最近项目需求,就研究了一下正则表达式的使用
具体的就是在官方文档中搜索的:https://www.runoob.com/regexp/regexp-tutorial.html
总结:
^ 为匹配输入字符串的开始位置 ,$ 为匹配输入字符串的结束位置
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
以下正则表达式匹配一个正整数,[1-9]设置第一个数字不是 0,[0-9]* 表示任意多个数字:
需求是:只能输入小于100的数,或者是*-*或者是*~*这样的范围区间(只能保留四位小数)(23.2223 或者 23.4433-99.9999 或者 11 或者11.03)
var LESSHUNDREDFOUR_REGEXP=/^([1-9])?d(.d{1,4})?$|^[1-9]?d(.d{1,4})?(-|~)[1-9]?d(.d{1,4})?$/;
//右边的值要大于左边的值,这个正则表示式无法解决,只能另外写方法了
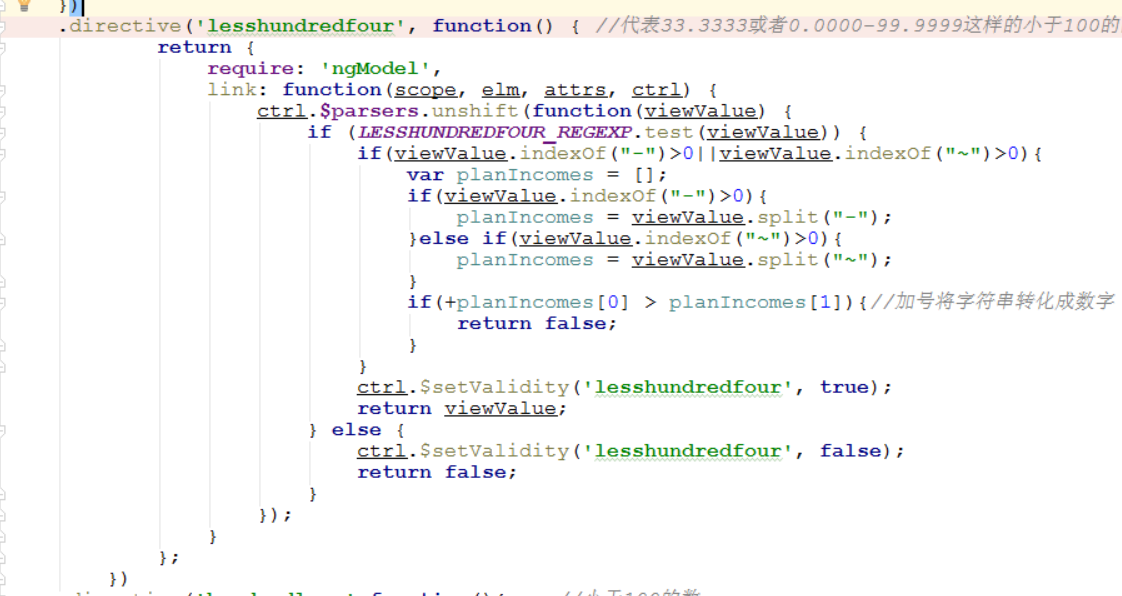
首先^([1-9])?d(.d{1,4})?$|^[1-9]?d(.d{1,4})?(-|~)[1-9]?d(.d{1,4})?$ 被 | 分为两部分
左边的:^([1-9])?d(.d{1,4})?$
([1-9])代表1-9之间的数字, ?可以出现零次或一次 可以用{0,1}代替,d代表的式0到9之间的数字 可以用[0-9]代替
===>这就代表小于100的数字
.代表小数点 d代表0-9 {1,4}代表能出现1次到4次 其中的()?代表小数点后面可以出现零次或一次
右边的:[1-9]?d(.d{1,4})?(-|~)[1-9]?d(.d{1,4})? 这个就好理解了
测试的地方:1.(可以在这里测试:http://c.runoob.com/front-end/854):
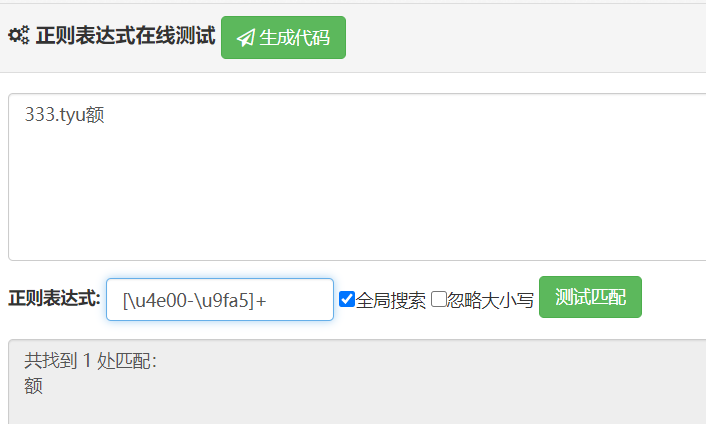
2.个人建议也可以在这里测试,浏览器的F12
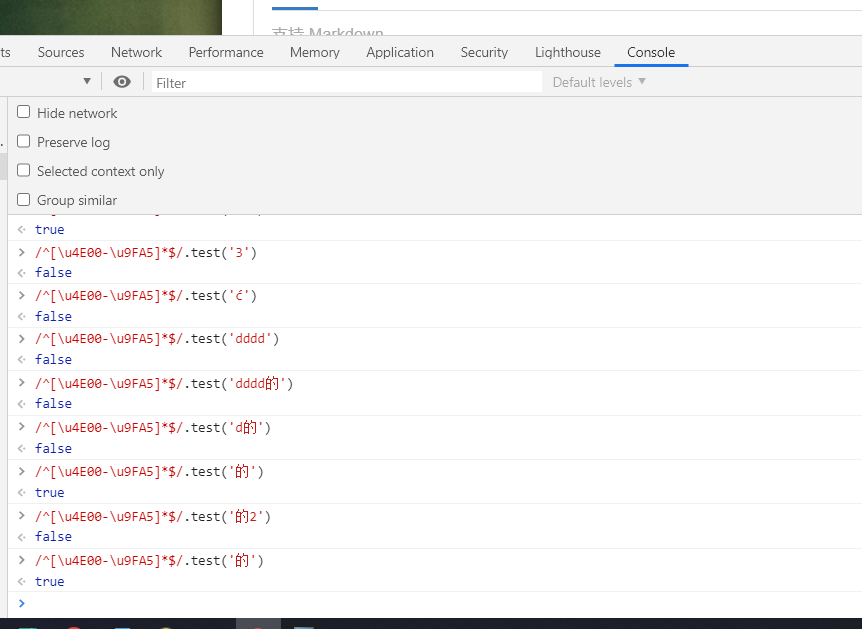
/^[u4E00-u9FA5]+$/.test('的') true
个人测试了一下去除掉^$也可以
/[u4E00-u9FA5]+/.test('的') true
代表的是含有中文的判断