,其中
的像素,其中![]() 是用来计算
是用来计算![]() 第Θ个百分位数的函数
第Θ个百分位数的函数
正式来说,对于![]() 的标量
的标量![]() ,去噪音函数可表示为:
,去噪音函数可表示为:

最好是为激活map生成更平滑的mask,而不是设置所有像素为二进制值。具体来说,就是我们通过使用min-max归一化方法将![]() 的原始值按比例设置为[0,1]范围中的值
的原始值按比例设置为[0,1]范围中的值
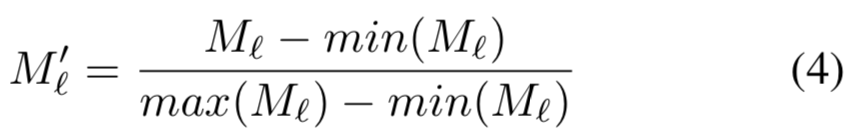
其中![]() 是使用双线性插值(bilinear interpolate)上采样到和输入
是使用双线性插值(bilinear interpolate)上采样到和输入![]() 相同分辨率的结果,用来mask输入
相同分辨率的结果,用来mask输入
3.2. Saliency Map Generation
众所周知,如果saliency方法实际上是识别对模型预测有重要意义的像素,这应该体现在模型对重建图像[5]的输出中。然而,由于masked和salient区域之间的尖锐边界,仅仅标注感兴趣的区域以外的图像像素会导致意想不到的效果。因此,在测试特征子集[3]的重要性时,将这种对抗效应最小化是至关重要的。
为了解决上面的问题,我们以一个输入的masked版本开始,使用模糊信息替换没保留的区域(即像素值为0的区域),然后实现该图像的分类去测量初始masks的重要性。模糊图像可计算为:
![]()
其中![]() 是与
是与![]() 有着相同形状大小的基线图像,且其类c的置信度很低。
有着相同形状大小的基线图像,且其类c的置信度很低。
保留区域![]() 的贡献
的贡献![]() 可计算为:
可计算为:
![]()
最后的saliency map是权重![]() 和初始masks的线性结合:
和初始masks的线性结合:
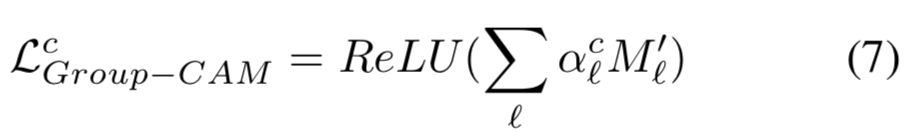
4. Experiments
在本节中,我们首先利用消融研究来研究组数G和过滤阈值θ的影响。然后我们应用一个完整性检查(sanity check)来测试Group-CAM是否对模型参数敏感。最后,我们将所提出的Group-CAM与其他流行的saliency方法进行比较,以评价其性能。
4.1. Experimental Setup
本节的实验使用常用的计算机视觉数据集,包括ImageNet-1k[10]和MS COCO2017[6]。对于这两个数据集,所有图像都被调整为3 × 224 × 224,然后转换为张量,并归一化到范围[0,1]。除此之外不再执行任何预处理。我们报告使用预训练的torchvision视觉模型VGG19[12]作为基分类器的insertion and deletion test 结果,其他结果实现在预训练的ResNet-50[4]上。除非明确说明,Group-CAM采用的组数G为32,等式3中的θ阈值为70。为了进行公平的比较,所有saliency maps都用双线性插值上采样到224 × 224。
4.2. Class Discriminative Visualization
我们定性地和最近的SOTA方法产生的saliency maps进行了比较,包括基于梯度的方法(Guided Backpropagation [14], IntegrateGrad [15], SmoothGrad[13]),基于区域的方法(RISE [7], XRAI[5]),以及基于激活的方法(Grad-CAM [11], Score-CAM[16]),以验证Group-CAM的有效性。
如图2所示,Group-CAM结果中的随机噪声比基于梯度的方法和基于激活的方法的结果要小得多。此外,与基于梯度的方法相比,Group-CAM生成更平滑的saliency maps。

我们进一步进行实验来检验Group-CAM是否能够区分不同的类。如图3所示,VGG19将输入分类为“bull mastiff”,置信度为46.06%,“tiger cat”置信度为0.39%。Group-CAM正确给出了这两个类别的解释位置,尽管后者的分类分数远低于前者。说明Group-CAM可以区分不同类别。

4.3. Deletion and Insertion
我们遵循[7]进行deletion和insertion测试,以评估不同的saliency方法。deletion度量背后的直觉是,删除与类最相关的像素/区域将导致分类分数显著下降。另一方面,insertion度量从模糊的图像开始,并逐渐重新引入内容,这将产生更真实的图像,并具有减轻对抗性攻击样本的影响的额外优势。在deletion测试中,我们根据saliency map的值,每次将原始图像中1%的像素逐步替换为高度模糊的版本,直到没有像素剩余。与deletion测试相反,insertion测试将模糊图像的1%像素替换为原始图像,直到图像完全恢复。我们以Softmax作为定量指标计算分类分数的AUC。另外,我们还提供了综合评价deletion和insertion结果的over-all分数,通过AUC(insertion)−AUC(deletion)来计算。示例如图4所示。表1报告了超过10k张图像的平均结果。
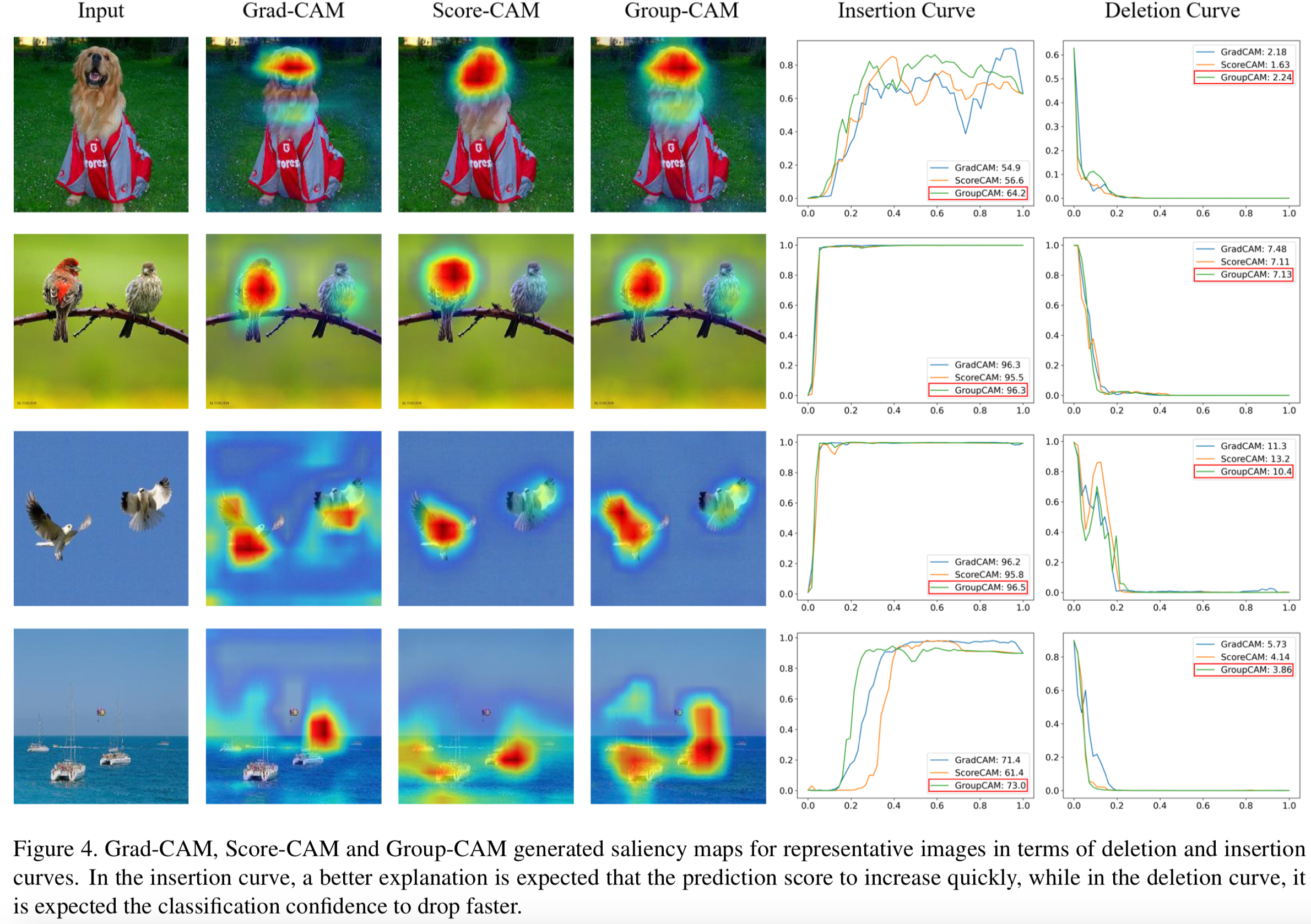

如表1所示,所提出的Group-CAM在insertion和over-all AUC方面优于其他相关方法。此外,除了XRAI之外,Group-CAM在deletion AUC方面也超过了其他方法。
Ablation Studies. 我们报告了Group-CAM对在ImageNet-1k上随机采样的5k张图像的消融研究结果,以深入研究滤波阈值θ和组数G的影响。结果见图5和表2。
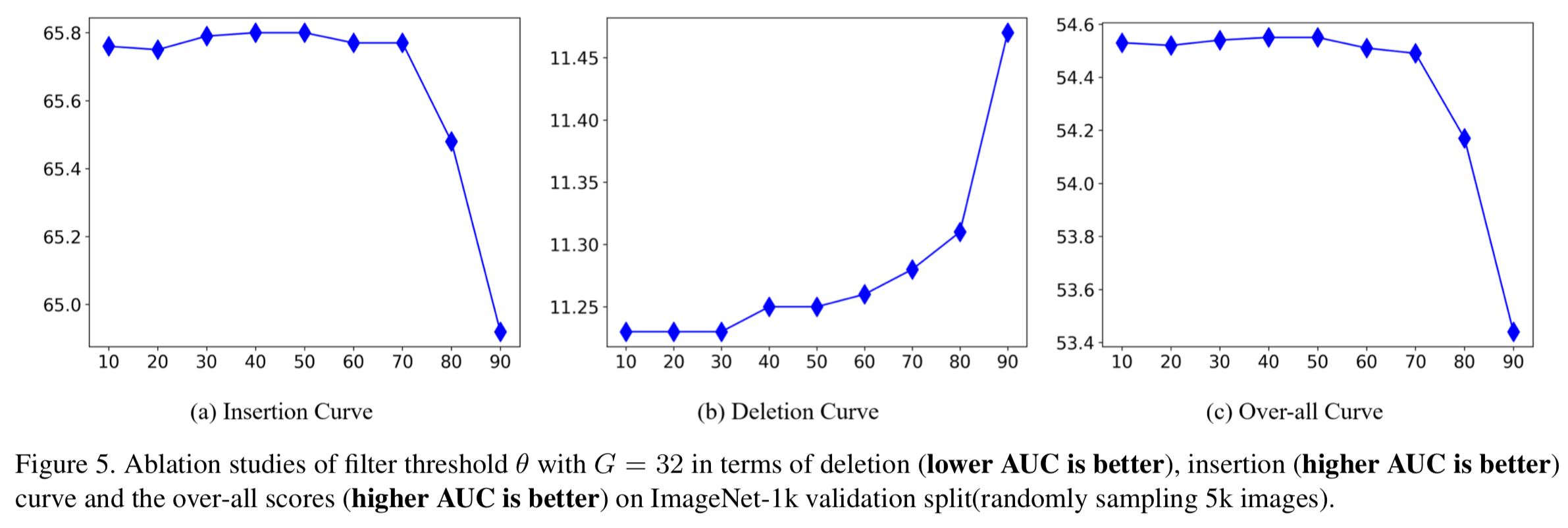

从图5可以看出,阈值θ对Group-CAM的性能有显著影响(over-all 分数波动超过1.1%)。当θ较小时,随着θ的增加,over-all 分数趋于稳定。然后,随着θ的增加,当θ > 70时,over-all 分数迅速下降。在这里,为了权衡insertion和deletion结果,我们将θ = 70设为默认值。
此外,从表2中我们可以看出,over-all 分数随着G的增加而增加。但是,正如算法1中所介绍的,G越大,意味着计算机成本越高。为了折衷起见,我们将G = 32设置为Group-CAM的默认组数。
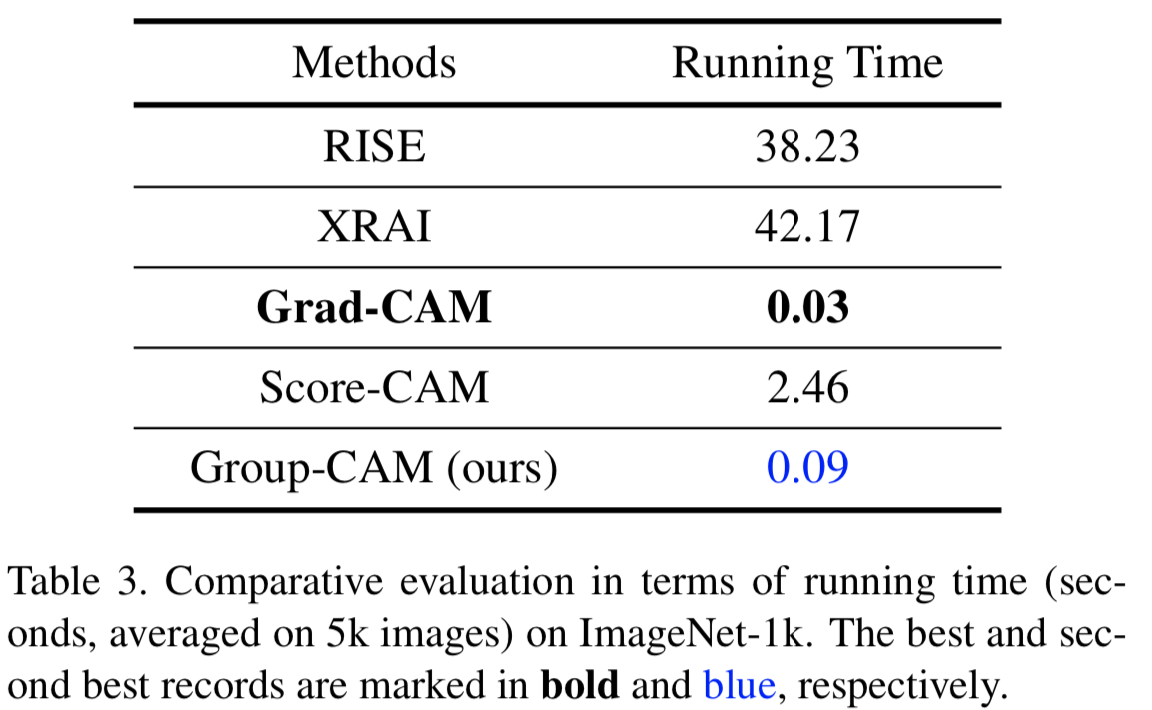
Running Time. 在表3中,我们总结了RISE [7], XRAI [5], Grad-CAM [11], Score-CAM[16]和提出的Group-CAM在一个NVIDIA 2080Ti GPU上的平均运行时间。如表3所示,Grad-CAM和Group-CAM的平均运行时间均小于1秒,在所有方法中效果最好。结合表1和表3,我们观察到尽管Group-CAM运行速度比Grad-CAM慢,但它获得了更好的性能。
4.4. Localization Evaluation
在这一部分中,我们采用MS COCO2017上的pointing game[18],通过定位能力来衡量生成的saliency map的质量。我们使用[7]的相同的预训练的ResNet-50模型。每个目标类(如果大多数salient像素坐落在对象标注的bounding boxes中,则算是击中,即hit)的定位准确度可计算为![]() 。整体性能是通过不同类别的平均准确度来衡量的。
。整体性能是通过不同类别的平均准确度来衡量的。
从表4中,我们观察到Group-CAM胜过其他所有比较方法。具体来说,Group-CAM在平均准确度中以0.8%的差距优于基础Grad-CAM。

4.5. Sanity Check
最后,我们使用sanity check[1]来检查Group-CAM的结果是否可以被认为是对一个训练模型的行为的完全可靠的解释。具体来说,我们使用了级联随机化(cascade randomization)和独立随机化方法(independent randomization),来比较Group-CAM在预训练的VGG19模型上的输出。如图6所示,Group-CAM对分类模型参数敏感,能够产生有效的结果。

5. Fine-tuning Classification Methods
最后,我们扩展了Group-CAM的应用,并将其作为一种有效的数据扩充策略用于微调/训练分类模型。我们认为适合于网络微调的saliency方法应该具有以下两个特点:(1)saliency方法应该是高效的,可以在有限的时间内生成saliency maps;(2)生成的saliency maps应与目标目标相关联。我们的Group-CAM可以在0.09秒内生成引人瞩目的目标相关的saliency maps,设置G = 32,这意味着Group-CAM适合对网络进行微调。
为了使Group-CAM更高效,我们删除了重要性权重![]() 和去噪音过程。虽然这将会稍微削弱Group-CAM的性能,但不再需要反向传播,这可以大大节省saliency maps的生成时间。
和去噪音过程。虽然这将会稍微削弱Group-CAM的性能,但不再需要反向传播,这可以大大节省saliency maps的生成时间。
微调过程定义如下:
(1)生成输入![]() 的saliency map
的saliency map ![]() ,设置G=16,ground-truth的目标类为c
,设置G=16,ground-truth的目标类为c
(2)使用阈值Θ二值化![]() ,其中Θ是
,其中Θ是![]() 的平均值
的平均值
(3)应用等式5去得到模糊输入![]()
(4)采用![]() 去微调分类模型
去微调分类模型
因为![]() 是在训练过程中得到的,这意味着当分类模型的性能有所改善时,Group-CAM将生成更好的
是在训练过程中得到的,这意味着当分类模型的性能有所改善时,Group-CAM将生成更好的![]() ,这将返回来提升分类模型的性能
,这将返回来提升分类模型的性能
在这里,我们报告了微调ResNet-50的ImageNet-1k验证split的结果。具体来说,我们用SGD训练预处理过的ResNet-50,权重高衰减为1e-4,momentum为0.9,mini-batch size为256(使用8个GPU,每个GPU 32张图像),训练20个epochs,从初始学习率1e-3开始,每15个epoch减少10倍。对于验证集上的测试,首先将输入图像的较短边调整为256,并使用224 × 224的中心裁剪结果进行评估。
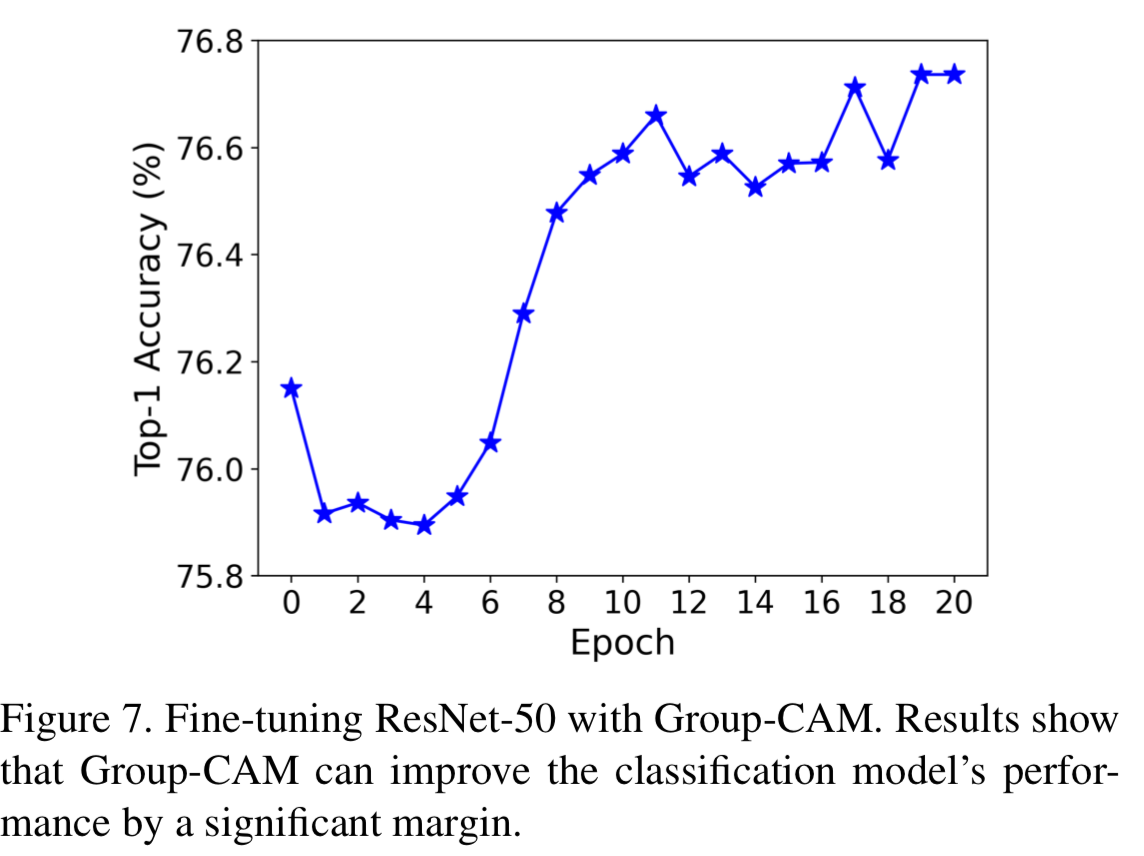
如图7所示,在Top-1准确度方面,使用Group-CAM进行微调可以提高0.59% (76.74% vs. 76.15%)的效果。
在这里,我们可视化了经过微调的ResNet-50生成的saliency maps,如图8所示。如图8所示,随着ResNet-50性能的提高,Group-CAM生成的saliency maps的噪声降低,更多地集中在重要区域。由于噪声可以在一定程度上反映性能,我们也可以将其作为判断模型是否已经收敛的提示。也就是说,如果Group-CAM生成的saliency maps不发生变化,则模型可能已经收敛。

6. Conclusion
在本文中,我们提出了Group-CAM,它采用梯度和特征map组合的grouped sum作为初始masks。利用这些初始masks保留输入像素的一个子集,然后将这些像素输入到网络中计算置信度分数,这反映了masked图像的重要性。Group-CAM的最终saliency map被计算为初始masks的加权和,其中的权重是由masked输入产生的置信度分数。所提出的Group-CAM是高效且有效的,可以作为一种数据增强技巧用于微调/训练分类模型。ImageNet-1k和COCO2017的实验结果表明,Group-CAM比目前最先进的解释方法获得了更好的视觉性能。