今日学习内容:
模块
import以及from...import...
循环导入、相对导入、绝对导入
模块
什么是模块?
模块:就是一系列功能的结合体。
三种来源:
1.内置的(python解释器自带)
2.第三方的(别人写的)
3.自定义的(你自己的写)
四种表现形式:
1.使用python编写的py文件(也就意味着py文件也可以称之为模块:一个py文件也可以称之为一个模块)
2.已被编译为共享库或DLL的C或C++扩展(了解)
3.把一系列模块组织到一起的文件夹(文件夹下有一个init.py文件,该文件夹称之为包(一系列py文件的结合体))
4.使用C编写并连接到python解释器的内置模块
为什么要用模块?
1.用别人写好的模块(内置的,等三方的)拿来主义,极大的提高开发效率。
2.使用自己写的模块(自定义的):当程序比较庞大时,你的项目不可能只在一个py文件中,当多个py文件都需要使用相同的方法时,可以将该方法写一个py文件里,让其它文件以模块形式导过去调用即可。
如何使用模块?
需要用到import和 from...import...进行导入
注意:一定要区分那个是执行文件,哪个是被导入文件。
import
我们先创建两个py文件,run.py和md.py
#mad.py #我们随意输入一点内容 print('from the md.py') money=1000 def read1(): print('md',money) def read2(): print('md模块') read1() def change(): global money money = 0
#run.py import md #右键运行run.py文件首先会创建一个run.py的名称空间 #首次导入模块(md.py) #1、创建md.py文件名称空间 #2、运行md.py文件中的代码,将产生的名字与值存放到md.py名称空间中 #3、在执行文件中拿到一个指向名称空间的名字(md) #补充:多次导入不会再执行模块代码,会沿用第一次导入的成果。(***) money = 9999 print(md.money) # 输出1000 print(money) # 输出9999 def read1(): print('from run read1') read1() # 输出结果为from run read1 md.read1() # 输出结果为md 1000 # 使用import导入模块 访问模块名称空间中的名字统一句势:模块名.名字
运行在内存空间中的示意图
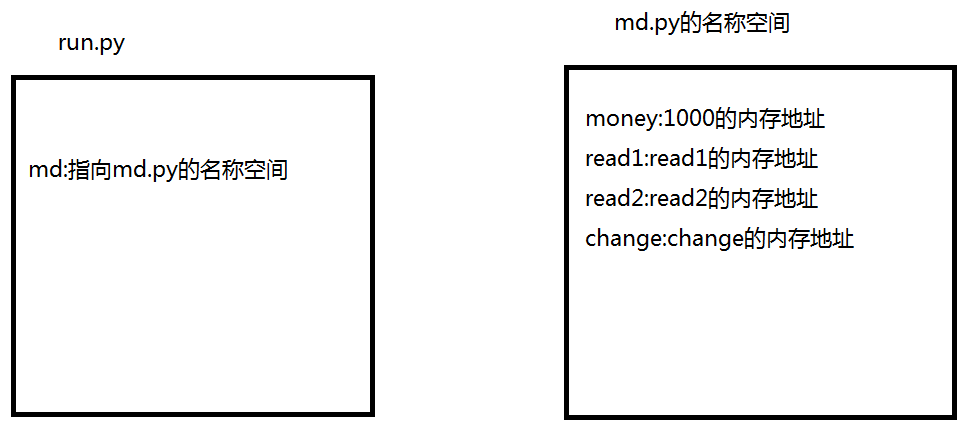
使用import导入模块 访问模块名称空间中的名字统一句势:模块名.名字,如md.money
1.指名道姓的访问模块中的名字 永远不会与执行文件中的名字冲突
2.你如果想访问模块中名字 必须用模块名.名字的方式
只要当几个模块有相同部分或者属于用一个模块,可以使用上面的方法
当几个模块没有联系的情况下 应该分多次导入
import os
import time
import md
ps:通常导入模块的句式会写在文件的开头
#当模块名字比较复杂的情况下,可以给该模块名取个别名: #格式为 import 模块名 as 别名 #访问模块中名字的时候就是将原来的模块名.名字变成别名.名字就可以了
from...import...
#和上面一样,我们同样先创建两个文件run1和md1 #然后是运行run1.py #首次导入run1.py模块 #1、创建md1.py文件名称空间 #2、运行md1.py文件内的代码,将产生的名字存放到md1.py名称空间中 #3、在执行文件中拿到一个名字,该名字直接指向md1.py名称空间中的某个名字(和上面不同的点) #利用from...import...句式 #缺点: # 1、访问模块中的名字不需要加模块名前缀 # 2、在访问模块中的名字可能会与当前执行文件中的名字冲突
# 补充 from md1 import * # 一次性将md1模块中的名字全部加载过来 不推荐使用 并且你根本不知道到底有哪些名字可以用 #以md1.py为例 __all__ = ['money','read1','read2'] # 也可以限制导入者能够拿到的名字个数 __all__ = ['','',''] 当__all__所在的文件被当做模块导入的时候 ___all__列表写什么 执行导入语句那个文件就能拿到什么 __all__不写的情况下 默认是将所在文件所有的名字都暴露给导入者
__name__的使用
#m1文件内容 def index1(): print('index1') def index2(): print('index2') print(__name__) #m2文件内容 import m1 #m1打印结果__main__ #m2打印结果m1 #当文件被当做执行文件执行时__name__打印的结果是__main__ #当文件被当做模块导入的时候__name__打印的结果是模块名(没有后缀) #if __name__ == '__main__: # 把它添加到被调用模块中,当该模块被调用时,后面的语句不会执行 #if __name__ == '__main__': # 快捷写法,main直接tab键即可
循环导入
#创建3个py文件,m1.py、m2.py、run.py #m1的内容 print('正在导入m1') from m2 import y x = 'm1' #m2的内容 print('正在导入m2') from m1 import x y = 'm2' #run的内容 import m1 #运行结果是报错cannot import name 'x' #分析运行过程:运行run之后,首先会导入m1,然后我们执行m1,执行m1会打印“正在导入m1”这句话,然后根据下一句话会调用到m2,然后执行m2,然后打印正在导入m2,然后执行第三句话,需要从m1中拿到x,但此时m1中并没有执行到给x赋值的阶段,所以相当于x没有定义,所以出现了错误
如果出现循环导入问题,那么一定是你的程序设计的不合理,循环导入问题应该在程序设计阶段就应该避免。
解决循环导入问题的方式:
方式1:将循环导入的句式写在文件最下方
方式2:函数内导入模块
方式3:将循环导入的名字 放到另外一个文件中
模块的查找顺序
1、先从内存中找(被你自己导入的)
2、内置中找(python解释器自带的)
3、sys.path中找(环境变量):
一定要分清楚谁是执行文件谁是被导入文件(****)
import sys print(sys.path) # 可以看到文件路径。是一个大列表,里面放了一对文件路径,第一个路径永远是执行文件所在的文件夹 sys.path.append() # 括号里可以添加文件路径
#第一种导入:基于当前执行文件所在文件夹路径依次往下找
#第二种导入:直接将你需要导入的那个模块所在的文件夹路径添加到system path中
绝对导入和相对导入
绝对导入必须依据执行文件所在的文件夹路径为准
绝对导入无论在执行文件中还是被导入文件都适用
相对导入
.代表的当前路径
..代表的上一级路径
...代表的是上上一级路径
注意相对导入不能再执行文件中使用
相对导入只能在被导入的模块中使用,使用相对导入 就不需要考虑
执行文件到底是谁 只需要知道模块与模块之间路径关系