newrbe
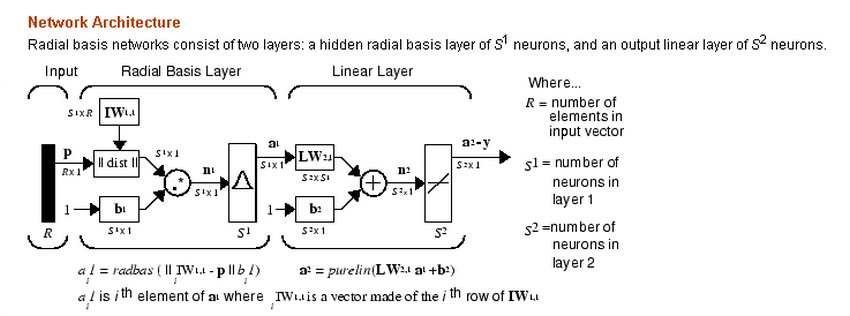

x->表示向量
1.这个形式的神经网络不需要训练,
2.net模型中会保存全部训练数据即矩阵 IW中,新输入的样本p-> 会跟IW矩阵中的每个样本计算距离, radbas(||dist||.* b->)后 形成a-> 所以向量a->的元素个数等于训练样本的个数
LW矩阵 的元素个数是 S2XS1, S2是输出个数,如果是1的情况下,LW的列数 就是S1即 a-> 向量的元素个数 , 输出这里直接是做了线性回归。
所以根据这个模型可以看出 newrbe是不需要训练,直接用的,同时看车训练样本需要全面,当然会占用比较大空间


function [w1,b1,w2,b2] = designrbe(p,t,spread) [r,q] = size(p); [s2,q] = size(t); w1 = p'; b1 = ones(q,1)*sqrt(-log(.5))/spread; a1 = radbas(dist(w1,p).*(b1*ones(1,q))); x = t/[a1; ones(1,q)]; w2 = x(:,1:q); b2 = x(:,q+1); end
创建代码,里面的a1是训练数据两两之间的距离矩阵--取radbas后的
然后x=t/[a1;ones(1,q)] 直接做矩阵除法(ones(1,q) 对应b参数),所以需要保证[a1;ones(1,q))是可逆的,
如果输入一个训练样本,结果必定是完全对上的,因为上面的是精确解---矩阵直接除