一、mr介绍
1、MapReduce设计理念是移动计算而不是移动数据,就是把分析计算的程序,分别拷贝一份到不同的机器上,而不是移动数据.
2、计算框架有很多,不是谁替换谁的问题,是谁更适合的问题.mr离线计算框架 适合离线计算;storm流式计算框架 适合实时计算;sprak内存计算框架 适合快速得到结果的计算.
二、mr原理
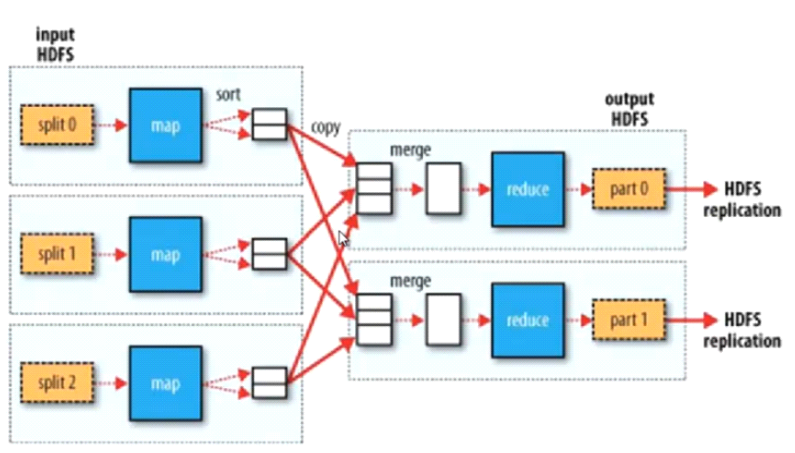
1、mr第一个部分是把hdfs的数据切成一个个split片段,第二部分是map部分,第三个部分从map执行结束到reduce执行之前都是shullf部分,第四部分就是reduce.最后part就是整个mr输出部分,保存在hdfs中.
2、mr的输入来自hdfs,每个split片段由一个map线程执行,split切分算法:max(min.split,min(max.split,block)),block大小也可以设置.
3、例:统计超大文本文件中每个单词出现的次数
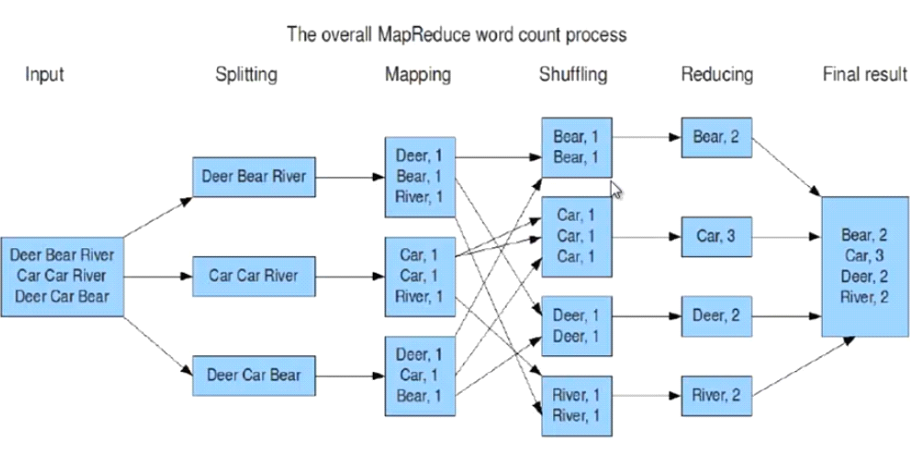
input输入是一个大文件,不要理解为一行就是一个片段,map的输入和输出必须是键值;shuff可以把map的输出按照某种key值重新切分和组合成n分,把key值符合某种范围的输出送到reduce那里处理,可以简化reduce过程,在这里shuff就是对map的输出进行合并和排序,key相同的合并到一个数据块中,然后再把key相同的数据块作为集合传给reduce;reduce作用是对map阶段的输出结果进行汇总,可以根据map输出数据量大小决定reduce个数(默认是1,可以在mapred-site.xml中配置).
5、shuff具体过程

1>shuff首先对map的输出进行partitions(分区),之后sort,再溢写到磁盘.map输出的结果首先在内存中,内存设置有一定的域值,当到达这个域值后,就溢写到磁盘,溢写之前要做几件事情,即partitions,sort,也就是说到磁盘中的数据已经分好区排好序,这个过程全是在那个map所在节点的本地,没有跨网络移动数据.
2>partitions默认的分区规则是以哈希模运算来进行分区,map输出这个对象的哈希值模reduce的个数,分区的目的是为了把map的输出进行负载均衡,或者叫解决reduce端的数据倾斜问题.map端是没有数据倾斜问题的,split切的非常平均.
3>sort排序默认的排序规则是字典排序.
4>所有输出的数据都进行了partitions和sort,接下来就溢写到磁盘,每一次溢写产生一个文件而不是追加.磁盘文件越来越多这个时候就要进行合并,也有默认的合并规则,就是按照键的哈希值进行合并(相同键哈希值相同),这个合并的过程叫combiner.这里的目的不是为了统计,目的就是为了减少map的输出,因为下一步数据给reduce可能要跨网络拷贝.
5>下来就是磁盘中的这些数据要交给reduce执行,这时可能map和reduce不在一台机器,就要进行跨网络拷贝.reduce只拷贝那些分区的时候分给自己那些数据,这时reduce端很多的小数据,需要合并,这个不是程序员控制的,默认按照key相同的进行合并,这些key相同的数据可能来自不同的map task,然后分别传给reduce执行.
ps:partitions、sort、combiner根据需求不需要就不用写.map和reduce完全程序员控制,shulff阶段只能控制一部分如paratitions,combainer.
6、reduce执行过程如下,和map很像也有溢写过程.

三、mr架构--一主多从架构
1、主JobTracker负责调度分配每一个子任务task运行与TaskTracker上,如果发现有失败的task就重新分配其任务到其它节点.每一个hadoop集群中只有一个JobTracker,一般运行在master节点上.
2、从TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务,为了减少网络带宽TaskTracker最好运行在hdfs的DataNode上,TaskTracker是map task 或者reduce task.
3、配置JobTacker,修改MapReduce的核心配置文件mapred-site.xml:
<property> <name>mapred.job.tracker</name> <value>node1:9001<value> <property>
TaskTracker默认在DN上就不用配了,JobTracker可以指定任何一台机器,但是经测试放在node3不好使,放在node1上正常运行.ps:2.0之后就没有JobTracker,TaskTracker了.
4、start-all.sh启动hdfs和mr,通过http://node1:50030查看mr的管理界面.hdfs eclipse插件略,多练习使用hadoop命令.
四、demo:统计单词在文件中出现的个数
1、确定hdfs、MapReduce、jobTracker等是否正常启动,各节点通过jps查看.
2、在Hadoop文件系统根目录中创建input文件夹.
[root@statsys-ku6 bin]# ./hadoop fs -mkdir /wangwei
3、将bin目录下的所有文件放到hadoop文件系统的input目录下.
[root@statsys-ku6 bin]# ./hadoop fs -put *.sh /wangwei
4、执行wordcount命令统计单词个数.
[root@statsys-ku6 bin]# ./hadoop jar hadoop-test.jar WordCountDemo /wangwei /out
ps:hadoop-test.jar程序代码(开发时导入hadoop-core-1.2.1.jar):
import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountDemo { public static void main(String[] args) throws Exception { if (args == null || args.length != 2) { System.err.println("Lack input && output args"); System.exit(-1); } Job job = new Job(); job.setJarByClass(WordCountDemo.class); // 为job指定输入文件 FileInputFormat.addInputPath(job, new Path(args[0])); // 为job指定输出文件 FileOutputFormat.setOutputPath(job, new Path(args[1])); // mapper job.setMapperClass(WordCounterMapper.class); // reducer job.setReducerClass(WordCounterReducer.class); // 输出key类型 job.setOutputKeyClass(Text.class); // 输出value类型 job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } private static class WordCounterMapper extends Mapper<LongWritable, Text, Text, IntWritable> { // 每次调用map方法会传入split中一行数据 key:该行数据所在文件中的位置下标 value:这行数据 protected void map(LongWritable key, Text value, Context context) throws java.io.IOException, InterruptedException { String line = value.toString(); StringTokenizer st = new StringTokenizer(line); while (st.hasMoreElements()) { String token = st.nextToken(); if (!isWord(token)) {// 不是单词 continue; } // 这个单词出现了一次 context.write(new Text(token), new IntWritable(1)); // map的输出 } }; } private static class WordCounterReducer extends Reducer<Text, IntWritable, Text, IntWritable> { protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws java.io.IOException,InterruptedException { int sum = 0; for (IntWritable value : values) { //这里是迭代器,如果是集合的话可能撑爆内存 sum += value.get(); } context.write(key, new IntWritable(sum)); }; } //是否为合法的单词[a-zA-Z]+ static boolean isWord(String input) { return input.matches("[a-zA-Z]+"); } }
ps: hadoop fs -lsr /out 查看reduce输出,hadoop fs -get /out /root/ 下载查看输出.