逻辑回归主要用于二分类问题中,对于一个样本数据集:{(x1,y1),(x2,y2),.....(xn,yn)},x表示样本特征,y表示样本类别(通常取值为0,1)。逻辑回归的目标是对算法训练完成之后,输入一个待分类样本,输出该样本的类别(0或者1)。因此引入数学上的sigmoid函数,该函数的形状为为's'型,在x正半轴x越大,函数值越接近1,在x轴负半轴,x越小,函数值越接近0.当x等于0时,函数输出等于0.5.sigmoid函数的这一性质刚好可以用来对数据进行分类,如果输出值为>0.5,则认为该数据样本归入‘1’类;如果输出值<0.5,则将该样本归入‘0’类。函数的表达式如下:

该函数的图像如下:
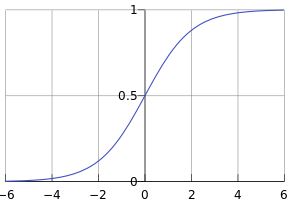
从图中可以看出,函数定义域为实数,值域在(0,1)之间。
假设样本数据中x具有N个特征,则 z = w0*x0+w1*x1+w2*x2+......+wn*xn.
将每个待测样本的x值带入上式,就可以求出该样本的对应的值,比较该值和0.5的大小,就可以确定该样本的类别。
那么问题就转化为,知道一批样本数据,求w0.......wn的参数。这也是机器学习训练的分类器的工作量最大的地方。求参数的过程具体可以使用梯度上升法。主要思想是利用迭代的方式求得回归参数。
求得回归参数后,就可以认为分类器训练完成,接着对训练器进行测试。在《机器学习实战》这本书中,作者详细的介绍了分类器的训练过程和测试过程,但是对相关的理论推导一笔带过,本文不再做详细介绍,后面专门写一篇数学推导的过程。
《机器学习实战》中的代码如下:
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Sat Aug 6 10:23:59 2016 4 5 @author: admin 6 """ 7 from numpy import * 8 def loadDataSet(): 9 dataMat = [];labelMat = [] 10 fr = open('testSet.txt') 11 for line in fr.readlines(): 12 lineArr = line.strip().split() 13 dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])]) 14 labelMat.append(int(lineArr[2])) 15 return dataMat,labelMat 16 17 def sigmoid(inX): 18 return 1.0/(1+exp(-inX)) 19 20 def gradAscent(dataMatIn,classLabels): 21 dataMatrix = mat(dataMatIn) 22 labelMat = mat(classLabels).transpose() 23 m,n = shape(dataMatrix) 24 alpha = 0.001 25 maxCycles = 500 26 weights = ones((n,1)) 27 for k in range(maxCycles): 28 h = sigmoid(dataMatrix*weights) 29 error = (labelMat - h) 30 weights = weights + alpha * dataMatrix.transpose()*error 31 return weights 32 33 def plotBestFit(wei): 34 import matplotlib.pyplot as plt 35 weights = wei.getA() 36 dataMat,labelMat = loadDataSet() 37 dataArr = array(dataMat) 38 n = shape(dataArr)[0] 39 xcord1 = [];ycord1 = [] 40 xcord2 = [];ycord2 = [] 41 for i in range(n): 42 if int(labelMat[i]) == 1: 43 xcord1.append(dataArr[i,1]);ycord1.append(dataArr[i,2]) 44 else: 45 xcord2.append(dataArr[i,1]);ycord2.append(dataArr[i,2]) 46 fig = plt.figure() 47 ax = fig.add_subplot(111) 48 ax.scatter(xcord1,ycord1, s=30, c = 'red',marker = 's') 49 ax.scatter(xcord2,ycord2, s=30, c = 'green') 50 x = arange(-3.0, 3.0, 0.1) 51 y = (-weights[0] - weights[1]*x)/weights[2] 52 ax.plot(x,y) 53 plt.xlabel('X1');plt.ylabel('X2') 54 plt.show() 55 56 def stocGradAscent0(dataMatrix,classLabels): 57 m,n = shape(dataMatrix) 58 alpha = 0.01 59 weights = ones(n) 60 for i in range(m): 61 h = sigmoid(sum(dataMatrix[i]*weights)) 62 error = classLabels[i] - h 63 weights = weights + alpha * error * dataMatrix[i] 64 return weights 65 66 def stocGradAscent1(dataMatrix,classLabels,numIter=150): 67 m,n = shape(dataMatrix) 68 weights = ones(n) 69 for j in range(numIter): 70 dataIndex = list(range(m)) 71 for i in range(m): 72 alpha = 4/(1.0+j+i) + 0.1 73 randIndex = int(random.uniform(0,len(dataIndex))) 74 h = sigmoid(sum(dataMatrix[randIndex]*weights)) 75 error = classLabels[randIndex] - h 76 weights = weights + alpha * error * dataMatrix[randIndex] 77 del(dataIndex[randIndex]) 78 return weights 79 80 def classifyVector(inX,weights): 81 prob = sigmoid(sum(inX*weights)) 82 if prob > 0.5 : 83 return 1.0 84 else: 85 return 0.0 86 87 def colicTest(): 88 frTrain = open('horseColicTraining.txt') 89 frTest = open('horseColicTest.txt') 90 trainingSet = [] 91 trainingLabels = [] 92 for line in frTrain.readlines(): 93 currLine = line.strip().split(' ') 94 lineArr = [] 95 for i in range(21): 96 lineArr.append(float(currLine[i])) 97 trainingSet.append(lineArr) 98 trainingLabels.append(float(currLine[21])) 99 trainWeights = stocGradAscent1(array(trainingSet),trainingLabels,500) 100 errorcount = 0;numTestVec = 0.0 101 for line in frTest.readlines(): 102 numTestVec += 1.0 103 currLine = line.strip().split(' ') 104 lineArr = [] 105 for i in range(21): 106 lineArr.append(float(currLine[i])) 107 if int(classifyVector(array(lineArr),trainWeights)) != int(currLine[21]): 108 errorcount += 1 109 errorRate = (float(errorcount)/numTestVec) 110 print('the error rate of the average error is :%f' %errorRate) 111 return errorRate 112 113 def multiTest(): 114 numTests = 10;errorSum = 0.0 115 for k in range(numTests): 116 errorSum += colicTest() 117 print('after %d iterations the average error rate is:%f'%(numTests,errorSum/float(numTests)))
使用书中的样本数据对算法进行训练,可以得到和书中相似的结果。