Auto-ReID: Searching for a Part-aware ConvNet for Person Re-Identification
2019-03-26 15:27:10
Paper:https://arxiv.org/pdf/1903.09776.pdf
Code: https://github.com/D-X-Y/Auto-ReID-and-Others
1. Background and Motivation:
本文将 NAS 的技术用到了 person re-ID 上,但是并非简单的用 NAS 技术来搜索一种 ConvNet,本文考虑到 re-ID 的特色,将其结合到 NAS 中。当然之所以这么做,是因为作者认为专门为 classification 任务所设计的 CNN backbones,并不是完美的适合 re-ID 的任务,因为其网络模型可能含有 noisy, redundancy and missing components。作者认为 NAS 的方法用到 re-ID 的任务上,有如下三个挑战:
1). the body structure information 在 re-ID 中扮演着重要的作用,但是,现有的 NAS 方法却无法建模;
2). re-ID 算法通常在 CNN backbone 的 tail 部分来编码结构化信息,但是,大部分这些方法都是依赖于 backbone 的。当采用不同 backbone 的时候,需要充分的手工调整超参数。
3). re-ID 本质上算是一种 retrieval task,但是大部分的 NAS 方法缺只是被设计用于 classification。由于 retrieval 和 classification 有不同的目标,现有的 NAS 算法无法直接用于 re-ID 的问题。
基于上述观察和分析, 作者设计了一种新的 Auto-reID 算法来解决上述三个问题。而这种方法的关键在于:design a new re-ID search space,这种搜索空间可以将身体结构化的信息作为可操作的 CNN 成分。另外,作者也将 retrieval loss 结合到搜索机制中,使得搜索的结果更加适合 re-ID 任务。那么,本文所提出的 re-ID search space 和 re-ID search algorithm 可以确保找到一个 efficient 和 effective 的网络结构,如图 1 所示:
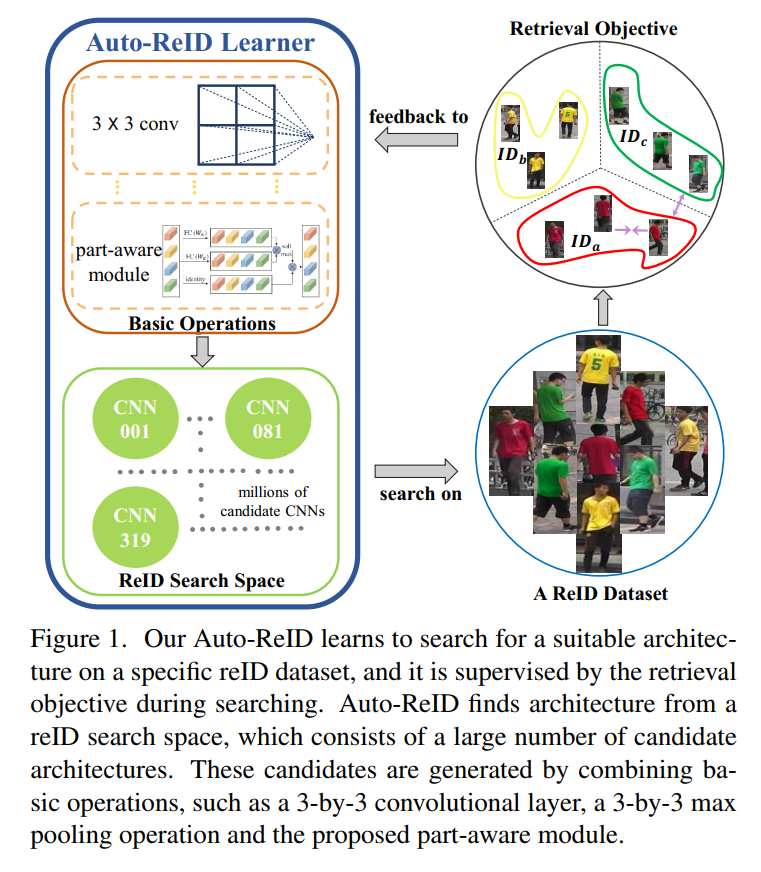
2. Methodology:
2.1 Preliminaries:
许多 NAS 的方法都是许多 neural cell 的堆叠,而一个 cell 包含多个 layers,将之前 cells 的输出作为输入,然后产生新的输出 tensor。作者也服从这种套路,来搜索适合的 re-ID 网络结构。
具体来说,一个 neural cell 可以看做是一个 directed acyclic graph (DAG),假设有 B 个 blocks。每一个 block 有如下三个步骤:
1). 将 2 tensors 作为输入;
2). 在输入 tensors 上分别采用 two operations;
3). 将这两个 tensors 进行 sum。
而所选择的操作,就是从一个候选操作集合 O 上选择。本文中,采用如下的 operations:
(1) 3×3 max pooling,
(2) 3×3 average pooling,
(3) 3×3 depth-wise separable convolution,
(4) 3×3 dilated convolution,
(5) zero operation (none),
(6) identity mapping.
第 c 个 cell 的 第 i 个 block 可以表达为如下的四元组:![]()
![]() 另外,第 c 个 cell 的 第 i 个 block 的输出是:
另外,第 c 个 cell 的 第 i 个 block 的输出是:
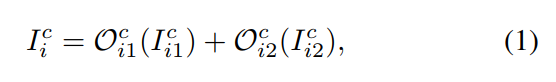
其中,I are selected from the candidate input tensors, which consists of output tensors from the last two neural cells and output tensors from the previous block in the current cell. 为了搜索公式 1 中的操作符 O 以及 I,我们将操作符选择的问题进行松弛,用 softmax 来对每一个 operation 进行打分:
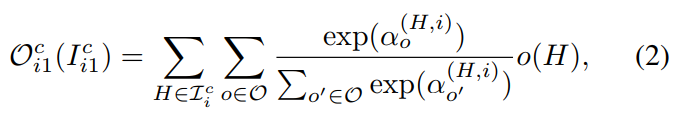
其中,$alpha$ 代表对于一个 neural cell 的拓扑结构,称为:architecture parameters。我们将所有 O 中的参数记为 w,称为 operation parameters,一个典型的可微分的 NAS 算法,联合的在 training set 上进行 w 的训练,在 validation set 上进行 $alpha$ 的训练。在训练之后,H 和 I 之间的强度(strength)定义为:

其中,带有最大强度的 H 被选择作为 I,做大权重的操作符,被选为 $O_{i1}^c$。上述常规的 NAS 搜索方法 DARTS 是被设计用于 classification task,所以作者考虑将该机制结合到 re-ID 任务中。
2.2 Re-ID Search Algorithm:
作者尝试将 the re-ID specific knowledge 结合到搜索算法中。从网络结构的角度来说,作者利用 ResNet 的 macro structure 作为 re-ID 的backbone,每一个 residual layer 被 neural cell 所替换。而这种 neural cell 的结构,就是搜索出来的。

上述过程,简述了特征变换的过程。另外一个重要的问题是损失函数的定义,在 classification task 中 cross-entropy loss function 当然是首选,那么问题是 re-ID task 并非简单的分类问题。所以,作者在这里做了些许的改变,引入了 triplet loss 来进一步改善网络的训练过程。联合的损失函数表示如下:
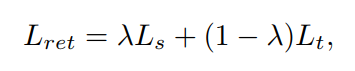
其中,交叉熵损失函数 和 三元组损失函数的定义分别如下所示:
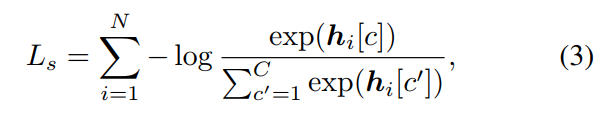
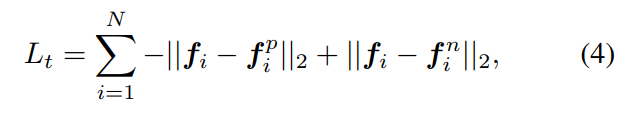
上述就是损失函数的定义。算法流程如下所示:

2.3. ReID Search Space with Part-aware Module:
该小节主要是介绍作者设计的 part-aware module 来改善搜索空间的问题。作者也给出了一个 pipeline,来说明该过程:
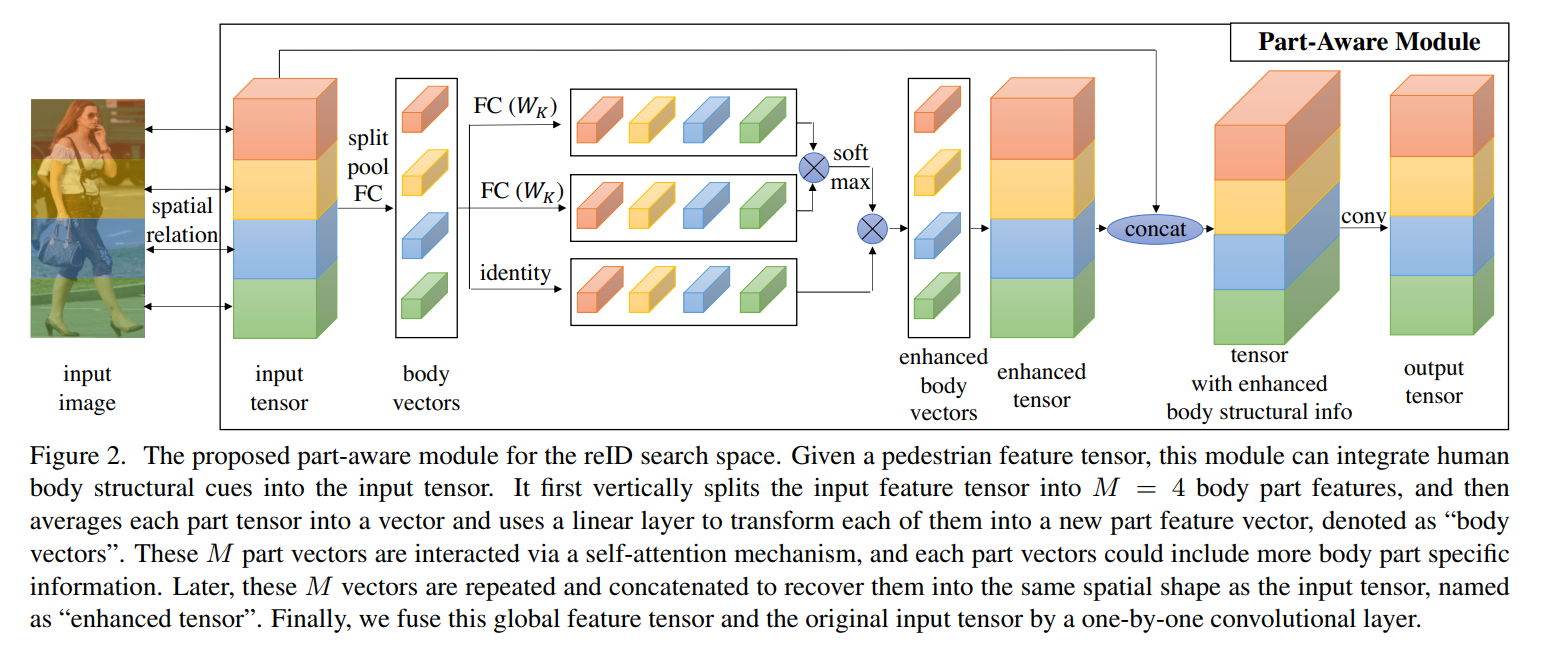

具体的操作其实就是对 feature map 进行 part 的划分,然后计算其 self-attention,进行 attend。然后将 attend 之后的 local feature,分别与原始的 input feature 进行组合,然后用 1*1 的卷积操作进行降维处理,得到 output tensor。这么做的优势是什么呢?作者提到本文所设计的 part-aware module 可以捕获有用的 body part cue,并将这种结构化信息融合到 input feature 中。本文所提出的 part-aware module 的参数大小和数量 和 3*3 的depth-wise separable convlution 是相当的。所以,并不会显著的影响 NAS 的效率。
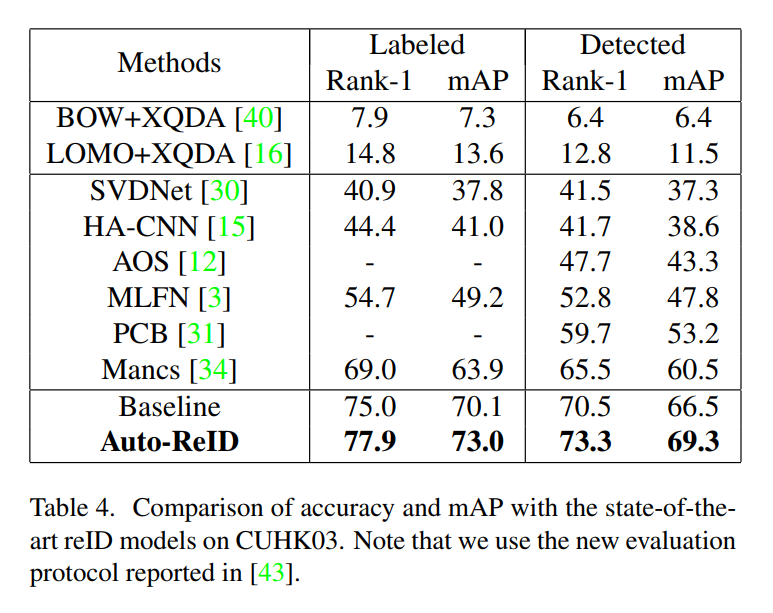
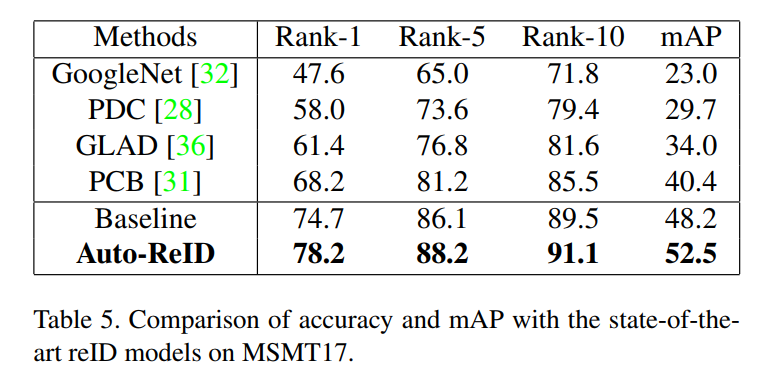
3. Experimental Results:


4. Future Works:
在未来工作中,作者提到本文是首次进行 re-ID 网络结构的设计,仅考虑到了一种可能的特定模块。更多的关于 re-ID 的特定领域知识,都可以考虑进来。以得到更好的 re-ID 的性能。
==