CPT: COLORFUL PROMPT TUNING FOR PRE-TRAINED VISION-LANGUAGE MODELS
2021-09-28 11:41:22
Paper: https://arxiv.org/pdf/2109.11797.pdf
Other blog: https://zhuanlan.zhihu.com/p/414800147
Code: not available yet
1. Background and Motivation:
目前主流的 vision-language 任务,基本上服从 pre-train 和 fine-tuning 的框架。先在大型 vision-language 数据对上进行预训练学习,然后在下游任务上进行特征的微调,以取得更好的下游任务结果。这种范式极大地推动了 vision-language 领域的发展,很多模型都取得了更好的精度。但是这种范式的主要问题是,pre-train 和 下游任务的学习 显得有点分离了。为了将这两个阶段更加紧密的结合在一起,最近 prompt 技术开始引起大家的关注。如何将下游任务更加直接的结合到 pre-train 中,以得到更好的结果,是当前研究的重点。
本文也在尝试解决这个问题,并在 image grounding 这个任务上进行了验证,提出利用 color 来作为中间桥梁,完成 colorful prompt tuning。如下图所示:
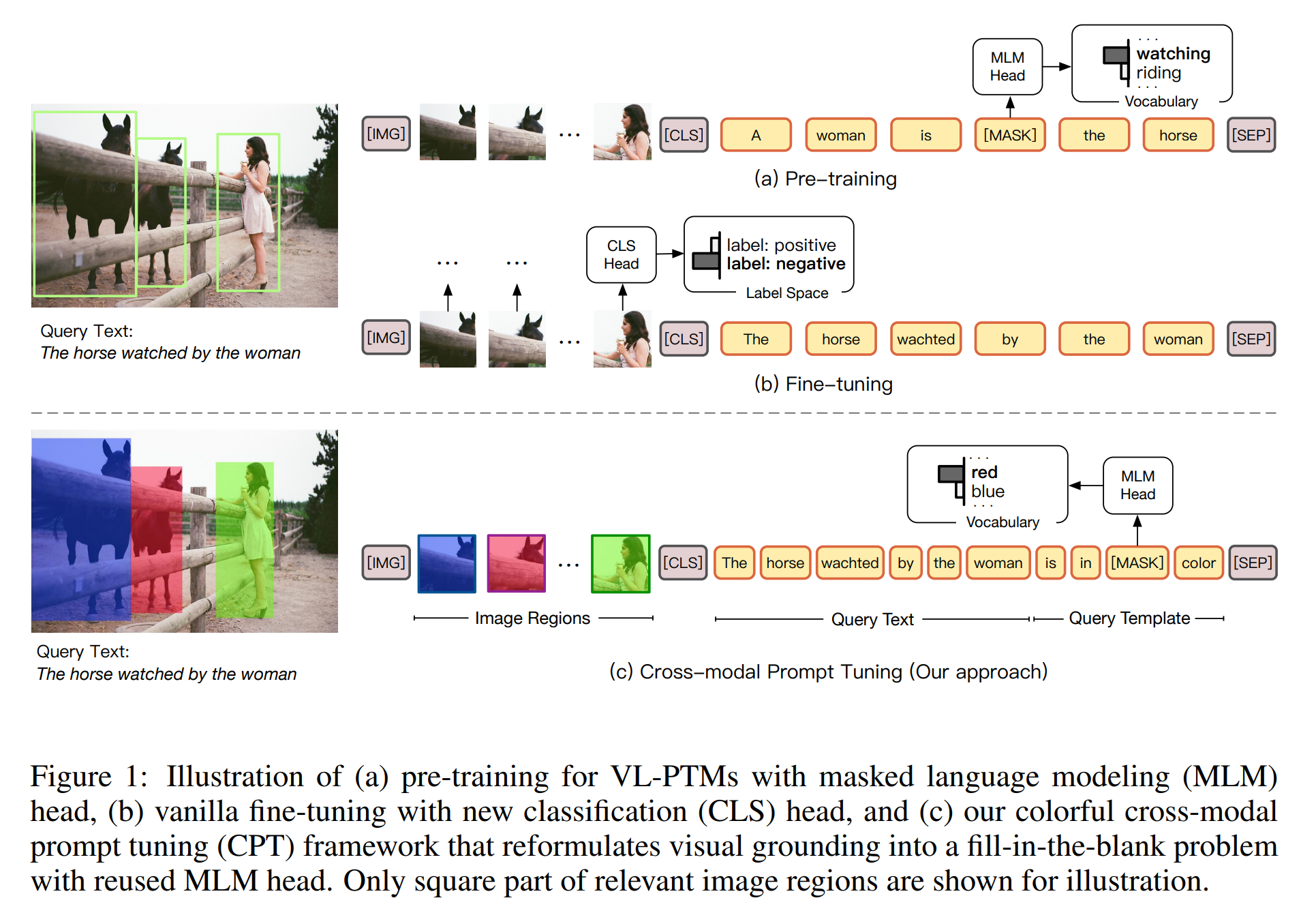
作者认为在预训练阶段,大部分预训练模型均基于 masked language modelling objective, 尝试从跨模态内容上恢复出 masked tokens。然而,在微调阶段,下游任务通常识别未掩膜符号表达为语义标签。这通常会引入特定任务的参数。并进一步的阻碍了大模型到下游任务的迁移。从而在下游任务,需要大规模有标签数据的来仿真 visual grounding 的能力。在本文中,受到最近 pre-trained model 的启发,作者设计了一种 Cross-modal Prompt Tuning,CPT,也称为 Colorful Prompt Tuning,一种新的范式进行 vision-language 预训练模型的微调。关键点就在于:添加 color-based co-referential markers in both image and text,visual grounding 可以重新定义为“完形填空”问题,最大程度上缩小 pre-training 和 fine-tuning 之间的差异。如图1 所示,为了从 image data 中得到 natural language expressions,CPT 包含两种成分:
1. a visual sub-prompt: uniquely marks image regions with color blocks;
2. a textual sub-prompt: puts the query text into a color-based query template;
目标图像区域的直接 grounding 可以通过从 the masked token in the query template 中恢复对应的 color text 来实现。
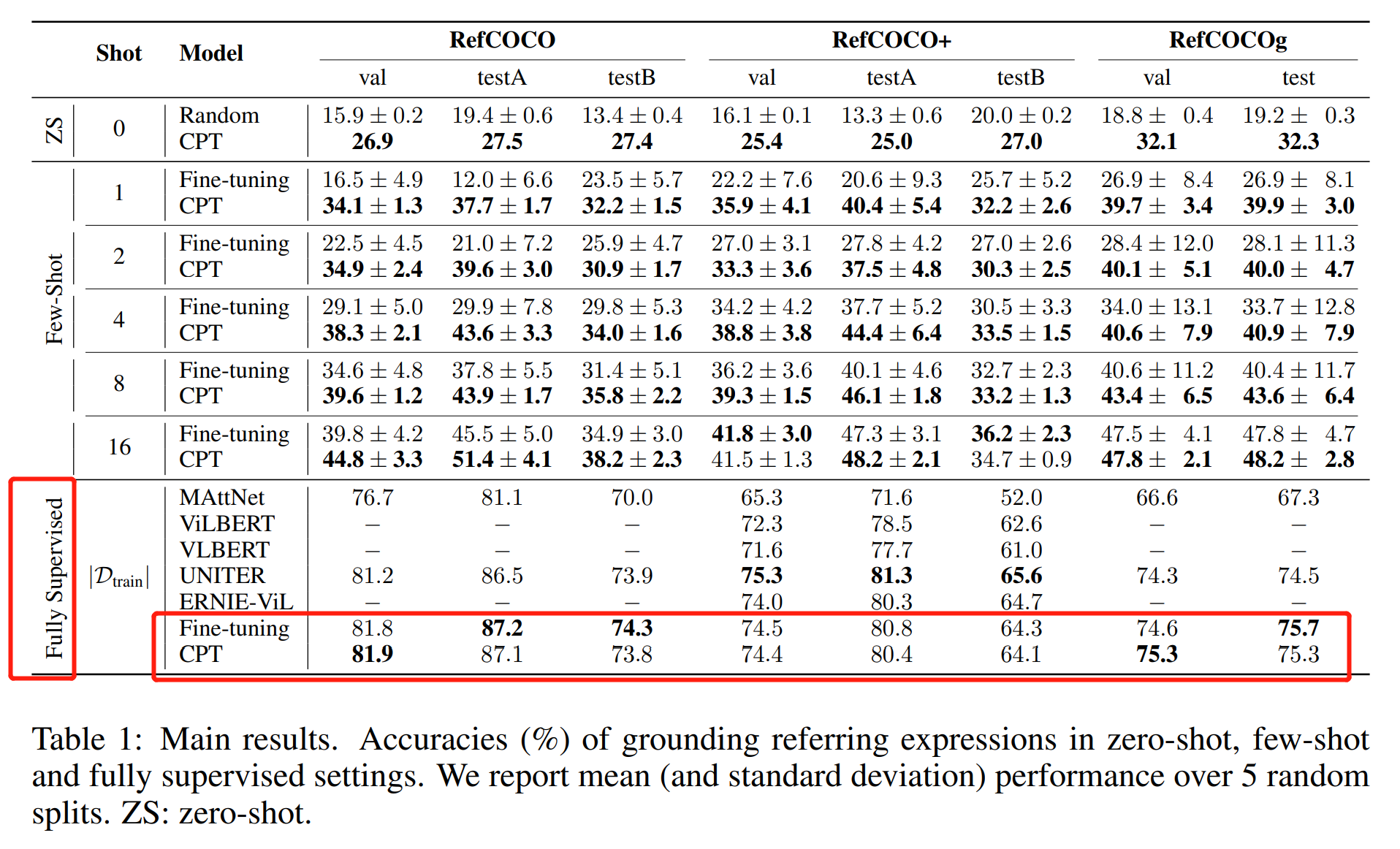
通过弥补该鸿沟,本文所提出的 prompt tuning 方法可以确保较强的 few-shot 甚至 zero-shot visual grounding 能力。实验结果表明,该方法可以超过 fine-tuning 技术,并带来 17.3% 的精度提升。CPT 的主要创新在于:首次提出一种新的跨膜他 prompt tuning 技术,并在 zero- 和 few-shot visual grounding 上均获得了巨大的提升。
2. Approach:
作者提到 visual grounding 的关键问题是建立细粒度的 image regions 和 textual expressions 的联系。所以,一个好的跨模态 prompt tuning framework 应该充分考虑到 co-referential signal,并且尽可能的减小 pre-training 和 tuning 之间的差异。为了达到该目的,作者设计了两个模块,可以直接通过填充掩膜符号来实现 query text 的定位。优势是,利用目标图像区域的颜色文本进行填充,其优化目标和 pre-training 是相同的。这样就实现了 pre-training 和 tuning 的一致。
2.1. Visual Sub-Prompt:
给定图像 I 及其区域候选 R ={v1, v2, ..., vn},visual sub-prompt 目的是利用自然视觉标记符进行独特的标记。有意思的是,将矩形框进行加颜色,一般仅用于可视化。受到该操作的启发,作者通过一组颜色集合 C,将图像区域和文本表示进行连接,每一种颜色 ci 定义为其视觉外观。然后,作者将每一个 region proposal vi 标记为一个独特的颜色进行 grounding,得到一组有颜色的 image proposals。作者通过实验发现,通过将物体进行涂颜色处理得到的区域,比用矩形框可以得到更好的结果,因为,有颜色的物体在现实世界中,更加普遍,例如:red shirt 以及 blue car。由于 visual sub-prompt 是添加到 raw image 中的,其并不会改变模型的参数或者结构。
2.2. Textual Sub-Prompt:
Textual Sub-prompt 目的引导模型建立 query text 和 已被标记颜色的 image regions 之间的联系。具体来说, the query text q 被模板 T(*) 转换为 完形填空问题:
T(q) = [CLS] q is in [MASK] color [SEP]
通过这种方式,大模型可以被引导用于决策那些区域更加适合填充掩膜的颜色:
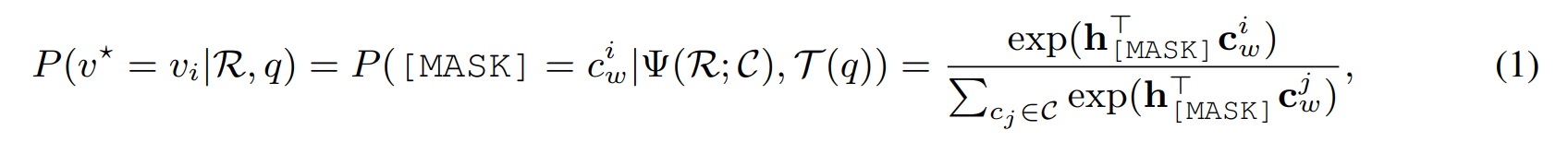
其中,v* 是 target region。
在设计该 color-based prompt 来连接 image 和 text 有如下两个挑战:
1). 如何决定 color set C 的配置;
2). 如何处理利用有限的 pre-trained colors 来处理众多 image regions;
Cross-Modal Prompt Search:
前人关于 textual prompt tuning 的工作表明:prompt configurations 对最终的结果有明显的影响。在本文中,作者尝试搜索 cross-modal prompt configurations,即 颜色集合 C。直观上来说,C 应该包含模型最敏感的颜色。为了得到一种颜色 ci,一种简单的方法是采用预训练文本中最常见的 color text,以及标准的 RGB颜色。然而,这种方法是次优的,因为,在决定 color text 的时候并没有考虑到 visual appearance,而实际图像中的视觉外观颜色通常不是标准的 RGB 颜色。
在本文中,作者首先识别所有 color text 的一个候选集合。对于 RGB 空间中的每一种颜色,作者将 pure color block 与一个 textual sub-prompt 进行组合,输入到模型中:
“ [CLS] a photo in [MASK] color. [SEP] ”.
然后,作者得到一个 decoding score,更大的 decoding score 表示 cv 和 cw 之间有更深的关系。作者将排行靠后的一些颜色移除了。最终,对于剩下的 color text,其视觉外观通过 arg max s(cv, cw) 来决定。作者的实验表明,通过这种方式得到的 color configurations 可以比 naive 方法得到明显优秀的结果。
Image Region Batching:在视觉定位中,region proposal 的个数通常超过 C (~10)。此外,作者观察到严重重叠的 color blocks 可能会严重的妨碍 visual grounding。所以,作者将图像划分为 batches,每一个 batch 包含一组适度重合的图像区域。用 visual sub-prompt 的方式对每一个 batch 进行标记。为了处理无 target region 的情况,作者引入了一组新的候选 text none 在 decoding 词典中,表示该 batch 中无 target region。
3. Experiments:

===