Learning Visual Question Answering by Bootstrapping Hard Attention
Google DeepMind ECCV-2018
Updated on 2020-03-11 14:58:12
Paper:https://arxiv.org/abs/1808.00300
Code: https://github.com/gnouhp/PyTorch-AdaHAN
1. Background and Motivation:
本文尝试仅仅用 hard attention 的方法来抠出最有用的 feature,进行 VQA 任务的学习。
Soft Attention:
Existing attention models are predominantly based on soft attention, in which all information is adaptively re-weighted before being aggregated. This can improve accuracy by isolating important information and avoiding interference from unimportant information.
Hard Attention:
It has the potential to improve accuracy and learning efficiency by focusing computation on the important parts of an image. But beyond this, it offers better computational efficiency because it only fully processes the information deemed most relevant. 但是,hard attention 有一个很致命的缺陷:由于图像中信息的选择是离散的,这导致基于梯度的学习方法,如 deep learning based methods,不可求导。然后,就无法利用 back-propagation 的方法进行区域的选择,来支持基于梯度的优化(because the choice of which information to process is discrete and thus non-differentiable, gradients cannot be backpropagated into the selection mechanism to support gradient-based optimization.)。当然有一些基于 Policy Gradient 的方法可以通过采样的方法,来处理梯度不可导的问题,但是这方面的研究,也仍然是非常的火热。

2. Approach Details:
如图 2 所示,作者用 CNN 模型来编码给定的图像,用 LSTM 来编码固定长度的单词。然后将句子的特征进行扩充,和图像的特征进行拼接。在进行特征融合后,作者在空间上进行 attention 处理,最终,作者利用 sum-pooling 或 relational modules 来进行特征聚合。该框架可以利用标准的逻辑回归损失进行端到端的训练。

2.1. Attention Mechanism:
作者介绍了 soft attention 的常规做法,然后引入本文的 hard attention 方法:
1). Soft Attention. 略
2). Hard Attention. 本文的主要贡献是提出一种新的 hard attention 机制。其可以在空间位置上产生 binary mask,只通过这部分的 feature 进行后续的处理。作者也将这种新的模型称为 hard attention network (HAN)。 关键的想法是利用每一个空间位置上激活的 L2-norm 来控制对应位置的相关性。L2-norm 和 relevance 之间的关系是训练的 CNN feature 的新兴属性,不需要额外的约束或者目标。有一个工作表明:in an ImageNet-pretrained representation of an image of a cat and a dog, the largest feature norms appear above the cat and dog face, even though the representation was trained purely for classification.
利用 $x_{ij}$ 和 q 分别表示在空间 ij 的 CNN cell,以及问题的特征表示。作者先将 q 和 x 映射到相同维度的特征空间:
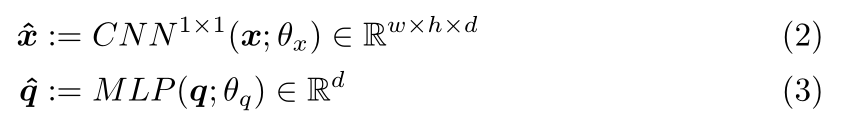
其中,$CNN^{1*1}$ 代表 1*1 卷积网络,MLP 代表多层感知机。然后将句子的 feature 进行扩充,再和图像的 feature map 进行元素级相加:
![]()
元素级相加可以使得每一个输入的维度不变。然后计算 presence vector p,这个指标衡量了给定问题后的示例的相关性:
![]()
其中,$||*||_2$ 代表 L2-norm。从 m 中选择 k entities 以进行进一步的处理,前 k 个示例的索引 l = [l1, l2, ... , lk] 被用于构成 ![]() 这些特征被传递到 decoder 模块中,然后通过选择的 feature 就可以进行梯度的传递。
这些特征被传递到 decoder 模块中,然后通过选择的 feature 就可以进行梯度的传递。
以上这些部分就是 HAN,作者还提出了 Adaptive-HAN 来解决自适应选择示例个数的问题,而不是固定的 k 个。这个主要是因为在 VQA 中,不同的问题所需要关注的区域是不一样的,而且大小也不一,所以,就需要这个自适应机制。这个想法的核心是:make the presence vector p "compete" against a threshold。然而,由于上述的 norm 未加约束,为了避免 trivial solutions,即:网络设置非常高的 presence vector,并且选择所有的示例,作者这里在 p 上添加了 softmax operator。作者将所有的示例都放进来进行选择,并且只选择超越设定阈值的那些示例:
![]()
虽然阈值可以通过超参数选择来得到,作者这里用的是 1/(w*h),其中 w 和 h 分别是输入向量 xij 的空间维度。跟流行的 soft-attention 机制相比,本文所提出的方法不需要额外的学习参数。HAN 需要一个超参数,adaHAN 不需要任何超参数。
2.2. Feature Aggregation:
Sum Pooling. 在利用 attention 之后,一种简单的减少 feature vector 的方法是:将其处理成固定长度的向量。在 soft-attention module 中,利用的是 attention weight vector w, 这样就可以直接进行将 权重向量 和 输入进行相乘,然后相加。给定 hard attention 选择的特征,一种类似的 pooling 操作可以是:
![]()
Non-local Pairwise Operator. 为了在 sum pooling 上进行改进,作者探索通过 non-local and pairwise computations 来进行推理的方法。这类 non-local pairwise methods 的一个重要方面是:the computation is quadratic(二次方) in the number of features, 所以,hard attention 可以明显的降低计算量。给定一些 embedding vectors xij,我们可以利用三种简单的线性映射来产生 a matrix of
queries, ![]() ,
,
keys, ![]() ,
,
and values, ![]() at each spatial location.
at each spatial location.
然后,对于每一个空间位置 ij,作者和所有其他位置比较了 the query qij with the keys,然后通过相似性将 values v 进行相加。具体来说,
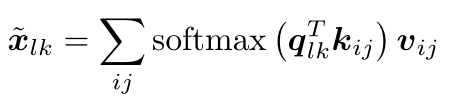
此处,softmax 操作是在所有的 ij 位置。输入的最终表达可以通过将所有的 ![]() 进行相加,即我们利用 sum-pooling 来达到这个目标。所以,该机制是计算不同 embeddings 之间的 non-local pairwise relations,与空间和时序上的近邻是独立的。The separation between keys,queries 和 values allows semantic information about each object to remain separated from the information that binds objects together across space.
进行相加,即我们利用 sum-pooling 来达到这个目标。所以,该机制是计算不同 embeddings 之间的 non-local pairwise relations,与空间和时序上的近邻是独立的。The separation between keys,queries 和 values allows semantic information about each object to remain separated from the information that binds objects together across space.
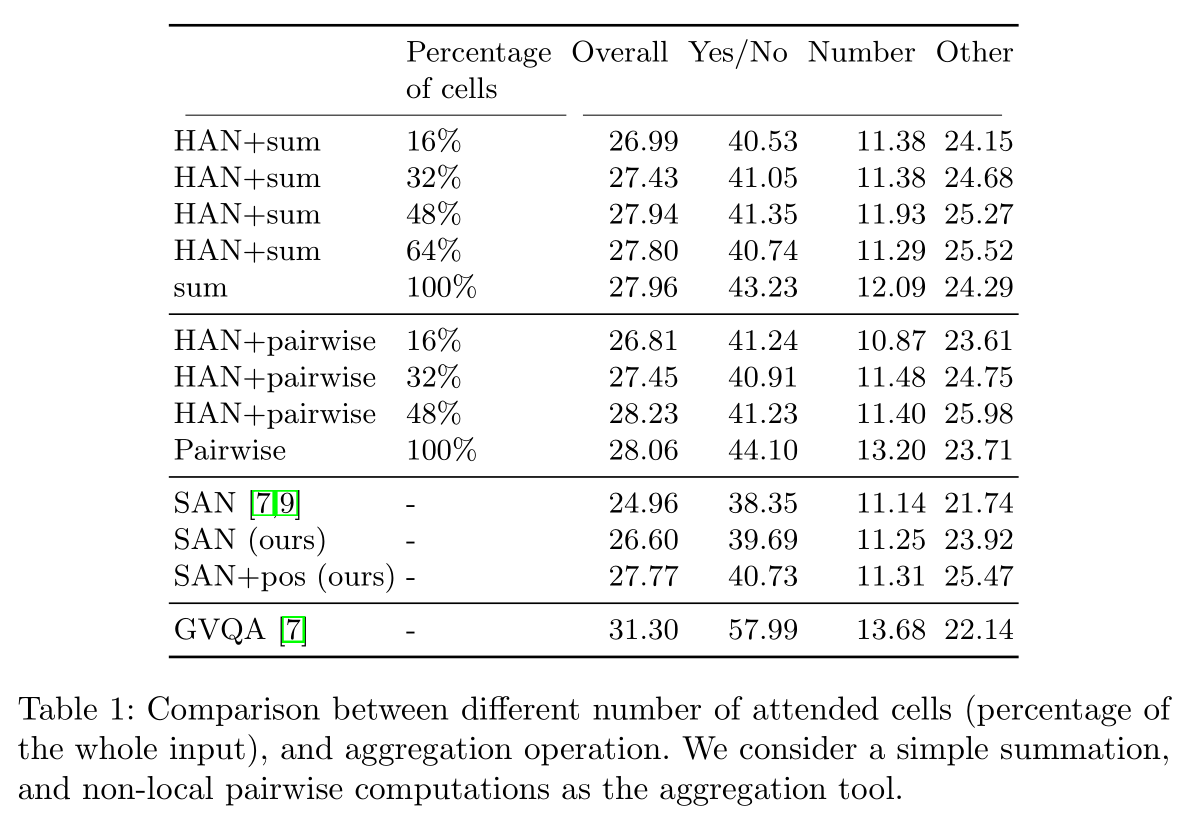
3. Experimental Results: