1.spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程对象,叫DataFrame,并且作为分布式SQL查询引擎的作用
2.为什么要学习spark SQL
2.1 我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性
2.2 MapReduce这种计算模型效率慢,代码繁碎,很多开发者都习惯使用sql,所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快,而且Spark SQL也支持从Hive中读取数据
3.spark SQL特点

3.1 集成 3.2 同意的访问方式 3.3hive集成 3.4标准连接
4.DataFrame的概念
(1)DataFram是组成命名列的数据集,它在概念上等同于关系数据库中的表,,但在底层具有更丰富的优化
(2)DataFrame可以从各种来源构建,列如:结构化数据文件, hive中的表,外部数据库或现有RDD
(3)DataFrame API支持的语言有Scala,Java,Python和R
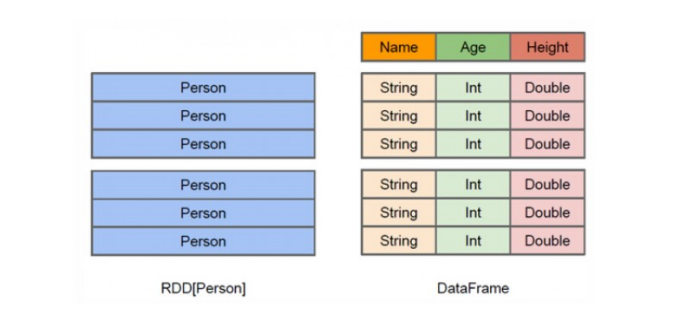
(4)从上图可以看出,DataFrame多了数据的结构信息,即schema(创建DataFrame的一种方式,后边详细介绍),RDD是分布式的 Java对象的集合
(5)DataFrame是分布式的Row对象的集合,DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化
val row = lines.map ( _.split ( "," )).map ( tp => Row ( tp ( 0 ).toInt, tp ( 1 ), tp ( 2 ), tp ( 3 ), tp ( 4 ).toDouble, tp ( 5 ).toDouble, tp ( 6 ).toInt ))
val frame: DataFrame = unit.map(tp=>{ val splits=tp.split(" ") val id=splits(0).toInt val name=splits(1) val age=splits(2).toInt val result=splits(3).toInt (id,name,age,result) }).toDF("id","name","age","address")
5.DataSet的概念
(1)Dataset是数据的分布式集合,Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一级的抽象
(2)Dataset提供了RDD的优点(强类型化,使用强大的lambda函数的能力)以及Spark SQL优化后的执行引擎的优点
(3)一个Dataset 可以从JVM对象构造,然后使用函数转换(map, flatMap,filter等)去操作
(4)Dataset API 支持Scala和Java, Python不支持Dataset API
6.创建DataFram
数据 emp.csv
7369,SMITH,CLERK,1980/12/17,1800,200,20 7499,ALLEN,SALESMAN,1981/2/20,1600,300,30 7521,WARD,SALESMAN,1981/2/22,1250,500,30 7566,JONES,MANAGER,1981/4/2,2975,900,20 7654,MARTIN,SALESMAN,1981/9/28,1250,1400,30 7698,BLAKE,MANAGER,1981/5/1,2850,122,30 7782,CLARK,MANAGER,1981/6/9,2450,344,10 7788,SCOTT,ANALYST,1987/4/19,3000,555,20 7839,KING,PRESIDENT,1981/11/17,5000,6666,10 7844,TURNER,SALESMAN,1981/9/8,1500,0,30 7876,ADAMS,CLERK,1987/5/23,1100,777,20 7900,JAMES,CLERK,1981/12/3,1950,888,30 7902,FORD,ANALYST,1981/12/3,3000,555,20 7934,MILLER,CLERK,1982/1/23,1300,57,10 7950,ZHAOYI,NANYOU,1980/1/1,1000,86,10
字段介绍:
1.编号 id 2.姓名 name 3.职业 job 4.日期 date 5.工资 sale 6.奖金 money 7.部门编号 number
方式一:spark2.0版本以前
package SparkSql import org.apache.spark.sql.{DataFrame, SQLContext} import org.apache.spark.{SparkConf, SparkContext}
object SqlDemo01 { def main(args: Array[String]): Unit = { val conf = new SparkConf () .setAppName ( this.getClass.getSimpleName ) .setMaster ( "local[1]" ) val sc = new SparkContext ( conf ) val sqlContext = new SQLContext ( sc ) //获取dataset对象 val lines:DataFrame = sqlContext.read.csv ( "E:\emp.csv" ).toDF("id","name","job","date","sale","money","number") //创建视图 lines.createTempView ( "test01" ) //书写sql语句 sqlContext.sql("select id from test01").limit(10).show() sc.stop () } }
方式二:spark 2.0之后
package SparkSql import org.apache.spark.sql.{DataFrame, SparkSession} object SqlDemo02 { def main(args: Array[String]): Unit = { val session = SparkSession.builder ().appName ( this.getClass.getSimpleName ).master ( "local[1]" ).getOrCreate () //数据源 val data: DataFrame = session.read.csv ( "E:\emp.csv" ).toDF ( "id", "name", "job", "date", "sale", "money", "number" ) //创建视图 data.createTempView ( "test01" ) //书写sql语句 session.sql ( "select * from test01" ).show () session.stop () } }
方式三:structType
package SparkSql import org.apache.spark.rdd.RDD import org.apache.spark.sql.types._ import org.apache.spark.sql.{DataFrame, Row, SparkSession} object SqlDemo03 { def main(args: Array[String]): Unit = { val session = SparkSession.builder ().appName ( this.getClass.getSimpleName ).master ( "local[1]" ).getOrCreate () //数据源 val lines: RDD[String] = session.sparkContext.textFile ( "E:\emp.csv" ) //创建row val row = lines.map ( tp => { val splits = tp.split ( "," ) Row ( splits ( 0 ).toInt, splits ( 1 ), splits ( 2 ), splits ( 3 ), splits ( 4 ).toDouble, splits ( 5 ).toDouble, splits ( 6 ).toDouble ) } ) //创建schema val schme = StructType { List ( StructField ( "id", IntegerType ), StructField ( "name", StringType ), StructField ( "job", StringType ), StructField ( "date", StringType ), StructField ( "sale", DoubleType ), StructField ( "money", DoubleType ), StructField ( "number", DoubleType ) ) } val fram: DataFrame = session.createDataFrame ( row, schme ) //创建视图 fram.createTempView ( "test01" ) //sql session.sql ( "select id,name from test01" ).show () session.stop () } }
方法四:样例类(case class 相当于表结构)
package SparkSql import org.apache.spark.sql.{DataFrame, SparkSession} object CaseDemo { /** * 样例类 * * @param args */ def main(args: Array[String]): Unit = { val session = SparkSession.builder ().appName ( this.getClass.getSimpleName ).master ( "local[1]" ).getOrCreate () //读数据 val unit = session.sparkContext.textFile ( "E:\emp.csv" ).map ( tp => tp.split ( "," ) ) //如果RDD类型要转换为DataFrame,我们必须要导入隐士转换类 import session.implicits._ val frame: DataFrame = unit.map ( tp => Casewords ( tp ( 0 ).toInt, tp ( 1 ), tp ( 2 ), tp ( 3 ), tp ( 4 ).toDouble, tp ( 5 ).toDouble, tp ( 6 ).toDouble ) ).toDF () frame.createTempView ( "test01" ) session.sql ( """ |select * |from test01 """.stripMargin ).show () } } case class Casewords( val id: Int, val name: String, val job: String, val date: String, val money: Double, val sale: Double, val number: Double) { }
7.将数据保存到mysql
package SparkSql import java.util.Properties import org.apache.spark.rdd.RDD import org.apache.spark.sql.types._ import org.apache.spark.sql.{DataFrame, Row, SparkSession} object SqlDemo03 { def main(args: Array[String]): Unit = { val session = SparkSession.builder ().appName ( this.getClass.getSimpleName ).master ( "local[*]" ).getOrCreate () //数据源 val lines: RDD[String] = session.sparkContext.textFile ( "E:\emp.csv" ) //创建row val row = lines.map ( tp => { val splits = tp.split ( "," ) Row ( splits ( 0 ).toInt, splits ( 1 ), splits ( 2 ), splits ( 3 ), splits ( 4 ).toDouble, splits ( 5 ).toDouble, splits ( 6 ).toDouble ) } ) //创建schema val schme = StructType { List ( StructField ( "id", IntegerType ), StructField ( "name", StringType ), StructField ( "job", StringType ), StructField ( "date", StringType ), StructField ( "sale", DoubleType ), StructField ( "money", DoubleType ), StructField ( "number", DoubleType ) ) } val fram: DataFrame = session.createDataFrame ( row, schme ) //创建视图 fram.createTempView ( "jobs" ) //sql val resultDF:DataFrame=session.sql ( "select id,name from jobs" ) //把数据保存到mysql表中 //创建Properties对象你配置连接mysql的用户名和密码 val pro=new Properties() pro.setProperty("user","root") pro.setProperty("password","123456") resultDF.write.jdbc("jdbc:mysql://localhost:3306/test1?characterEncoding=UTF-8&serverTimezone=GMT%2B8","jobs",pro)
//resultDF.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/test1?characterEncoding=UTF-8&serverTimezone=GMT%2B8","jobs1",pro) //转json数据 coalesce ( 1 )创建分区 将所有json文件合成一个文件
resultDF.coalesce ( 1 ).write.json ( "E:\jobs" ) session.stop () } }