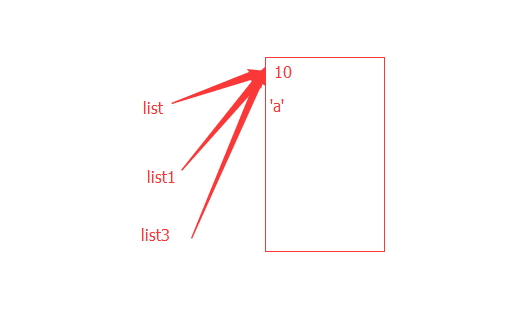
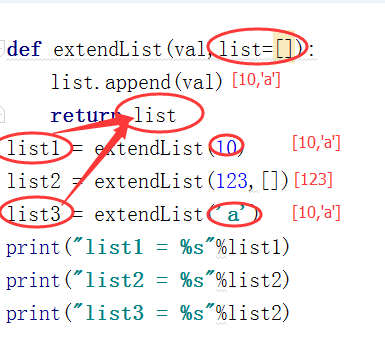
#5.Kvps = {‘1’:1,’2’:2} # theCopy = kvps #z这句话的意思是定义了一个变量, # 指向了与Kvps相同指向的内存空间所以会有以下的结果 # kvps[‘1’] = 5 # # sum = kvps[‘1’] + theCopy[‘1’] # # Print sum #他的结果是10 因为 # 6、以下何者是不合法的布尔表达式:B # # A.x in range(6) # 这个是布尔值,因为他打印出来的如print(5 in range(6)) True # B.3=a #这个不是布尔值表达式,因为他是赋值运算 # C.e>5 and 4==f # D(x-6)>5 def extendList(val,lis=[]): lis.append(val)# 第一次穿参数的时候,没有传lis的值,所以只是一个10 return lis #然后将10加进到lis中去, list1=extendList(10)#第三次传入的参数也没有传lis的值,所以这次还是用的lis list2 = extendList(123,[])#而且它的里边还存有第一次传入的10 list3 = extendList('a') print("list1 = %s"%list1) print("list2 = %s"%list2) print('list3 = %s'%list3) #打印结果如下 这是固定参数的一个魔性用法,要仔细看式子 # list1 = [10, 'a'] # list2 = [123] # list3 = [10, 'a'] #1、d={‘a’:1,’b’:2,’c’:3}请打印出key、value对(3分) d={'a':1,'b':2,'c':3} for key in d: print(key,d[key])#用这种方法比用items的方法显得高级 # # 3、使 Python/C 上机解决以下题 (13分) # # 1) # # 斐波那契数列1,2,3,5,8,13,21.....根据这样的规律, # # 编程求出400万以内最 的斐波那契数,并求出他是第 个斐波那契数。 a,b=1,2 count=2 i=0 while a+b<400000:#注意这里不能写成while i<4000000 i=a+b#因为循环结束后会包含大于400W,而是不进入下一次循环,所有写这个。 a=b b=i count+=1 print(i,count) dicta = {"a":1,"b":2,"c":3,"d":4,"f":"hello"} dictb = {"b":3,"d":5,"e":7,"m":9,"k":"world"} # # # 要求写 段代码,实现两个字典的相加,不同的key对应的值保留, # # # 相同的key对应的值相加后保留,如果是字符串就拼接,如上 例得到结果为: #dictc = {"a":1,"b":5,"c":3,"d":9,"e":7,"m":9,"f":"hello","k":"world"} dictc=dicta #先让c 指向a for k in dictb: if k in dictc: #然后再看b 中的key在里边有没有和dictc中的key 值重复的 dictc[k]=dictc[k]+dictb[k] #将他的键值赋值为相加 else: dictc[k]=dictb[k] #否则不在的话加进去 print(dictc) print(dicta) #打印结果如下 可以看到 上边是C=A 这时指向了同一个空间 # 所以当c变时 #{'a': 1, 'b': 5, 'c': 3, 'd': 9, 'f': 'hello', 'e': 7, 'm': 9, 'k': 'world'} #{'a': 1, 'b': 5, 'c': 3, 'd': 9, 'f': 'hello', 'e': 7, 'm': 9, 'k': 'world'} #生成器表达式 a=(i/2 for i in range(100)) for i in a: print(a.__next__())#也可以用 print(i) #再返回结果中打印函数名 def log(): print('sss') print('函数名字是%s'%log.__name__)#这里用了一个name方法 #最后一题 #使用的是压栈 # # 有 个数据结构如下所 ,请编写 个函数从该结构数据中返回 # 由指定的字段和对应的值组成的字典 # 。如果指定字段不存在,则跳过该字段。(10分) # fields='fld2|fld3|fld7|fld19' data={"time":"2016-08-05T13:13:05", "some_id":"ID1234", "grp1":{ "fld1":1,"fld2":2}, "xxx2":{ "fld3":0,"fld5":0.4}, "fld6":{"key":{ "fld19":1}}, "fld7":7, "fld46":8} #计算机思想:压栈,Alex def select(data,fields): l = [data] field_lst = fields.split('|') result = {} while l: # l = [] data = l.pop() #data = { "fld1":1,"fld2":2} for key in data: if type(data[key]) == dict: l.append(data[key]) # l = [{ "fld1":1,"fld2":2},{ "fld3":0,"fld5":0.4},{"key":{ "fld19":1}}] elif key in field_lst: result[key] = data[key] return result print(select(data,fields)) #祛除lis中的重复元素 #方法1要在循环中找将值一一添加 lis=[1,2,3,4,1,{'dsa':12,"dsb":11}] # lis2=[] # for i in lis: # if i not in lis2: # lis2.append(i) # lis=lis2 # print(lis) #方法2 转换成set 但是转换成列表的话,lis中有字典就会报错 lis1={'dsa':12,"dsb":11} s=set(lis) print(s)