数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种
一Number(数字)
1.1 数字类型的创建
|
1
2
3
4
5
6
|
a=10b=ab=666 print(a)#10print(b)#666 |
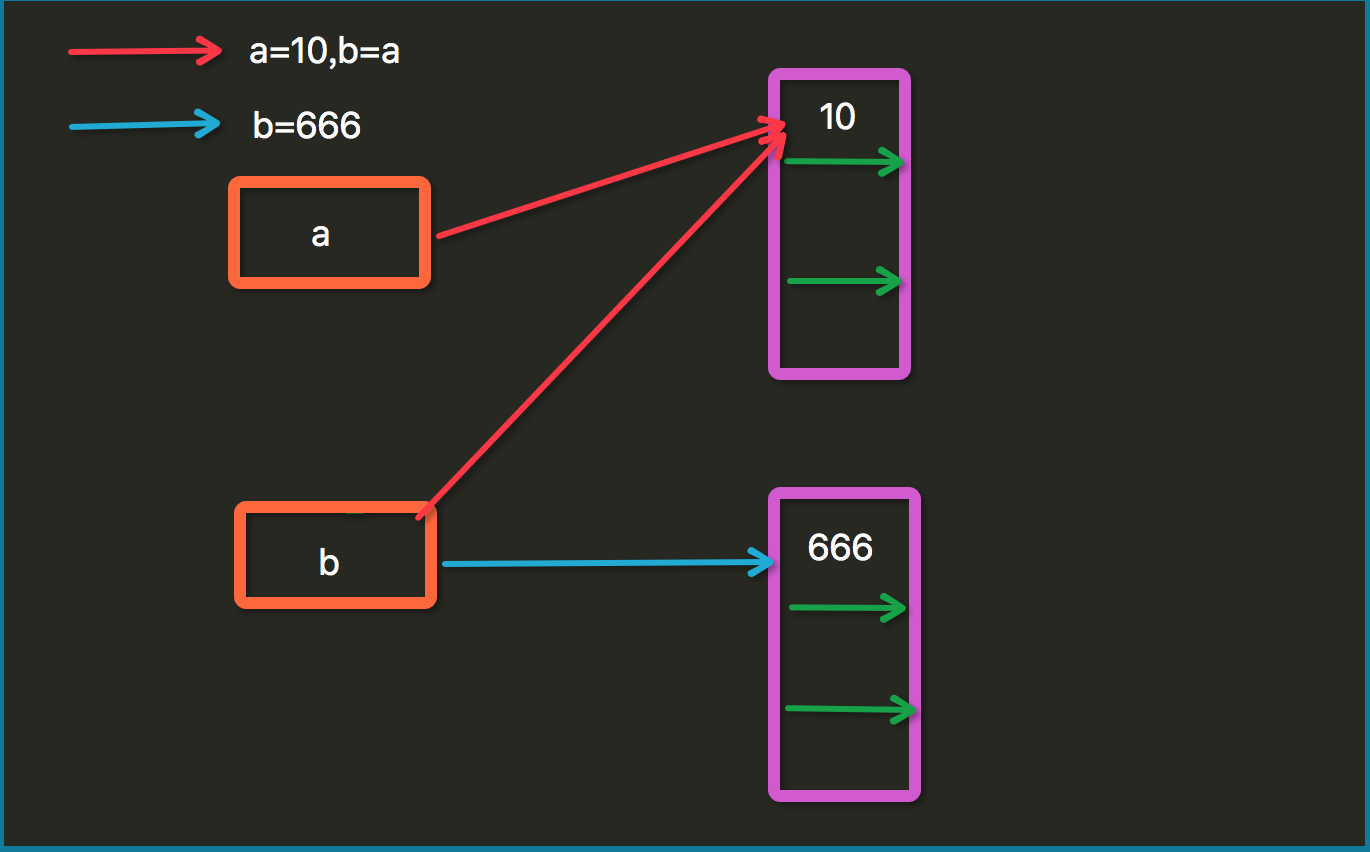
注意这里与C的不同:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#include <stdio.h>void main(void){ int a = 1; int b = a; printf ("a:adr:%p,val:%d,b:adr:%p,val:%d
",&a,a,&b,b); a = 3; printf ("a:adr:%p,val:%d,b:adr:%p,val:%d
",&a,a,&b,b); } //打印结果:topeet@ubuntu:~$ gcc test.ctopeet@ubuntu:~$ ./a.outa:adr:0x7fff343a069c,val:1b:adr:0x7fff343a0698,val:1a:adr:0x7fff343a069c,val:3b:adr:0x7fff343a0698,val:1 |
1.2 Number 类型转换
|
1
2
3
4
5
6
|
var1=3.14var2=5var3=int(var1)var4=float(var2) print(var3,var4) |

abs(x) 返回数字的绝对值,如abs(-10) 返回 10 # ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5 # cmp(x, y) 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 # exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 # fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0 # floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4 # log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 # log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0 # max(x1, x2,...) 返回给定参数的最大值,参数可以为序列。 # min(x1, x2,...) 返回给定参数的最小值,参数可以为序列。 # modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 # pow(x, y) x**y 运算后的值。 # round(x [,n]) 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 # sqrt(x) 返回数字x的平方根,数字可以为负数,返回类型为实数,如math.sqrt(4)返回 2+0j PY内置数学函数
二 字符串类型(string)
字符串是以单引号'或双引号"括起来的任意文本,比如'abc',"123"等等。
请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符。
2.1 创建字符串:
|
1
2
|
var1 = 'Hello World!'var2 = "Python luchuan" |
对应操作:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 1 * 重复输出字符串print('hello'*2) # 2 [] ,[:] 通过索引获取字符串中字符,这里和列表的切片操作是相同的,具体内容见列表print('helloworld'[2:]) # 3 in 成员运算符 - 如果字符串中包含给定的字符返回 Trueprint('el' in 'hello') # 4 % 格式字符串print('alex is a good teacher')print('%s is a good teacher'%'alex') # 5 + 字符串拼接a='123'b='abc'c='789'd1=a+b+cprint(d1)# +效率低,该用joind2=''.join([a,b,c])print(d2) |
python的内置方法
# string.capitalize() 把字符串的第一个字符大写
# string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
# string.count(str, beg=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数
# string.decode(encoding='UTF-8', errors='strict') 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除 非 errors 指 定 的 是 'ignore' 或 者'replace'
# string.encode(encoding='UTF-8', errors='strict') 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace'
# string.endswith(obj, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False.
# string.expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。
# string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1
# string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常.
# string.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
# string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
# string.isdecimal() 如果 string 只包含十进制数字则返回 True 否则返回 False.
# string.isdigit() 如果 string 只包含数字则返回 True 否则返回 False.
# string.islower() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
# string.isnumeric() 如果 string 中只包含数字字符,则返回 True,否则返回 False
# string.isspace() 如果 string 中只包含空格,则返回 True,否则返回 False.
# string.istitle() 如果 string 是标题化的(见 title())则返回 True,否则返回 False
# string.isupper() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
# string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
# string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
# string.lower() 转换 string 中所有大写字符为小写.
# string.lstrip() 截掉 string 左边的空格
# string.maketrans(intab, outtab]) maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
# max(str) 返回字符串 str 中最大的字母。
# min(str) 返回字符串 str 中最小的字母。
# string.partition(str) 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string.
# string.replace(str1, str2, num=string.count(str1)) 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次.
# string.rfind(str, beg=0,end=len(string) ) 类似于 find()函数,不过是从右边开始查找.
# string.rindex( str, beg=0,end=len(string)) 类似于 index(),不过是从右边开始.
# string.rjust(width) 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
# string.rpartition(str) 类似于 partition()函数,不过是从右边开始查找.
# string.rstrip() 删除 string 字符串末尾的空格.
# string.split(str="", num=string.count(str)) 以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串
# string.splitlines(num=string.count('
')) 按照行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行.
# string.startswith(obj, beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查.
# string.strip([obj]) 在 string 上执行 lstrip()和 rstrip()
# string.swapcase() 翻转 string 中的大小写
# string.title() 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle())
# string.translate(str, del="") 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中
# string.upper() 转换 string 中的小写字母为大写
字符串重点:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
stripcentercountfindlower 或 casefoldupperjoinsplitendwithstartwithreplaceindex |
三 字节类型(bytes)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# a=bytes('hello','utf8')# a=bytes('中国','utf8') a=bytes('中国','utf8')b=bytes('hello','gbk')#print(a) #b'xe4xb8xadxe5x9bxbd'print(ord('h')) #其十进制 unicode 值为: 104print(ord('中'))#其十进制 unicode 值为:20013 # h e l l o# 104 101 108 108 111 编码后结果:与ASCII表对应 # 中 国# xd6xd0 xb9xfa gbk编码后的字节结果#xe4 xb8 xad xe5 x9b xbd utf8编码后的字节结果# 228 184 173 229 155 189 a[:]切片取 c=a.decode('utf8')d=b.decode('gbk')#b=a.decode('gbk') :很明显报错 print(c) #中国print(d) #hello |
注意:对于 ASCII 字符串,因为无论哪种编码对应的结果都是一样的,所以可以直接使用 b'xxxx' 赋值创建 bytes 实例,但对于非 ASCII 编码的字符则不能通过这种方式创建 bytes 实例,需要指明编码方式。
|
1
2
3
4
5
6
|
b1=b'123'print(type(b1))# b2=b'中国' #报错# 所以得这样:b2=bytes('中国','utf8')print(b2)#b'xe4xb8xadxe5x9bxbd' |
四 布尔值
一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写)
|
1
2
3
4
|
print(True)print(4>2)print(bool([3,4]))print(True+1) |
与或非操作:
|
1
2
3
4
|
bool(1 and 0)bool(1 and 1)bool(1 or 0)bool(not 0) |
布尔值经常用在条件判断中:
|
1
2
3
4
5
|
age=18if age>18:#bool(age>18) print('old')else: print('young') |
五 List(列表)
OK,现在我们知道了字符串和整型两个数据类型了,那需求来了,我想把某个班所有的名字存起来,怎么办?
有同学说,不是学变量存储了吗,我就用变量存储呗,呵呵,不嫌累吗,同学,如班里有一百个人,你就得创建一百个变量啊,消耗大,效率低。
又有同学说,我用个大字符串不可以吗,没问题,你的确存起来了,但是,你对这个数据的操作(增删改查)将变得非常艰难,不是吗,我想知道张三的位置,你怎么办?
在这种需求下,编程语言有了一个重要的数据类型----列表(list)
什么是列表:
列表(list)是Python以及其他语言中最常用到的数据结构之一。Python使用使用中括号 [ ] 来解析列表。列表是可变的(mutable)——可以改变列表的内容。
对应操作:
1 查([])
|
1
2
3
4
5
6
7
8
9
10
|
names_class2=['张三','李四','王五','赵六'] # print(names_class2[2])# print(names_class2[0:3])# print(names_class2[0:7])# print(names_class2[-1])# print(names_class2[2:3])# print(names_class2[0:3:1])# print(names_class2[3:0:-1])# print(names_class2[:]) |
2 增(append,insert)
insert 方法用于将对象插入到列表中,而append方法则用于在列表末尾追加新的对象
|
1
2
3
|
names_class2.append('alex')names_class2.insert(2,'alvin')print(names_class2) |
3 改(重新赋值)
|
1
2
3
4
5
|
names_class2=['张三','李四','王五','赵六'] names_class2[3]='赵七'names_class2[0:2]=['wusir','alvin']print(names_class2) |
4 删(remove,del,pop)
|
1
2
3
4
|
names_class2.remove('alex')del names_class2[0]del names_class2names_class2.pop()#注意,pop是有一个返回值的 |
5 其他操作
5.1 count
count 方法统计某个元素在列表中出现的次数:
|
1
2
3
4
5
6
7
|
>>> ['to', 'be', 'or', 'not', 'to', 'be'].count('to')2>>> x = [[1,2], 1, 1, [2, 1, [1, 2]]]>>> x.count(1)2>>> x.count([1,2])1 |
5.2 extend
extend 方法可以在列表的末尾一次性追加另一个序列中的多个值。
|
1
2
3
4
5
|
>>> a = [1, 2, 3]>>> b = [4, 5, 6]>>> a.extend(b)>>> a[1, 2, 3, 4, 5, 6] |
extend 方法修改了被扩展的列表,而原始的连接操作(+)则不然,它会返回一个全新的列表。
|
1
2
3
4
5
6
7
8
9
10
|
>>> a = [1, 2, 3]>>> b = [4, 5, 6]>>> a.extend(b)>>> a[1, 2, 3, 4, 5, 6]>>>>>> a + b[1, 2, 3, 4, 5, 6, 4, 5, 6]>>> a[1, 2, 3, 4, 5, 6] |
5.3 index
index 方法用于从列表中找出某个值第一个匹配项的索引位置:
|
1
|
names_class2.index('李四') |
5.4 reverse
reverse 方法将列表中的元素反向存放。
|
1
2
|
names_class2.reverse()print(names_class2) |
5.5 sort
sort 方法用于在原位置对列表进行排序。
|
1
2
|
x = [4, 6, 2, 1, 7, 9]x.sort()#x.sort(reverse=True) |
5.6 深浅拷贝
现在,大家先不要理会什么是深浅拷贝,听我说,对于一个列表,我想复制一份怎么办呢?
肯定会有同学说,重新赋值呗:
|
1
2
|
names_class1=['张三','李四','王五','赵六']names_class1_copy=['张三','李四','王五','赵六'] |
这是两块独立的内存空间
这也没问题,还是那句话,如果列表内容做够大,你真的可以要每一个元素都重新写一遍吗?当然不啦,所以列表里为我们内置了copy方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
names_class1=['张三','李四','王五','赵六',[1,2,3]]names_class1_copy=names_class1.copy() names_class1[0]='zhangsan'print(names_class1)print(names_class1_copy) ############names_class1[4][2]=5print(names_class1)print(names_class1_copy) #问题来了,为什么names_class1_copy,从这一点我们可以断定,这两个变量并不是完全独立的,那他们的关系是什么呢?为什么有的改变,有的不改变呢? |
这里就涉及到我们要讲的深浅拷贝了:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#不可变数据类型:数字,字符串,元组 可变类型:列表,字典 # l=[2,2,3]# print(id(l))# l[0]=5# print(id(l)) # 当你对可变类型进行修改时,比如这个列表对象l,它的内存地址不会变化,注意是这个列表对象l,不是它里面的元素# # this is the most important## s='alex'# print(id(s)) #像字符串,列表,数字这些不可变数据类型,,是不能修改的,比如我想要一个'Alex'的字符串,只能重新创建一个'Alex'的对象,然后让指针只想这个新对象## s[0]='e' #报错# print(id(s)) #重点:浅拷贝a=[[1,2],3,4]b=a[:]#b=a.copy() print(a,b)print(id(a),id(b))print('*************')print('a[0]:',id(a[0]),'b[0]:',id(b[0]))print('a[0][0]:',id(a[0][0]),'b[0][0]:',id(b[0][0]))print('a[0][1]:',id(a[0][1]),'b[0][1]:',id(b[0][1]))print('a[1]:',id(a[1]),'b[1]:',id(b[1]))print('a[2]:',id(a[2]),'b[2]:',id(b[2])) print('___________________________________________')b[0][0]=8 print(a,b)print(id(a),id(b))print('*************')print('a[0]:',id(a[0]),'b[0]:',id(b[0]))print('a[0][0]:',id(a[0][0]),'b[0][0]:',id(b[0][0]))print('a[0][1]:',id(a[0][1]),'b[0][1]:',id(b[0][1]))print('a[1]:',id(a[1]),'b[1]:',id(b[1]))print('a[2]:',id(a[2]),'b[2]:',id(b[2]))<br><br><br>#outcome |
# [[1, 2], 3, 4] [[1, 2], 3, 4]
# 4331943624 4331943752
# *************
# a[0]: 4331611144 b[0]: 4331611144
# a[0][0]: 4297375104 b[0][0]: 4297375104
# a[0][1]: 4297375136 b[0][1]: 4297375136
# a[1]: 4297375168 b[1]: 4297375168
# a[2]: 4297375200 b[2]: 4297375200
# ___________________________________________
# [[8, 2], 3, 4] [[8, 2], 3, 4]
# 4331943624 4331943752
# *************
# a[0]: 4331611144 b[0]: 4331611144
# a[0][0]: 4297375328 b[0][0]: 4297375328
# a[0][1]: 4297375136 b[0][1]: 4297375136
# a[1]: 4297375168 b[1]: 4297375168
# a[2]: 4297375200 b[2]: 4297375200
那么怎么解释这样的一个结果呢?

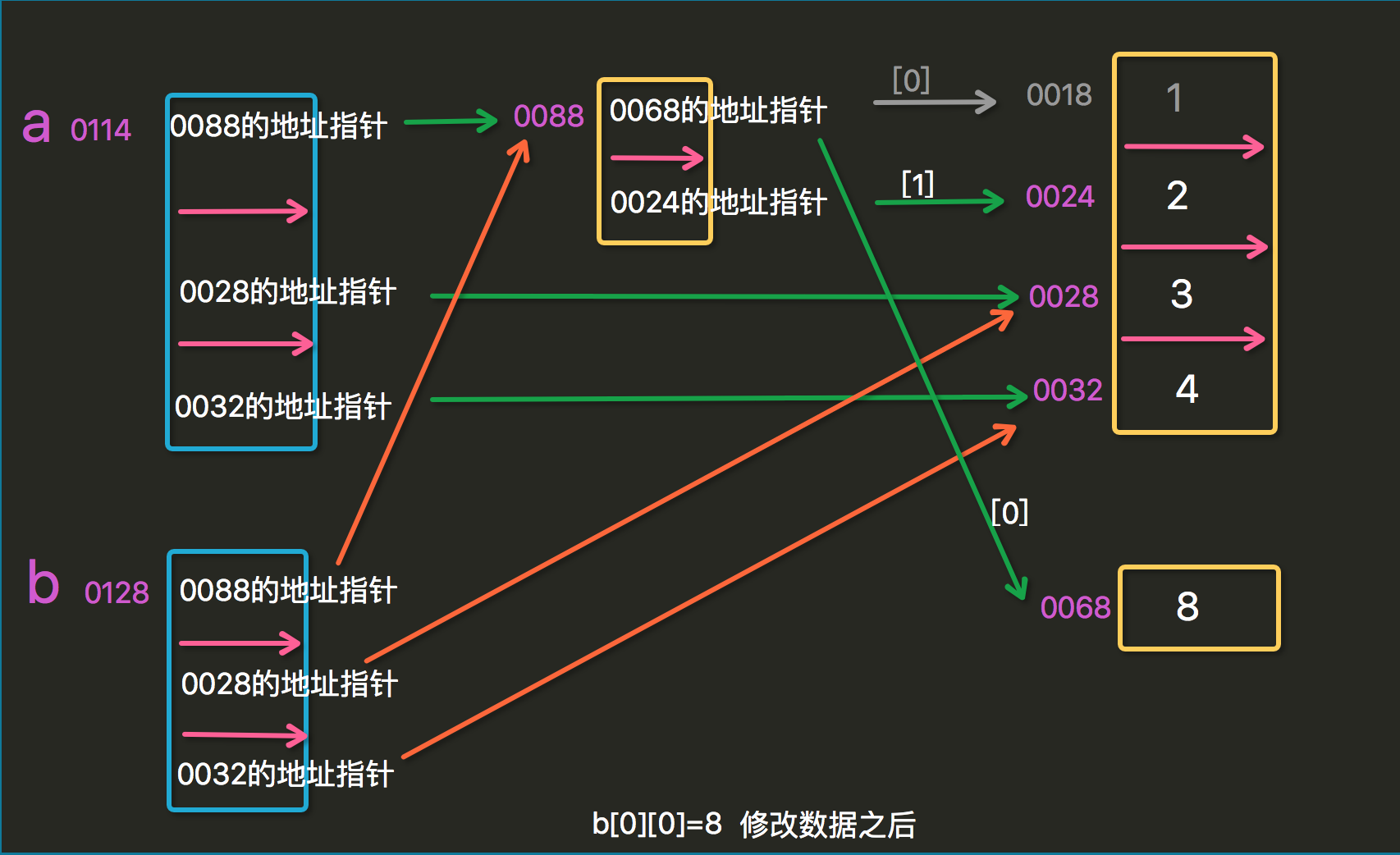
再不懂,俺就没办法啦...
列表补充:
|
1
|
b,*c=[1,2,3,4,5] |
六 tuple(元组)
元组被称为只读列表,即数据可以被查询,但不能被修改,所以,列表的切片操作同样适用于元组。
元组写在小括号(())里,元素之间用逗号隔开。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
|
1
2
|
tup1 = () # 空元组tup2 = (20,) # 一个元素,需要在元素后添加逗号 |
作用:
1 对于一些数据我们不想被修改,可以使用元组;
2 另外,元组的意义还在于,元组可以在映射(和集合的成员)中当作键使用——而列表则不行;元组作为很多内建函数和方法的返回值存在。
字典
# product_list=[
# ('book',100),
# ('Mac Pro',9000),
# ('watch',500),
# ('coffee',30),
# ('Python',106),]
#
# saving=input('input your saving:')
# shopping_car=[]
#
# if saving.isdigit():
# saving=int(saving)
# while True:
# for i,v in enumerate(product_list):
# print(i,v)
# user_choice=input('选择购买商品编号[退出:q]:')
#
# if user_choice.isdigit():
# user_choice=int(user_choice)
# if user_choice<len(product_list) and user_choice>=0:
# product_item=product_list[user_choice]
# if product_item[1]<saving:
# saving-=product_item[1]
# shopping_car.append(product_item)
# print('您当前的余额为%s'%saving)
# else:
# print('编号错误')
# elif user_choice=='q':
# print('---------您已经购买如下商品-----------')
# for i in shopping_car:
# print(i)
# print('您的余额为%s'%saving)
# break
#
# else:
# print('invalid choice')
购物车实例
七 Dictionary(字典)
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
字典(dictionary)是除列表意外python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
创建字典:
|
1
2
3
4
|
dic1={'name':'alex','age':36,'sex':'male'}dic2=dict((('name','alex'),))print(dic1)print(dic2) |
对应操作:
1 增
|
1
2
3
4
5
6
7
8
9
10
|
dic3={} dic3['name']='alex'dic3['age']=18print(dic3)#{'name': 'alex', 'age': 18} a=dic3.setdefault('name','yuan')b=dic3.setdefault('ages',22)print(a,b)print(dic3) |
2 查
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
dic3={'name': 'alex', 'age': 18} # print(dic3['name'])# print(dic3['names'])## print(dic3.get('age',False))# print(dic3.get('ages',False)) print(dic3.items())print(dic3.keys())print(dic3.values()) print('name' in dic3)# py2: dic3.has_key('name')print(list(dic3.values())) |
3 改
|
1
2
3
4
5
6
|
dic3={'name': 'alex', 'age': 18} dic3['name']='alvin'dic4={'sex':'male','hobby':'girl','age':36}dic3.update(dic4)print(dic3) |
4 删
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
dic4={'name': 'alex', 'age': 18,'class':1} # dic4.clear()# print(dic4)del dic4['name']print(dic4) a=dic4.popitem()print(a,dic4) # print(dic4.pop('age'))# print(dic4) # del dic4# print(dic4) |
5 其他操作以及涉及到的方法
5.1 dict.fromkeys
|
1
2
3
4
5
6
7
8
9
10
|
d1=dict.fromkeys(['host1','host2','host3'],'Mac')print(d1) d1['host1']='xiaomi'print(d1)#######d2=dict.fromkeys(['host1','host2','host3'],['Mac','huawei'])print(d2)d2['host1'][0]='xiaomi'print(d2) |
5.2 d.copy() 对字典 d 进行浅复制,返回一个和d有相同键值对的新字典
5.3 字典的嵌套
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来"
print(av_catalog["大陆"]["1024"])
#ouput
['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
5.4 sorted(dict) : 返回一个有序的包含字典所有key的列表
|
1
2
|
dic={5:'555',2:'222',4:'444'}print(sorted(dic)) |
5.5 字典的遍历
|
1
2
3
4
5
6
7
8
9
|
dic5={'name': 'alex', 'age': 18} for i in dic5: print(i,dic5[i]) for items in dic5.items(): print(items)for keys,values in dic5.items(): print(keys,values) |
还用我们上面的例子,存取这个班学生的信息,我们如果通过字典来完成,那:
|
1
2
3
4
|
dic={'zhangsan':{'age':23,'sex':'male'}, '李四':{'age':33,'sex':'male'}, 'wangwu':{'age':27,'sex':'women'} } |
八 集合(set)
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
集合(set):把不同的元素组成一起形成集合,是python基本的数据类型。
集合元素(set elements):组成集合的成员(不可重复)
|
1
2
3
4
5
6
7
|
li=[1,2,'a','b']s =set(li)print(s) # {1, 2, 'a', 'b'} li2=[1,2,1,'a','a']s=set(li2)print(s) #{1, 2, 'a'} |
集合对象是一组无序排列的可哈希的值:集合成员可以做字典的键
|
1
2
3
|
li=[[1,2],'a','b']s =set(li) #TypeError: unhashable type: 'list'print(s) |
集合分类:可变集合、不可变集合
可变集合(set):可添加和删除元素,非可哈希的,不能用作字典的键,也不能做其他集合的元素
不可变集合(frozenset):与上面恰恰相反
|
1
2
3
|
li=[1,'a','b']s =set(li)dic={s:'123'} #TypeError: unhashable type: 'set' |
集合的相关操作
1、创建集合
由于集合没有自己的语法格式,只能通过集合的工厂方法set()和frozenset()创建
|
1
2
3
4
5
6
|
s1 = set('alvin') s2= frozenset('yuan') print(s1,type(s1)) #{'l', 'v', 'i', 'a', 'n'} <class 'set'>print(s2,type(s2)) #frozenset({'n', 'y', 'a', 'u'}) <class 'frozenset'> |
2、访问集合
由于集合本身是无序的,所以不能为集合创建索引或切片操作,只能循环遍历或使用in、not in来访问或判断集合元素。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
s1 = set('alvin')print('a' in s1)print('b' in s1)#s1[1] #TypeError: 'set' object does not support indexing for i in s1: print(i)# # True# False# v# n# l# i# a |
3、更新集合
可使用以下内建方法来更新:
s.add()
s.update()
s.remove()
注意只有可变集合才能更新:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# s1 = frozenset('alvin')# s1.add(0) #AttributeError: 'frozenset' object has no attribute 'add' s2=set('alvin')s2.add('mm')print(s2) #{'mm', 'l', 'n', 'a', 'i', 'v'} s2.update('HO')#添加多个元素print(s2) #{'mm', 'l', 'n', 'a', 'i', 'H', 'O', 'v'} s2.remove('l')print(s2) #{'mm', 'n', 'a', 'i', 'H', 'O', 'v'} |
del:删除集合本身
四、集合类型操作符
1 in ,not in
2 集合等价与不等价(==, !=)
3 子集、超集
|
1
2
3
4
|
s=set('alvinyuan')s1=set('alvin')print('v' in s)print(s1<s) |
4 联合(|)
联合(union)操作与集合的or操作其实等价的,联合符号有个等价的方法,union()。
|
1
2
3
4
5
|
s1=set('alvin')s2=set('yuan')s3=s1|s2print(s3) #{'a', 'l', 'i', 'n', 'y', 'v', 'u'}print(s1.union(s2)) #{'a', 'l', 'i', 'n', 'y', 'v', 'u'} |
5、交集(&)
与集合and等价,交集符号的等价方法是intersection()
|
1
2
3
4
5
6
|
s1=set('alvin')s2=set('yuan')s3=s1&s2print(s3) #{'n', 'a'} print(s1.intersection(s2)) #{'n', 'a'} |
6、差集(-)
等价方法是difference()
|
1
2
3
4
5
6
|
s1=set('alvin')s2=set('yuan')s3=s1-s2print(s3) #{'v', 'i', 'l'} print(s1.difference(s2)) #{'v', 'i', 'l'} |
7、对称差集(^)
对称差分是集合的XOR(‘异或’),取得的元素属于s1,s2但不同时属于s1和s2.其等价方法symmetric_difference()
|
1
2
3
4
5
6
|
s1=set('alvin')s2=set('yuan')s3=s1^s2print(s3) #{'l', 'v', 'y', 'u', 'i'} print(s1.symmetric_difference(s2)) #{'l', 'v', 'y', 'u', 'i'} |
应用
|
1
2
3
|
'''最简单的去重方式'''lis = [1,2,3,4,1,2,3,4]print list(set(lis)) #[1, 2, 3, 4] |
参考链接:http://www.cnblogs.com/yuanchenqi/articles/5782764.html