在机器学习和深度学习里,极大似然估计是一个基础算法,这篇文章主要记录一下极大似然估计作用和原理
例
现在我们抛一枚特制的硬币,假设他正面朝上的概率是θ,显然这是一个二项分布,反面额概率就是1-θ,用公式表示如下
![]()
他的概率函数:
![]()
拆开写就是
![]()
似然函数:
假设投了5次硬币,结果是10011(3正2反),假设我们不知道硬币正面朝上概率θ的值,通过观察实验结果,我们可以反推θ的值,注意在这里θ是未知
我们将θ作为未知数,将出现3正2反的概率表示出来,即
![]()
这就是似然函数的形式
二项分布的似然函数如下
![]()
这里将P替换成了L(θ),拿这个例子来说,就是出现3正2反的概率其实是一个函数,根据正面朝上的概率θ值的变化,出现3正2反这一情况的概率也会随之变化,但是3正2反这一情况已经发生了,所以要想从结果反推参数,我们认为L(θ)是最大值,即3正2反这种结果发生的可能性最大时,θ的值应该取多少,也就变成了函数求极值问题,当函数取最大值的时候,极值点导数为0,因此我们可以将似然函数对θ求导,令导数为0求得θ的值。
但是此处有一个问题,极大似然估计是求似然函数的最大值情况,但是似然函数如果是凹函数呢?
极大似然估计
![]() 来求参数θ的值
来求参数θ的值
为什么取似然函数的最大值,上面已经解释过了
为了方便计算,我们将max L(θ)等价于![]()
为什么要这么做?为了方便计算,连乘经过对数函数会变成连加,同时概率是固定小于1的,很多个小于1的数连乘会使计算机产生下溢出,因此取对数操作
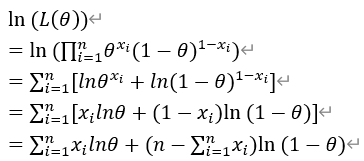
对极大似然函数求导
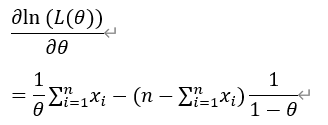
令导数为0
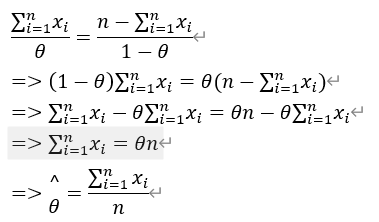
当硬币正面向上的概率P=θ hat时,例子中3正2反的情况出现的概率最大,因此当3正2反出现概率最大时,此时概率P最有可能的值就是θ hat
作用:
对于模型y=f(x|θ),输入x,输出y,参数θ
x表示样本,y表示结果,那么在参数为什么值的情况下观察出x映射y的可能性最大呢,也就是有了x->y的结果,θ最有可能的值。
通过极大似然估计去最大化似然函数,求出想要的参数θ
给定事实-->反推参数(条件)====>在这些参数(条件)下,事件发生(模型取得预期结果)概率最大
跟梯度下降算法的一些想法
我认为极大似然估计是直接求出参数值,像丢硬币实验这种简单模型可以直接使用,梯度下降则是先初始化所有参数,然后从一个随机点开始进行优化
复杂模型参数多,不能直接求所有参数准确值,因此需要先初始化然后再进行优化
似然函数的最大化可以转换成:
max L(θ)==>min (y-y^)
也就是说dl中的损失函数是可以通过极大似然估计来构建的
反向求导这个优化过程就是梯度下降算法和极大似然估计推出的y-y^=0最有可能的模型参数
其他概率分布的极大似然估计也一样,都是求他们概率密度函数连乘的最大值
以正态分布为例:
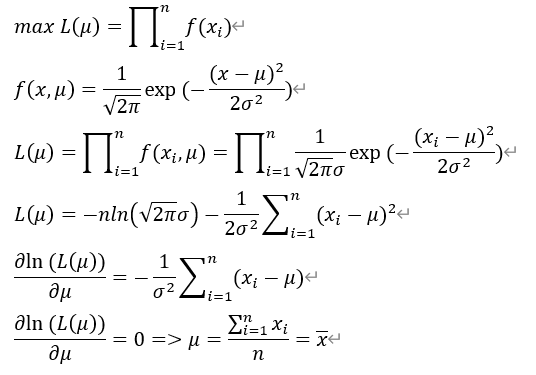
列出似然函数(概率密度函数连乘)
求似然函数最大值
求似然函数导数,令导数值为0
求出最优参数