【项目名称】 知乎数据清洗整理和结论研究
【项目要求】
1、数据清洗 - 去除空值
要求:创建函数
2、问题1:知友全国地域分布情况,分析出TOP20
要求:
① 按照地域统计 知友数量、知友密度(知友数量/城市常住人口)
② 知友数量,知友密度,标准化处理,取值0-100,要求创建函数
③ 通过多系列柱状图,做图表可视化
提示:
① 标准化计算方法 = (X - Xmin) / (Xmax - Xmin)
② 可自行设置图表风格
3、问题2:知友全国地域分布情况,分析出TOP20
要求:
① 按照学校(教育经历字段) 统计粉丝数(‘关注者’)、关注人数(‘关注’),并筛选出粉丝数TOP20的学校,不要求创建函数
② 通过散点图 → 横坐标为关注人数,纵坐标为粉丝数,做图表可视化
③ 散点图中,标记出平均关注人数(x参考线),平均粉丝数(y参考线)
提示:
① 可自行设置图表风格
【项目实现】
import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rc('font', family='SimHei', size=13)
数据读取及探索
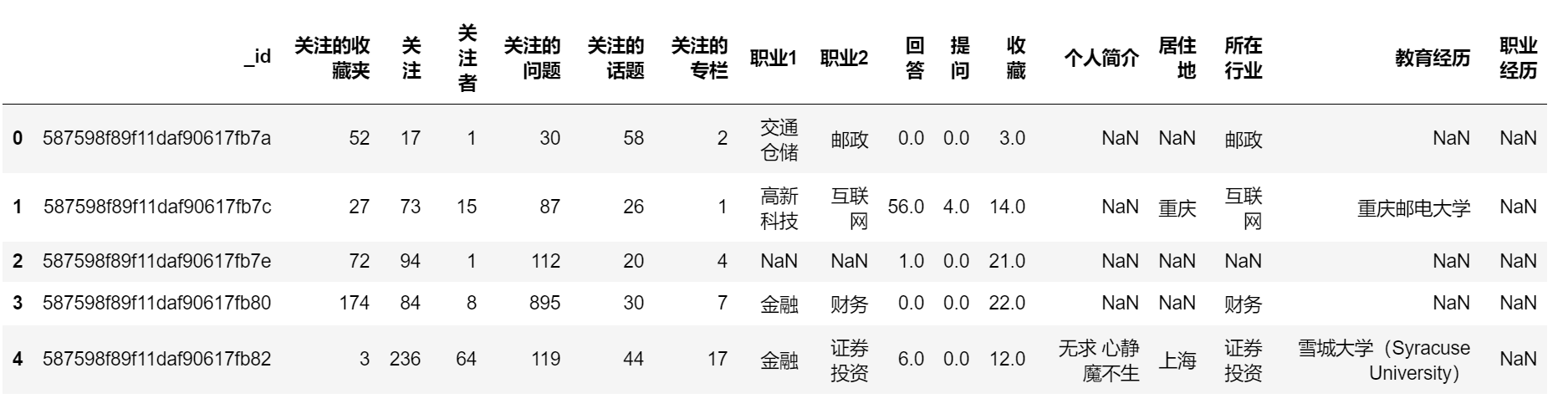
# 数据读取 data_zhihu = pd.read_csv("./知乎数据.csv",engine = 'python') data_zhihu.head()
数据清洗——去除空值
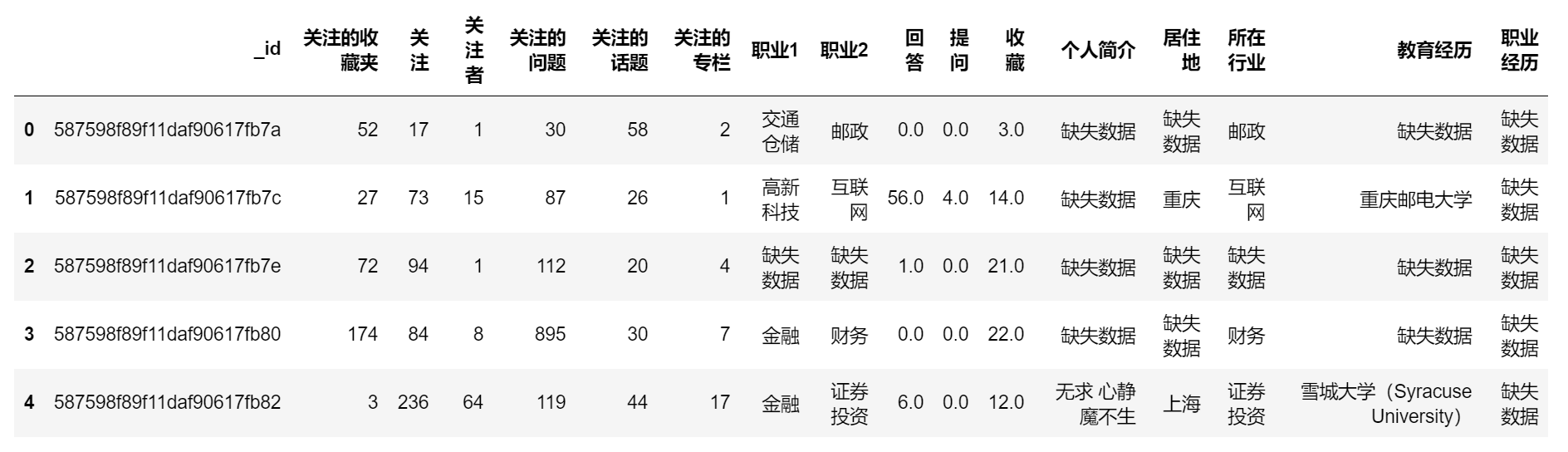
def data_cleaning(df): for col in df: if df[col].dtype == "object": df[col].fillna("缺失数据", inplace=True) else: df[col].fillna(0, inplace=True) data_cleaning(data_zhihu) data_zhihu.head()
# 问题1 知友全国地域分布情况,分析出TOP20
按照地域统计 知友数量、知友密度(知友数量/城市常住人口)
zhiyou_counts = data_zhihu["居住地"].value_counts().rename_axis('居住地').reset_index(name='知友数量') zhiyou_counts

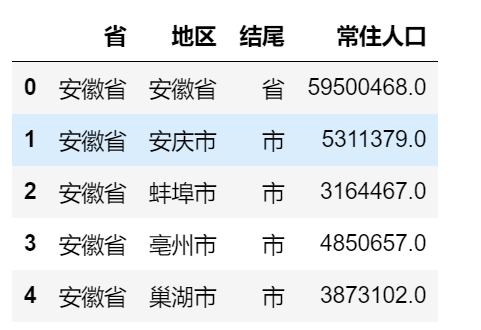
data_pop = pd.read_csv("./六普常住人口数据.csv", engine = 'python') data_pop.head()
data_pop["结尾"].unique()
array(['省', '市', nan], dtype=object
data_pop["地区"].replace(["省","市"], "", inplace=True, regex=True) data_pop.head()
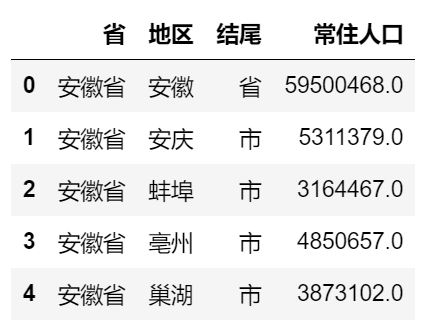
zhiyou = pd.merge(zhiyou_counts, data_pop, how="left", left_on="居住地", right_on="地区") zhiyou["知友密度"] = zhiyou['知友数量'] / zhiyou['常住人口'] zhiyou.head()
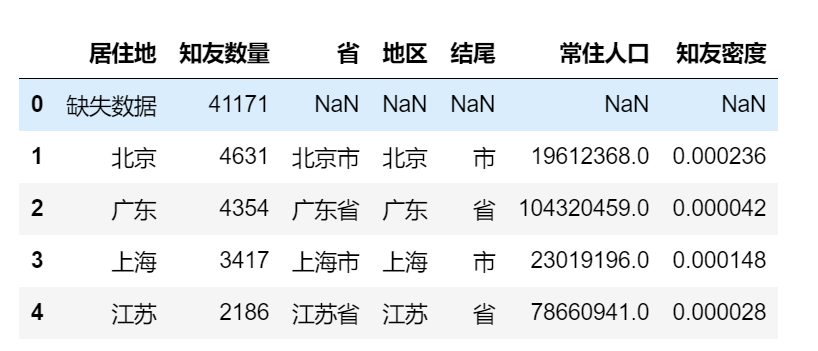
# 数据标准化
# 创建函数,结果返回标准化取值,新列列名
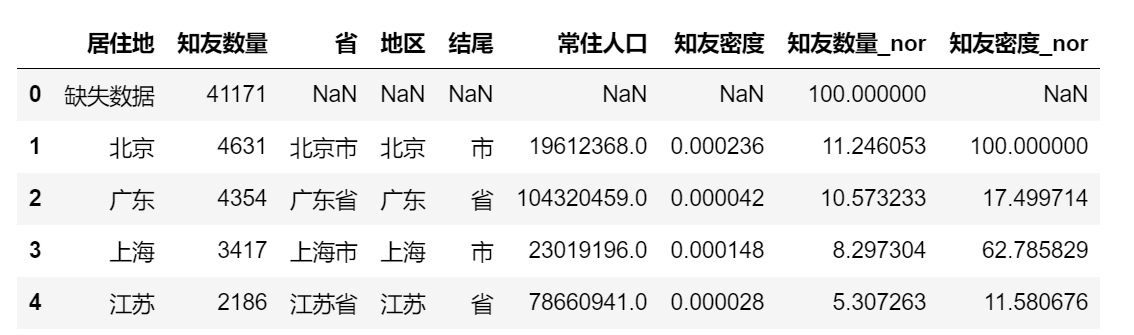
def data_nor(df, *cols): for col in cols: colname = col + '_nor' df[colname] = (df[col]-df[col].min())/(df[col].max()-df[col].min()) * 100
data_nor(zhiyou,"知友数量", "知友密度") zhiyou.head()
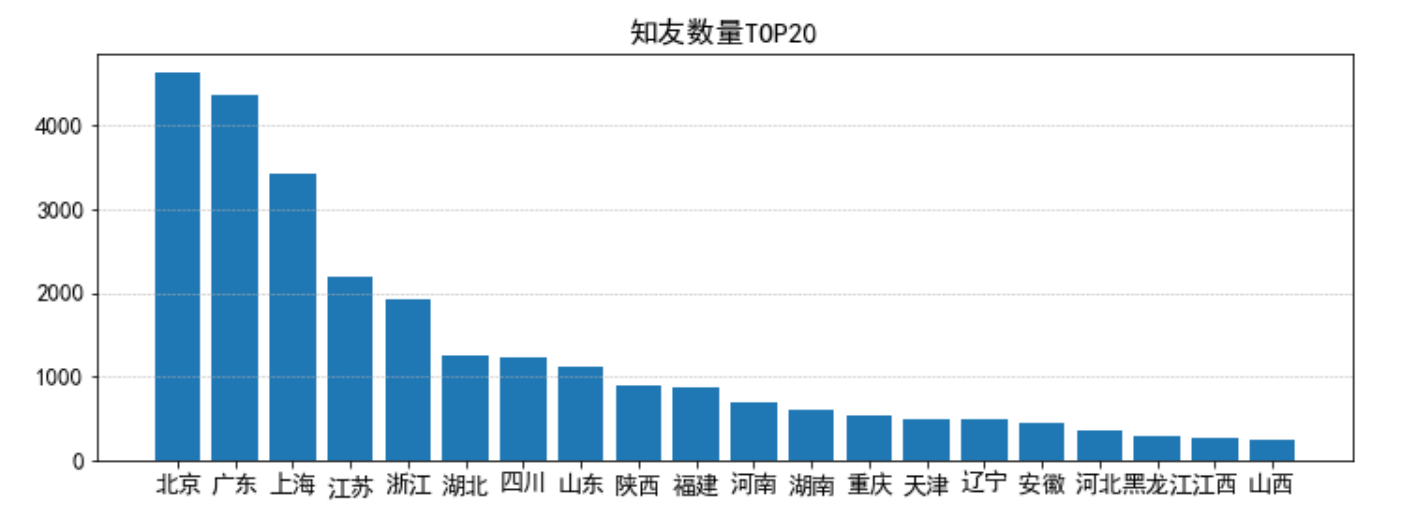
fig_counts = plt.figure(figsize=(12,4)) x_counts = [*range(20)] y_counts = zhiyou["知友数量"][1:21] plt.bar(x_counts, y_counts, tick_label=zhiyou["地区"][1:21]) plt.title("知友数量TOP20") plt.grid(True, linestyle = "--", linewidth = "0.5", axis = 'y')
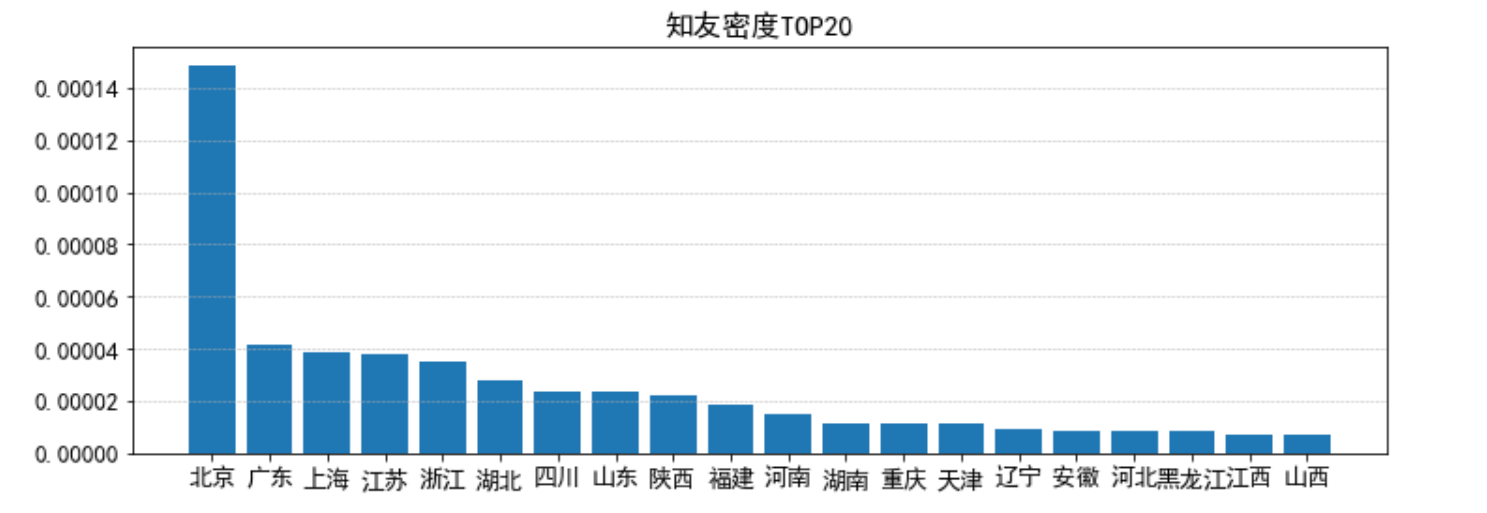
df = zhiyou.sort_values(by=["知友密度"], axis=0, ascending=False, inplace=False) fig_desity = plt.figure(figsize=(12,4)) x_desity = [*range(20)] y_desity = df["知友密度"][1:21] plt.bar(x_desity, y_desity, tick_label=zhiyou["地区"][1:21]) plt.title("知友密度TOP20") plt.grid(True, linestyle = "--", linewidth = "0.5", axis = 'y')
# 问题2 不同高校知友关注和被关注情况
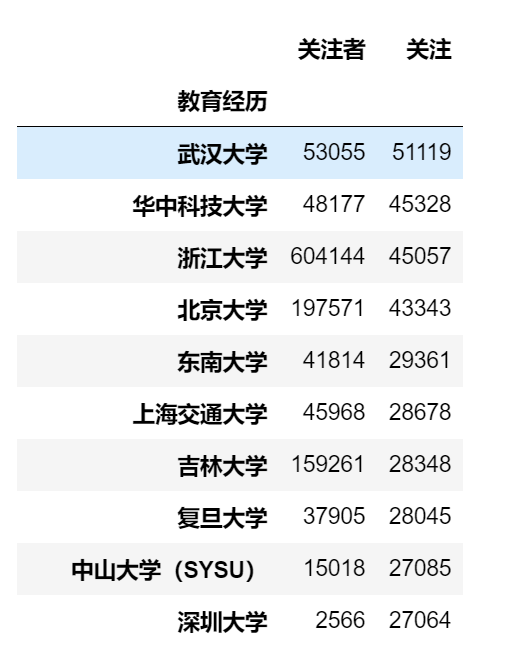
# 按照学校分组,统计粉丝数总人数的前20名 df_school = data_zhihu.groupby("教育经历")[["关注者","关注"]].sum().sort_values("关注",ascending=False)[:30] df_school # 删除无用字段 no_use = ["缺失数据","本科","大学"] df_school.drop(no_use, axis=0, inplace=True) df_school[:20]
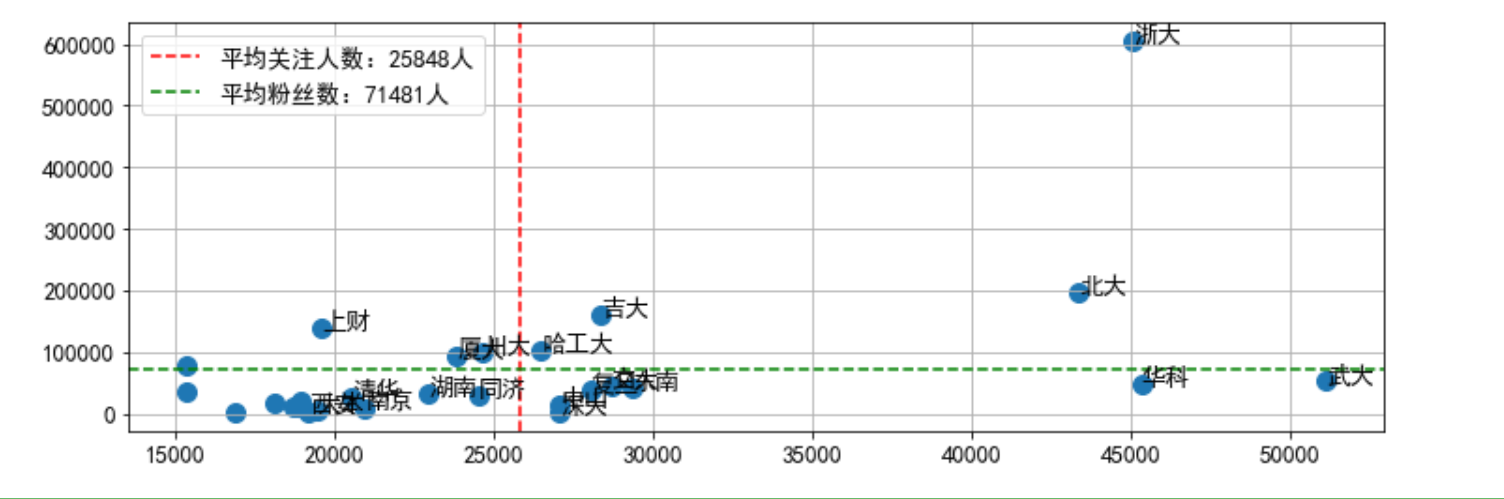
# 散点图 fig_school = plt.figure(figsize=(12,4)) x_school = df_school["关注"] y_school = df_school["关注者"] follow_mean = x_school.mean() fans_mean = y_school.mean() plt.scatter(x_school, y_school, s=100) plt.axvline(follow_mean,label="平均关注人数:%i人" % follow_mean,color='r',linestyle="--") # 添加x轴参考线 plt.axhline(fans_mean,label="平均粉丝数:%i人" % fans_mean,color='g',linestyle="--") # 添加y轴参考线 plt.legend() plt.grid() for i,txt in enumerate(df_school.index): plt.annotate(txt,(x_school[i],y_school[i]))

df_school_20 = df_school[:20] df_school_20 data_new = ["武大","华科","浙大","北大","东南","交大","吉大","复旦","中山","深大","哈工大","川大","同济","厦大","湖南","南京","清华","上财","大本","西安"] df_school_20["简称"] = data_new
fig_school = plt.figure(figsize=(12,4)) x_school = df_school["关注"] y_school = df_school["关注者"] follow_mean = x_school.mean() fans_mean = y_school.mean() plt.scatter(x_school, y_school, s=100) plt.axvline(follow_mean,label="平均关注人数:%i人" % follow_mean,color='r',linestyle="--") # 添加x轴参考线 plt.axhline(fans_mean,label="平均粉丝数:%i人" % fans_mean,color='g',linestyle="--") # 添加y轴参考线 plt.legend() plt.grid() for i,txt in enumerate(df_school_20["简称"]): plt.annotate(txt,(x_school[i],y_school[i]))